Time Series는 시간 순서에 따라 측정된 데이터의 시퀀스를 나타낸다. 일정한 간격으로 측정된 데이터일 수도 있고, 불규칙한 간격으로 측정된 데이터일 수도 있다. 주식 시장의 주가, 기상 데이터, 경제 지표, 센서 데이터 등 다양한 분야에서 사용되며 Time Series 데이터를 분석하고 예측하는 것은 시계열 분석의 중요한 영역 중 하나이다.
Q62. 데이터를 로드하고 각 열의 데이터 타입 파악하기
import pandas as pd
DriveUrl = 'https://drive.google.com/'
df = pd.read_csv(DriveUrl)
df.info()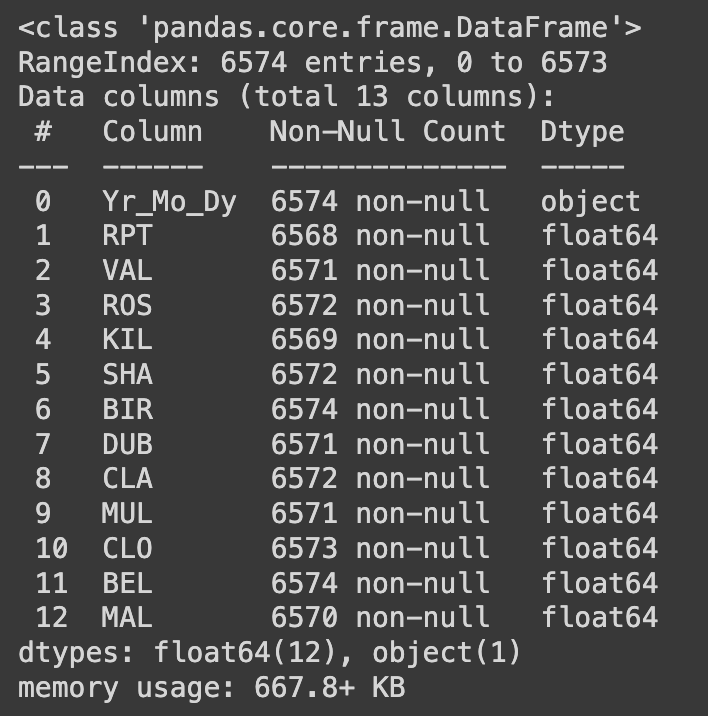
df.info()메서드는 DataFrame의 각 열에 대한 요약 정보를 제공한다. 주요한 정보로는 각 열의 데이터 타입, 비어 있지 않은 값(결측치가 아닌 값)의 개수, 메모리 사용량 등이 포함된다. 이 메서드를 호출하면 DataFrame의 구조와 데이터에 대한 전반적인 이해를 돕는다.
Q63. Yr_Mo_Dy을 pandas에서 인식할 수 있는 datetime64타입으로 변경하기
df.Yr_Mo_Dy = pd.to_datetime(df.Yr_Mo_Dy)
Ans = df.Yr_Mo_Dy
Ans.head()
# 결과값:
# 0 2061-01-01
# 1 2061-01-02
# 2 2061-01-03
# 3 2061-01-04
# 4 2061-01-05
# Name: Yr_Mo_Dy, dtype: datetime64[ns]
to_datetime()메서드를 사용하면 날짜 및 시간 정보를 포함하는 열을 datetime64 데이터 타입으로 변환할 수 있다. 이를 통해 시계열 데이터를 보다 쉽게 다룰 수 있게 된다.
'Yr_Mo_Dy' 컬럼의 데이터타입이 object(문자형)에서 datetime64(시계형) 타입으로 잘 바뀌었는지 다음과 같이 확인해볼 수 있다.
Ans.info()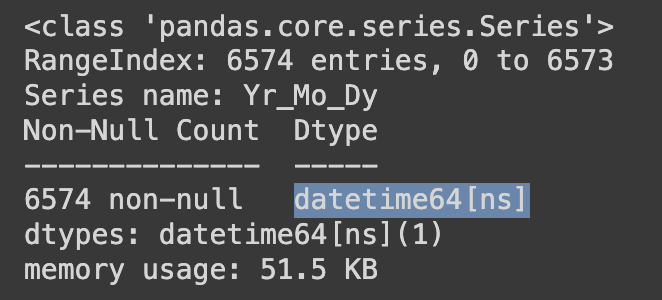
Q64. Yr_Mo_Dy에 존재하는 년도의 유일값을 모두 출력하기
# 데이터프레임의 Yr_Mo_Dy 열에서 연도 정보만을 추출하여 유일한 값만을 출력
Ans = df.Yr_Mo_Dy.dt.year.unique()
Ans
# 결과값:
# array([2061, 2062, 2063, 2064, 2065, 2066, 2067, 2068, 2069, 2070, 2071,
# 1972, 1973, 1974, 1975, 1976, 1977, 1978])
dt.year명령어는 'Yr_Mo_Dy' 열에서 자동적으로 연도(year) 정보만을 추출한다.dt.month명령어는 자동으로 월(month) 정보만을 추출한다.dt.day명령어는 자동으로 일(day) 정보만을 추출한다.
unique()명령어는 해당 열이 가지고 있는 고유한 값을 반환한다.nunique()명령어는 해당 열이 가지고 있는 고유한 값의 개수를 반환한다.
Q65. Yr_Mo_Dy에 년도가 2061년 이상의 경우에는 모두 잘못된 데이터이다. 해당경우의 값은 100을 빼서 새롭게 날짜를 Yr_Mo_Dy 컬럼에 정의하기
def fix_century(x):
import datetime # datetime이라고 하는 패키지 불러오기
year = x.year - 100 if x.year >= 2061 else x.year
return pd.to_datetime(datetime.date(year, x.month, x.day))
df['Yr_Mo_Dy'] = df['Yr_Mo_Dy'].apply(fix_century)
Ans = df.head(4)
Ans
# 결과값:
# array([2061, 2062, 2063, 2064, 2065, 2066, 2067, 2068, 2069, 2070, 2071,
# 1972, 1973, 1974, 1975, 1976, 1977, 1978])함수 내에서 import datetime을 사용하면 해당 함수가 호출될 때마다 자동으로 임포트가 되므로, 밖에서 따로 선언하지 않아도 된다. 이렇게 하면 코드가 더 간결해지고 함수의 독립성을 보장할 수 있다.
datetime.date(year, x.month, x.day) 부분은 주어진 년도, 월, 일로부터 새로운 datetime 객체를 생성한다. 이렇게 생성된 datetime 객체는 pd.to_datetime() 함수를 사용하여 판다스에서 인식할 수 있는 datetime64 형식으로 변경된다. 이렇게 변환된 값이 반환되어 데이터프레임에 할당되어 반환된다.
datetime.date는 datetime 모듈에서 제공하는 클래스 중 하나이다. 이 클래스를 사용하여 날짜를 생성할 수 있다.datetime.date(year, month, day)형식으로 사용되며, year, month, day는 각각 년, 월, 일을 나타낸다. 이 클래스를 사용하여 날짜를 생성하고자 할 때 사용된다.import datetime # datetime.date를 사용하여 날짜 생성 date_obj = datetime.date(2024, 4, 30) print(date_obj) # 결과: 2024-04-30 print(type(date_obj)) # 결과: <class 'datetime.date'>
정상적으로 되었는지 확인하기 위해 64번 문제처럼 Yr_Mo_Dy에 존재하는 년도의 유일값을 출력해보기
df.Yr_Mo_Dy.dt.year.unique()
# 결과값:
# array([2061, 2062, 2063, 2064, 2065, 2066, 2067, 2068, 2069, 2070, 2071,
# 1972, 1973, 1974, 1975, 1976, 1977, 1978])Q66. 년도별 각컬럼의 평균값 구하기
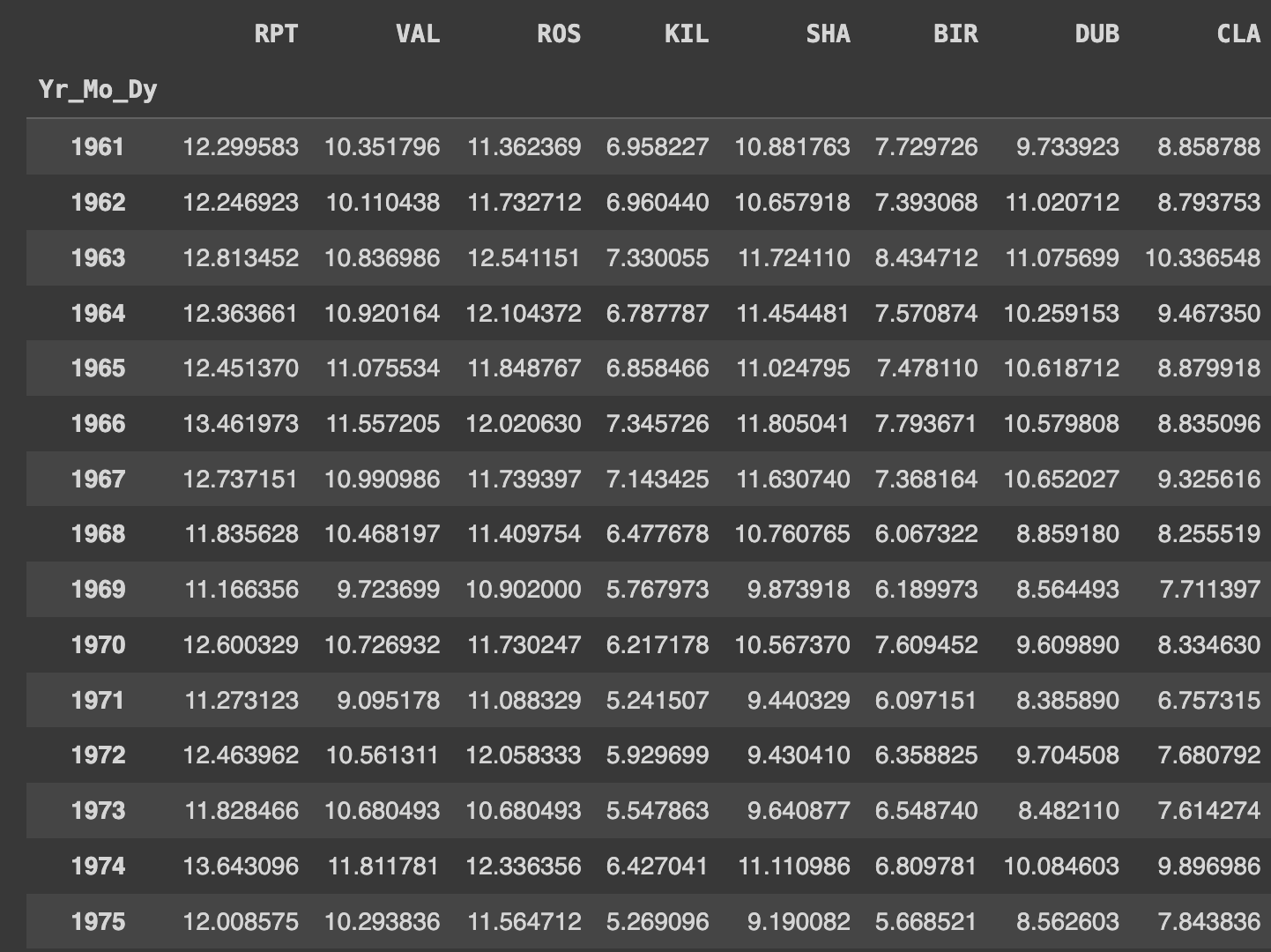
# 'Yr_Mo_Dy' 열의 연도별로 그룹화한 후에 각 그룹에 대해 숫자형 열의 평균을 계산
Ans = df.groupby(df.Yr_Mo_Dy.dt.year).mean(numeric_only=True)
Ansnumberic_only=True 옵션은 숫자형 데이터만 고려하겠다는 의미이다.
Q67. weekday컬럼을 만들고 요일별로 매핑하기 (월요일: 0 ~ 일요일 :6)
# 'Yr_Mo_Dy' 열에서 요일을 추출하여 'weekday'라는 새로운 열을 생성
df['weekday'] = df.Yr_Mo_Dy.dt.weekday
# 첫 3개 행의 요일 정보를 데이터프레임 형태로 출력
Ans = df['weekday'].head(3).to_frame()
Ans
# 결과값:
# 0 6
# 1 0
# 2 1
dt.weekday명령어는 날짜의 요일을 숫자 형태로 반환한다. 이때, 월요일부터 일요일까지 0부터 6까지의 숫자가 할당된다.0은월요일을 나타내고,1은화요일, ...,6은일요일을 나타낸다.
Q68. weekday 컬럼을 기준으로 주말이면 1 평일이면 0의 값을 가지는 WeekCheck 컬럼 만들기
주말은 토요일과 일요일을 말한다. 따라서 67번 문제를 통해서 weekday 명령어를 사용했을 때 토요일은 5, 일요일은 6이다.
# weekday 열에서 요일을 나타내는 숫자를 기준으로, 토요일(5) 또는 일요일(6)인 경우에는 1로 표시하고, 그렇지 않은 경우에는 0으로 표시하는 새로운 열 WeekCheck을 생성
df['WeekCheck'] = df['weekday'].map(lambda x : 1 if x in [5,6] else 0)
Ans = df[['weekday', 'WeekCheck']]
Ans.head()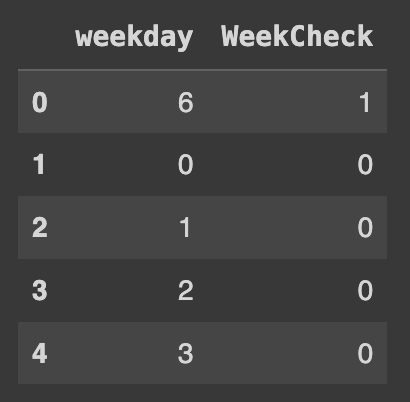
Q69. 년도, 일자 상관없이 모든 컬럼의 각 달의 평균 구하기
# 'Yr_Mo_Dy' 열의 월을 기준으로 그룹화하고, 그룹화된 각 월에 대해 숫자 타입의 데이터만을 고려하여 평균 계산
Ans = df.groupby(df.Yr_Mo_Dy.dt.month).mean(numeric_only=True)
Ans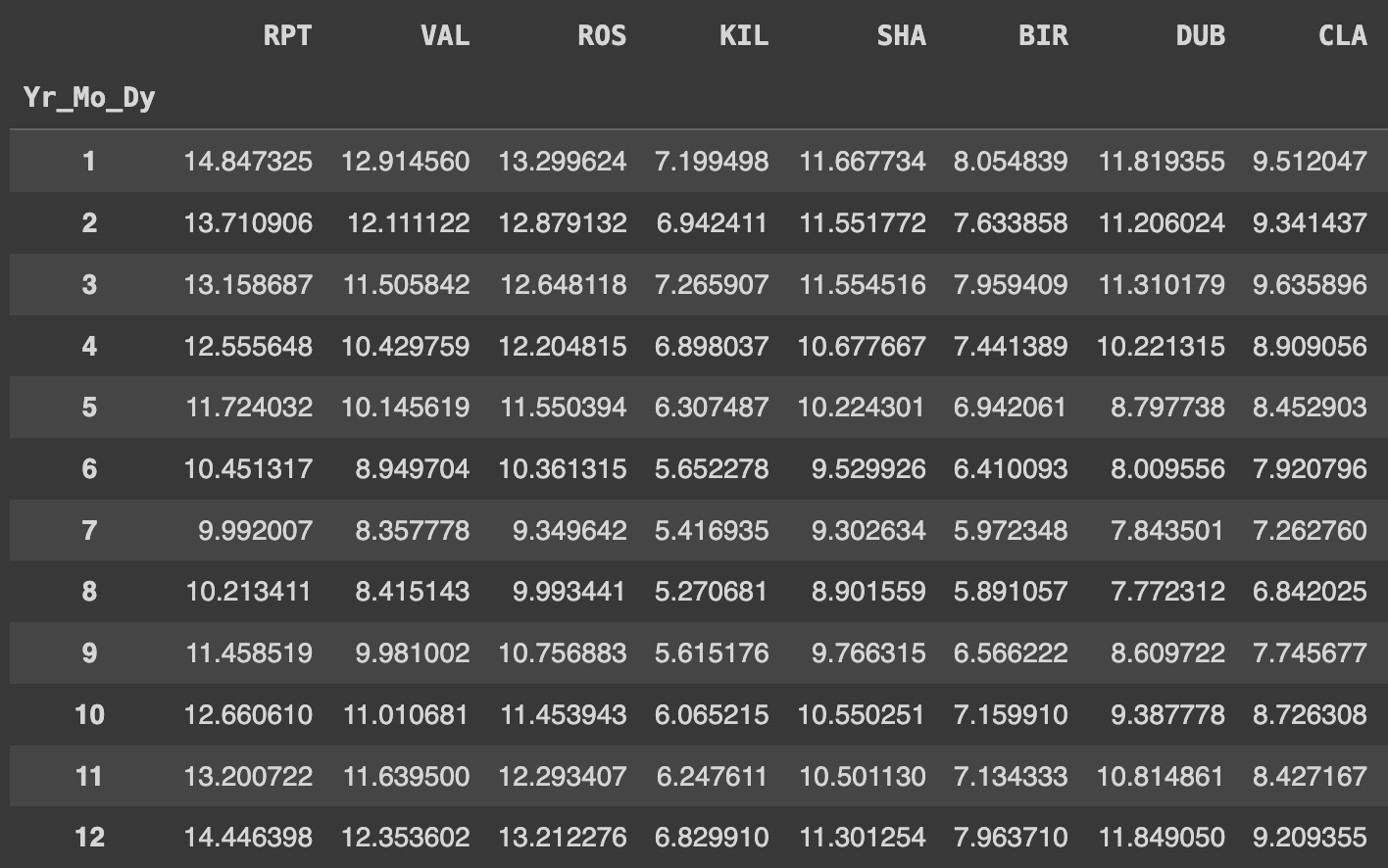
Q70. 모든 결측치는 컬럼기준 직전의 값으로 대체하고 첫번째 행에 결측치가 있을경우 뒤에있는 값으로 대체하기
df.isnull().sum()
# 결과값:
# Yr_Mo_Dy 0
# RPT 6
# VAL 3
# ROS 2
# KIL 5
# SHA 2
# BIR 0
# DUB 3
# CLA 2
# MUL 3
# CLO 1
# BEL 0
# MAL 4
# dype: int64
df.isnull().sum()은 DataFrame의 각 열에 대해 결측값의 개수를 계산한다. 결과는 각 열에 대해 결측값의 개수를 포함하는 Series로 반환한다.
위의 코드를 사용하여 현재 가지고 있는 데이터를 봤더니 NULL 값이 존재하는 컬럼들이 보인다. 따라서 존재하는 NULL 값들을 처리하려고 한다.
# 먼저 누락된 값을 앞 방향으로(ffill) 채우고, 그 다음 뒷 방향으로(bfill) 채우기
df = df.fillna(method='ffill').fillna(method='bfill')
df.isnull().sum()
# 결과값:
# Yr_Mo_Dy 0
# RPT 0
# VAL 0
# ROS 0
# KIL 0
# SHA 0
# BIR 0
# DUB 0
# CLA 0
# MUL 0
# CLO 0
# BEL 0
# MAL 0
# dype: int64
fillna명령어는 결측치(빈 값)를 채우는 데 사용된다.- 여기서
method='ffill'은 forward fill의 약자로 앞의 유효한 값으로 결측치를 채우겠다는 의미이다.- 마찬가지로
method='bfill'은 backward fill의 약자로 뒤의 유효한 값으로 결측치를 채우겠다는 의미이다.- 이렇게 두 가지 방법을 연결하여 사용함으로써 데이터의 결측치를 처리할 수 있다.
Q71. 년도 - 월을 기준으로 모든 컬럼의 평균값 구하기
Ans = df.groupby(df.Yr_Mo_Dy.dt.to_period('M')).mean(numeric_only=True)
Ans.head(3)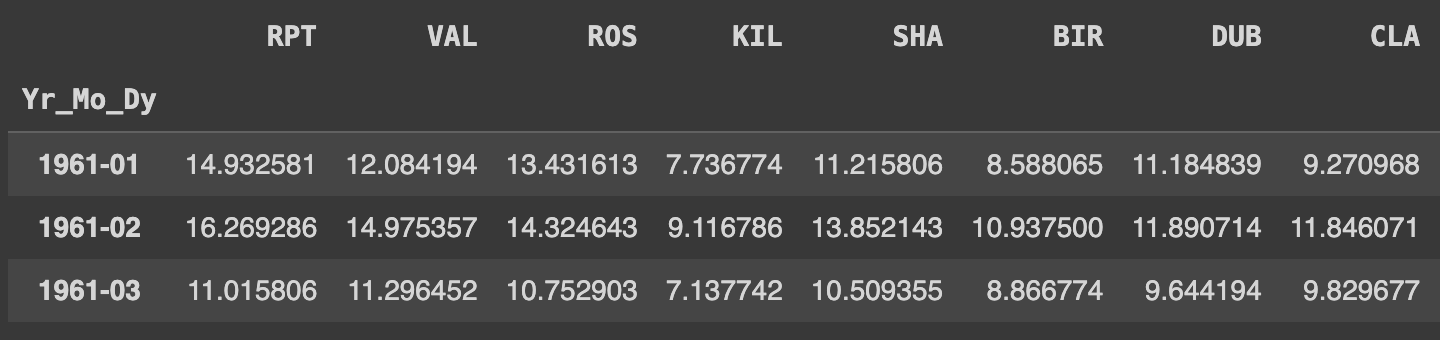
to_period('M')을 사용하면 날짜 데이터를 년도와 월을 포함한 형태로 변환할 수 있다. 이렇게 하면 월 단위의 그룹화를 더 쉽게 할 수 있다. (e.g, 2024-02)
Q72. 년도 - 월을 기준으로 모든 컬럼의 최대값 구하기
# 월별로 그룹화된 데이터에서 각 월별로 가장 큰 값을 찾아서 반환
Ans = df.groupby(df.Yr_Mo_Dy.dt.to_period('M')).max(numeric_only=True)
Ans.head()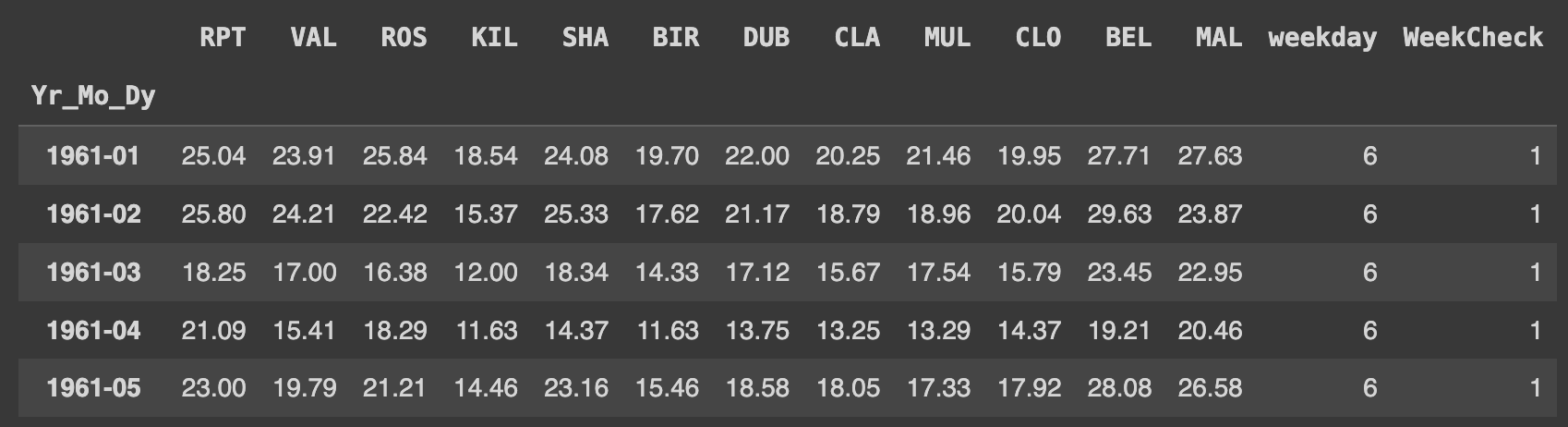
max()함수는 최댓값을 반환한다.
Q73. RPT와 VAL의 컬럼을 일주일 간격으로 각각 이동평균한값 구하기
이동평균은 주어진 기간(예: 일주일) 동안의 데이터를 기준으로 한 행씩 이동하면서 해당 기간 동안의 평균값을 계산하는 것이다.- 예를 들어, 데이터의 처음 7개 행(0부터 6번까지의 행)을 한 주의 데이터로 간주하여 평균값을 구하고, 다음 7개 행(1부터 7번까지의 행)을 다음 주의 데이터로 간주하여 평균값을 구하는 식으로 진행된다.
# 데이터프레임의 'RPT'와 'VAL' 열에 대해 7일 이동평균 계산
Ans= df[['RPT','VAL']].rolling(7).mean()
Ans.head(9)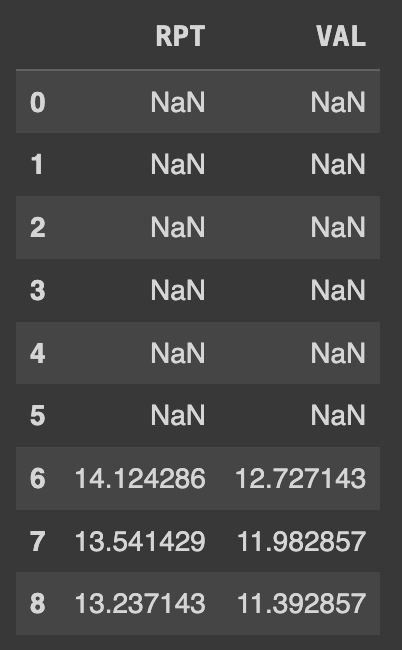
rolling()함수는 이동평균을 계산하기 위해 사용되는 함수이다. 이 함수는 시계열 데이터에서 이동하는 창을 설정하고 해당 창 내의 데이터에 대한 특정 연산을 수행한다.
- 예를 들어,
rolling(7)은 7개의 데이터(일주일)를 기준으로 이동평균을 계산한다. 일주일 동안의 데이터에 대한 평균을 구하는 것과 같다.- 처음 6개의 행은 7개의 데이터로 구성되지 않기 때문에 이동평균을 계산할 수 없어서 NULL 값으로 표시된다.
예시로, 3일을 기준으로 이동평균을 계산한다면 다음과 같이 작성하면 된다.
Ans= df[['RPT','VAL']].rolling(3).mean()
Ans.head(9)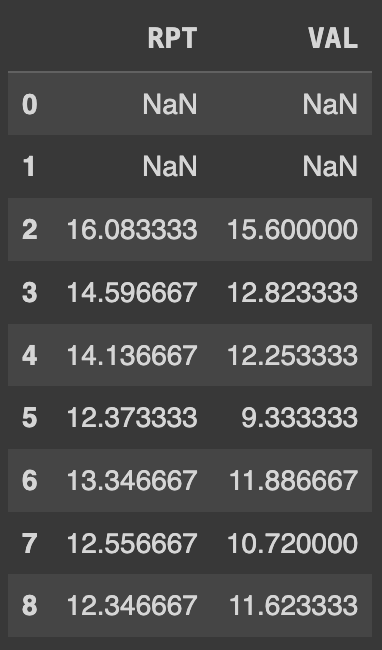
처음 2개의 행만 NULL 값으로 표시된다.
다음 예시로, 1일을 기준으로 이동평균을 계산하면 다음과 같이 작성하면 된다.
Ans= df[['RPT','VAL']].rolling(1).mean()
Ans.head(9)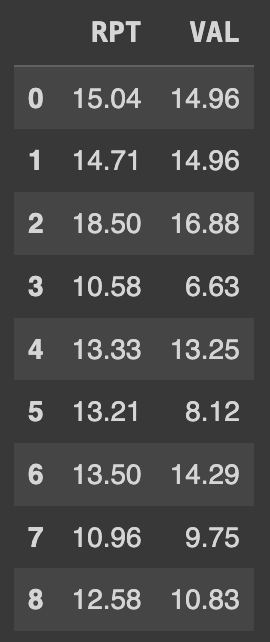
첫 행부터 마지막 행까지 모든 이동평균 값을 계산할 수 있다. 따라서 이 경우에는 NULL 값이 나타나지 않는다.
1일을 기준으로 이동평균을 계산하는 것은 해당 행 자체의 값을 구하는 것이므로 이동평균을 구하지 않아도 된다. 따라서 결과는 이동평균을 적용하지 않은 값과 동일하다.
df[['RPT','VAL']].head()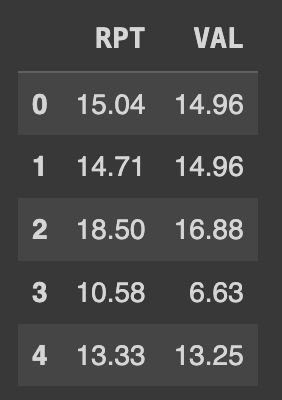
Q74. 년-월-일:시 컬럼을 pandas에서 인식할 수 있는 datetime 형태로 변경하기 (서울시의 제공데이터의 경우 0시가 24시로 표현된다.)
# '(년-월-일:시)' 열의 첫 번째 항목을 콜론(':')을 기준으로 나눈 후, 그 결과를 리스트로 반환
df['(년-월-일:시)'][0].split(':')
# 결과값: ['2021-05-15', '15']
split(':')메서드는 문자열을 주어진 구분자를 기준으로 나누어 리스트로 반환한다.
- 예를 들어, (년-월-일:시) 열의 첫 번째 항목이 '2024-02-22:15' 라면, split(':') 메서드를 적용하면 ['2024-02-22', '15']와 같은 리스트가 반환된다. 첫 번째 요소는 날짜를 나타내는 문자열 '2021-05-15'이고, 두 번째 요소는 시를 나타내는 문자열 '15'이다.
def change_date(x):
import datetime
hour = x.split(':')[1] # 첫번째 값은 hour
date = x.split(":")[0] # 두번째 값은 date
if hour =='24':
hour ='00:00:00'
FinalDate = pd.to_datetime(date +" "+hour) + datetime.timedelta(days=1) # 24시가 넘어가면 하루를 플러스
else:
hour = hour +':00:00'
FinalDate = pd.to_datetime(date +" "+hour) # 24시를 안넘으면 시간을 그대로 두기
return FinalDate
df['(년-월-일:시)'] = df['(년-월-일:시)'].apply(change_date)
Ans = df
Ans.head()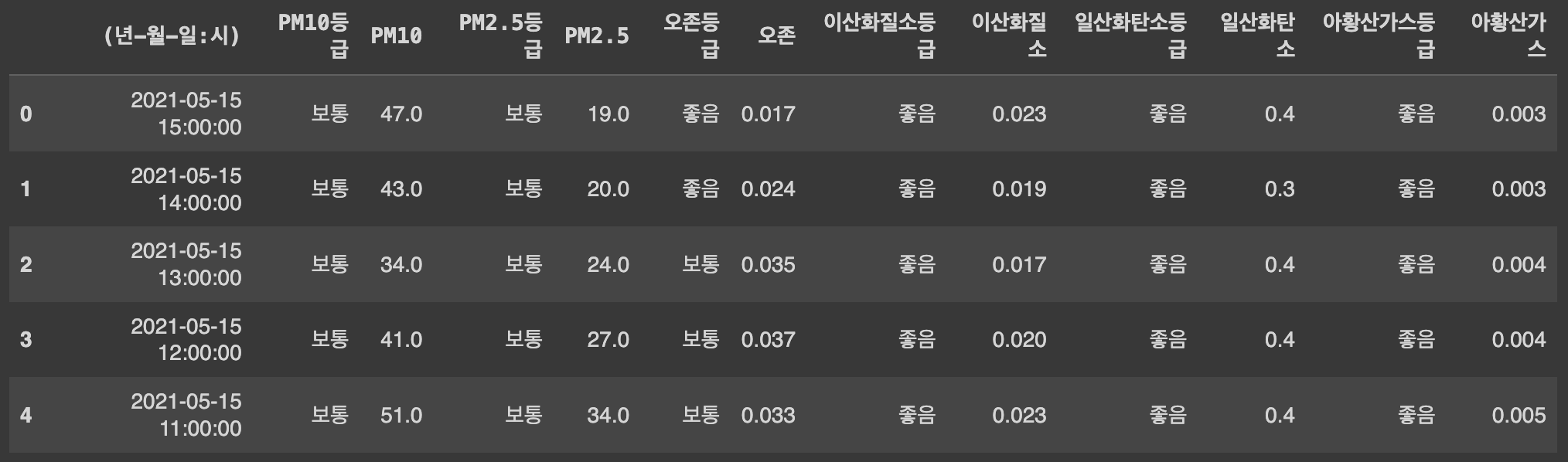
datetime.timedelta()함수는 날짜와 시간의 간격을 나타내는 데 사용된다.timedelta(days=0, seconds=0, minutes=0, hours=0, weeks=0)위의 매개변수들은 timedelta 객체를 생성하는 데 사용된다. 이들을 조합하여 원하는 시간 간격을 정의할 수 있다. 이 때, 각 매개변수는 선택적으로 사용될 수 있으며, 기본값은 모두 0이다.
days: 일(day) 단위의 시간 간격을 정의한다.seconds: 초(second) 단위의 시간 간격을 정의한다.minutes: 분(minute) 단위의 시간 간격을 정의한다.hours: 시(hour) 단위의 시간 간격을 정의한다.weeks: 주(week) 단위의 시간 간격을 정의한다.
timedelta(days=1)은 일(day) 단위의 시간 간격을 정의하며, 즉 하루 동안의 시간 간격을 나타낸다.
- 예를 들어, 현재 날짜가 2024년 2월 17일이라고 가정하면, timedelta(days=1)을 사용하여 이 날짜에 하루를 더하면 2024년 2월 18일이 된다.
Ans.sort_values('(년-월-일:시)').head(24)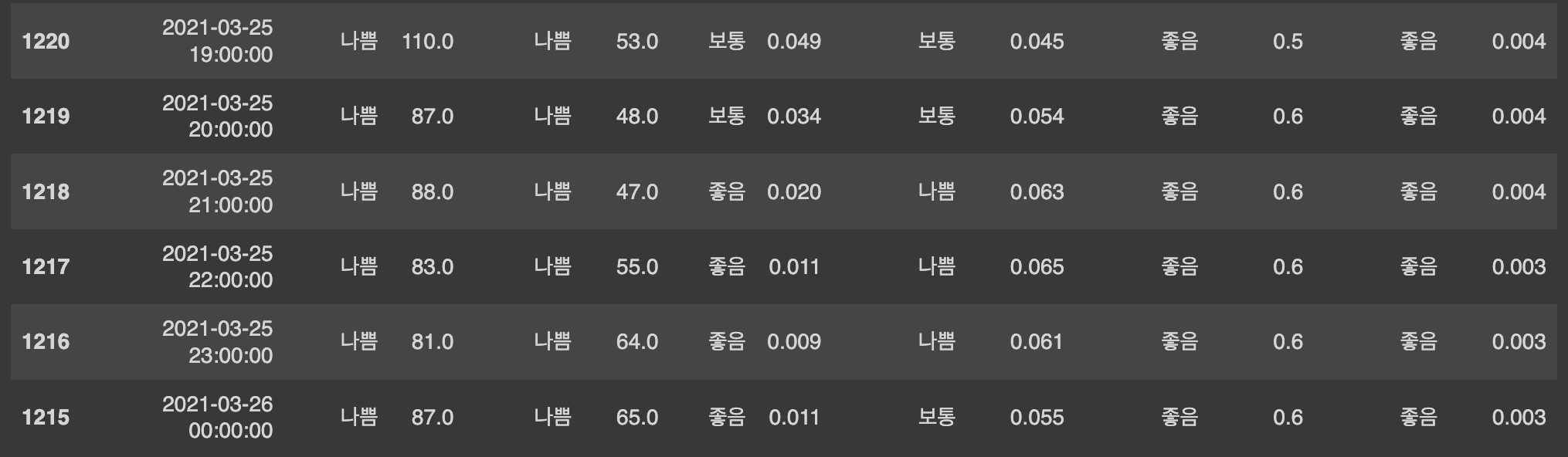
1215번 index의 '년-월-일:시' 열 값이 '2021-03-26'으로 하루 더해진걸 확인할 수 있다.
Q75. 일자별 영어요일 이름을 dayName 컬럼에 저장하기
df['dayName'] = df['(년-월-일:시)'].dt.day_name()
Ans = df['dayName']
Ans.head()
# 결과값:
# 0 Saturday
# 1 Saturday
# 2 Saturday
# 3 Saturday
# 4 Saturday
# Name: daytime, Length: 1239, dtype: object
dt.day_name()메서드는 날짜가 포함된 시계열 데이터의 각 날짜를 해당하는 요일의 이름으로 변경된다. 이를 통해 날짜가 포함된 열을 기반으로 각 날짜가 어떤 요일인지 확인할 수 있다. (예: Monday, Tuesday 등)
Q76. 요일별 각 PM10등급의 빈도수 파악하기
# 데이터프레임을 'dayName' 및 'PM10등급'으로 그룹화하고 각 그룹의 크기를 계산
Ans1 = df.groupby(['dayName','PM10등급'], as_index=False).size()
# Ans1의 결과를 'dayName'을 행 인덱스로, 'PM10등급'을 열 이름으로 하여 피벗, 결측치는 0으로 채우기
Ans2 = Ans1.pivot(index='dayName', columns='PM10등급', values='size').fillna(0)Ans1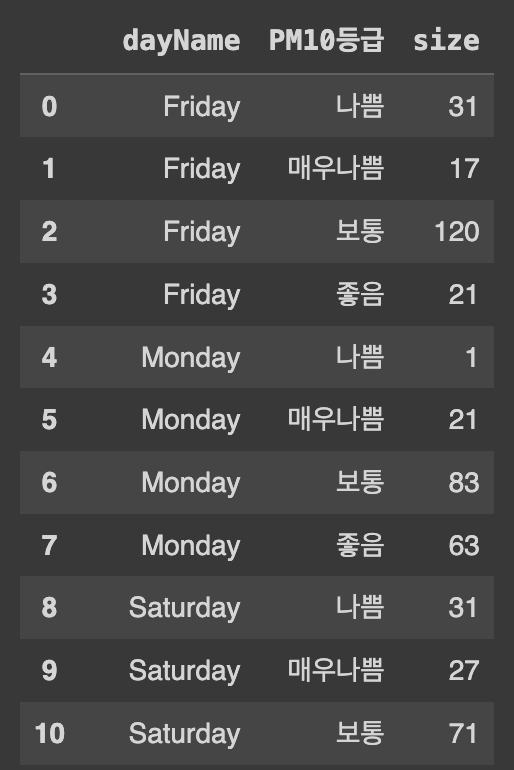
Ans2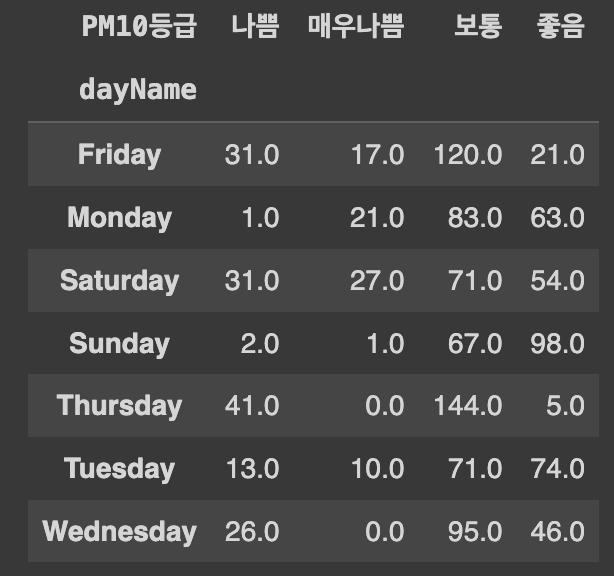
pivot()함수는 데이터프레임의 형태를 변경할 때 사용된다. 이 함수를 사용하면 데이터프레임의 행과 열을 재구성하여 새로운 형태의 데이터프레임을 만들 수 있다.
Q77. 시간이 연속적으로 존재하며 결측치가 없는지 확인하라
시간이 연속적으로 존재한다는 것은 데이터에 결측값이 없으며, 연속적인 시간대가 모두 포함되어 있음을 의미한다. 즉, 데이터셋에는 시간적 간격이 없이 연속된 시간대가 포함되어 있어야 한다. 예를 들어, 데이터셋에서 3월 1일 한시부터 24시까지의 모든 시간대가 포함되어 있는걸 말한다.
df['(년-월-일:시)'].diff().unique()
# 결과값:
# array([ 'NaT', -3600000000000], dtype='timedelta64[ns]')# 시간을 차분했을 경우 첫 값은 nan, 이후 모든 차분값이 동일하면 연속이라 판단한다.
check = len(df['(년-월-일:시)'].diff().unique())
if check ==2:
Ans =True
else:
Ans = False
diff()함수는 데이터프레임의 시간열 데이터에서 각 값 간의 차이를 계산한다. 이를 통해 각 시간 간격의 길이를 확인할 수 있다. 이전 값과의 차이를 계산하므로 첫 번째 값은 결측치가 된다.
예를 들어, 시계열 데이터가 일별로 기록되어 있다면diff()함수를 사용하면 각 날짜 간의 일수 차이를 계산할 수 있다.
Q78. 오전 10시와 오후 10시(22시)의 PM10의 평균값을 각각 구하기
1)
# '년-월-일:시' 열을 기준으로 데이터프레임을 그룹화하고, 그룹별로 시간(hour)을 추출하여 해당 시간에 대한 평균 값 계산
df.groupby(df['(년-월-일:시)'].dt.hour).mean(numeric_only=True)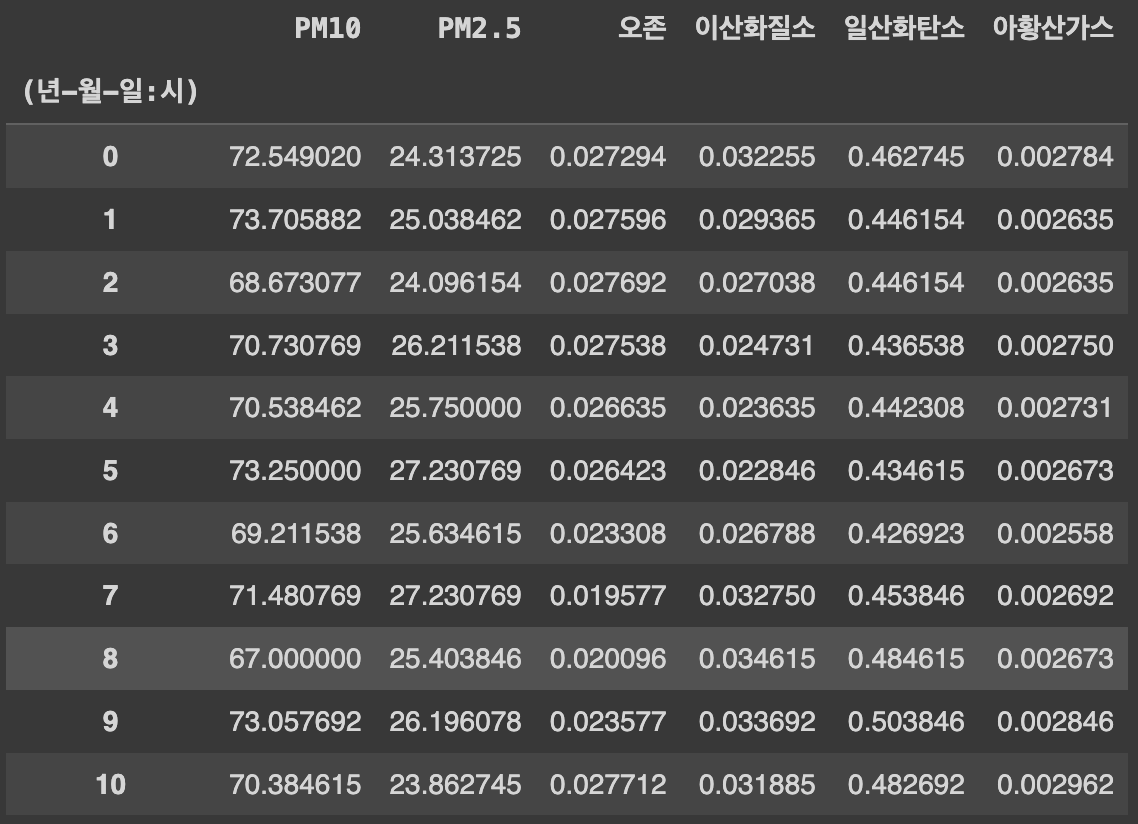
2)
# '년-월-일:시' 열을 기준으로 데이터프레임을 그룹화하고, 그룹별로 시간(hour)을 추출하여 해당 시간에 대한 평균 값을 계산, 그룹별로 계산된 평균 값 중에서 숫자형 데이터만을 선택한 후, 특정 시간대(10시와 22시)의 평균 값을 추출하여 반환
Ans = df.groupby(df['(년-월-일:시)'].dt.hour).mean(numeric_only=True).iloc[[10,22],[0]]
Ans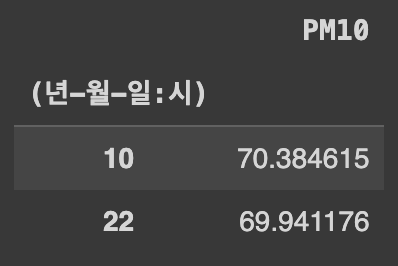
iloc[[10, 22], [0]]는 10번째와 22번째 행에서 첫 번째 열의 값을 선택하는 것을 의미한다. 따라서 결과로는 10시와 22시의 첫 번째 열에 해당하는 값만을 반환한다.
Q79. 날짜 컬럼을 index로 만들기
df.set_index('(년-월-일:시)', inplace=True)
Ans = df
Ans.head()
df.set_index()명령어는 데이터프레임의 인덱스를 지정된 열로 설정한다.
inplace=True옵션을 사용하면 원본 데이터프레임에 변경 사항을 즉시 적용한다.
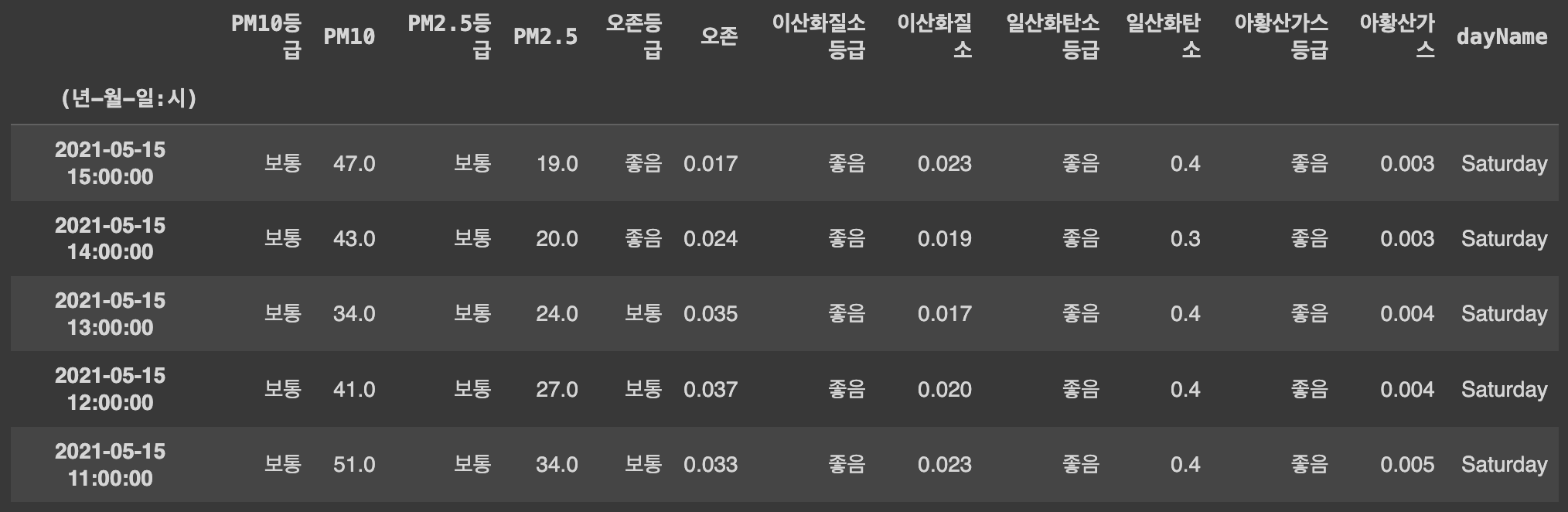
df.set_index('(년-월-일:시)', inplace=True) 명령어를 실행하면 DataFrame의 index를 '(년-월-일:시)' 컬럼으로 변경한다. 이렇게 하면 DataFrame의 인덱스가 날짜 형식으로 변경된다.
