1. 데이터프레임에 함수 적용
int('-')
# 에러: ValueError: invalid literal for int() with base 10: '-'대시(-)는 정수로 변환할 수 없는 문자열이다. 따라서 int('-')와 같은 연산은 위와 같이 ValueError를 발생시킨다.
해야 할 일:
1) 숫자로 이루어진 문자열 (예: '137060') ➞ 형변환을 해준다 (결과: 137060)
2) 문자 ('-') ➞ 문자 '0'으로 바꾼 후 정수 0으로 바꾼다 (결과: 0)
3) 정수 (예: 137060) ➞ 그대로 둔다 (결과: 137060)
def strtoint(x):
if type(x) == str:
x = x.replace("-", "0")
x = int(x)
else:
pass
return xresult["거래액"]
# 결과값:
# 0 7310479
# 1 4712488
# 2 2597990
# 3 422384
# 4 350585
# ...
# 6001 133405
# 6002 36863
# 6003 276436
# 6004 251654
# 6005 24781
# Name: 거래액, Length: 6006, dtype: objectresult["거래액"].apply(strtoint)
# 결과값:
# 0 7310479
# 1 4712488
# 2 2597990
# 3 422384
# 4 350585
# ...
# 6001 133405
# 6002 36863
# 6003 276436
# 6004 251654
# 6005 24781
# Name: 거래액, Length: 6006, dtype: int64strtoint 함수가 "거래액" 열의 데이터를 문자열에서 숫자열 형태로 변환한 것을 위와 같이 확인할 수 있다.

하지만 한가지 유의할 점은 원본 데이터에 변환한 값을 반영하기 위해서는 다음과 같이 "거래액" 변수에 바꾼 값을 지정해주어야 한다.
result["거래액"] = result["거래액"].apply(strtoint)
result.into()
# 결과값:
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 6006 entries, 0 to 6005
# Data columns (total 5 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 상품군별(1) 6006 non-null object
# 1 상품군별(2) 6006 non-null object
# 2 운영형태별(1) 6006 non-null object
# 3 날짜 6006 non-null object
# 4 거래액 6006 non-null int64
# dtypes: int64(1), object(4)
# memory usage: 234.7+ KB이렇게 하면 변환한 값이 "거래액" 열에 반영되어 원본 데이터가 수정되며 이제 pivot table로 데이터를 변환할 수 있는 모든 준비를 마쳤다.
2. Pivot Table
result.pivot_table(index = ['상품군별(1)', '상품군별(2)'])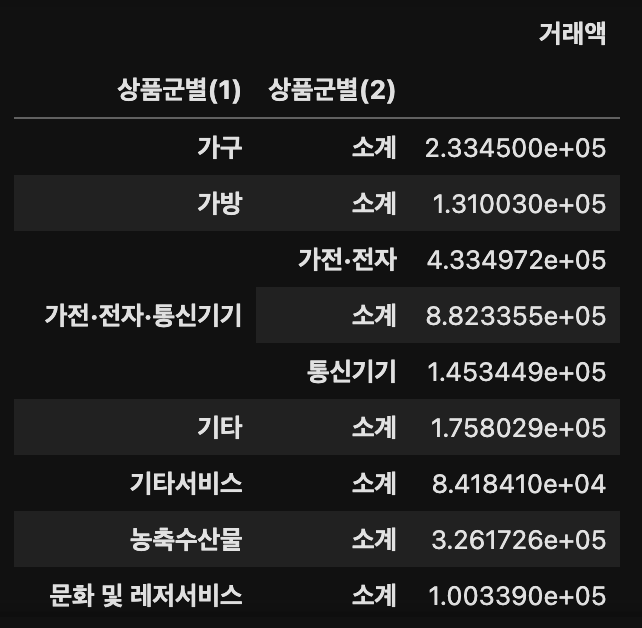
위의 이미지를 보면 거래액의 단위가 크기 때문에 판단이 어렵지만 판다스에서의 pivot table은 기본적 집계 방식으로 평균이 사용되지만, 집계 함수를 변경하여 다른 방식으로 집계할 수 있다.
result.pivot_table(index = ['운영형태별(1)'], aggfunc = 'sum')
3. 데이터 재구조화
앞서 데이터셋 소개할때의 문제점을 해결해야한다.
전에 언급한 문제점은 다음과 같다.
1) 이미 집계가 완료된 형태
2) 중간 집계값 존재
3) 가전, 전자, 통신기기 카테고리 세분화
4) 날짜 컬럼 양식 불일치
우선 2번 문제점(중간 집계값 존재)에 대해서 해결해보도록 하자.
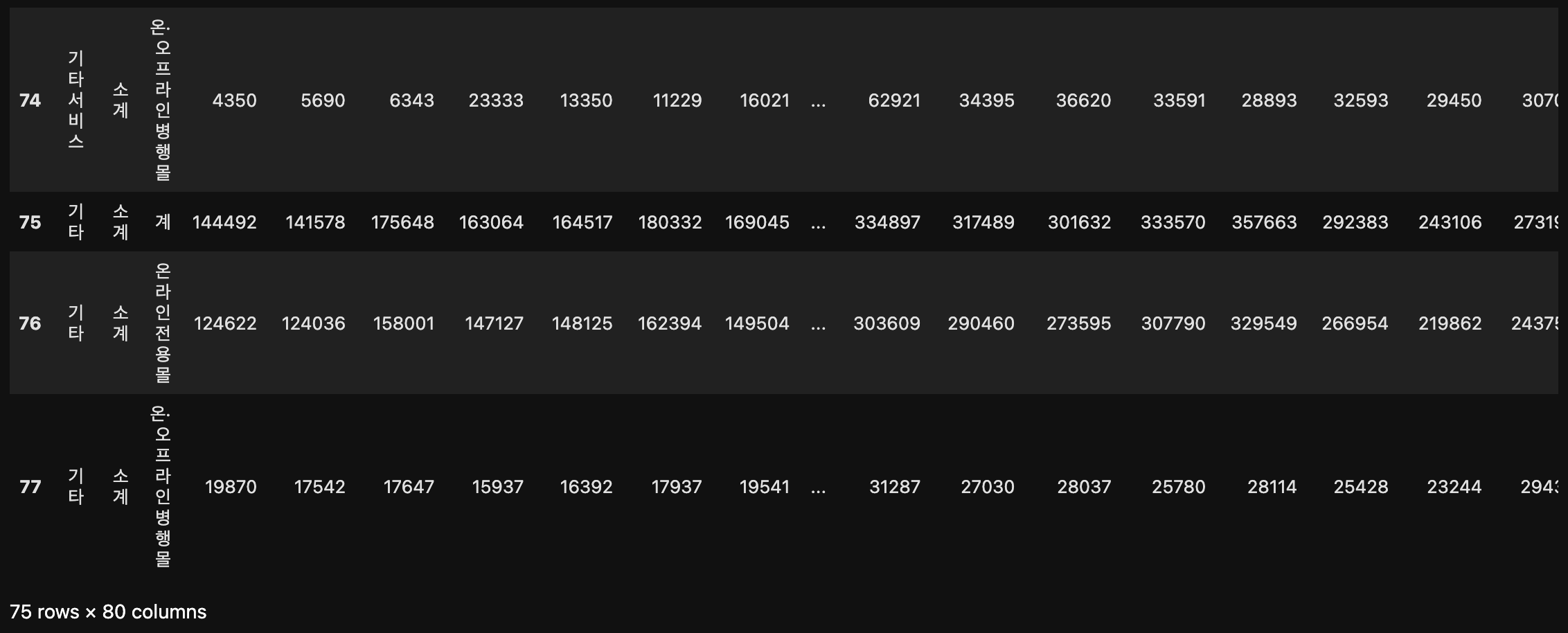
df[df["상품군별(1)"] == "합계"]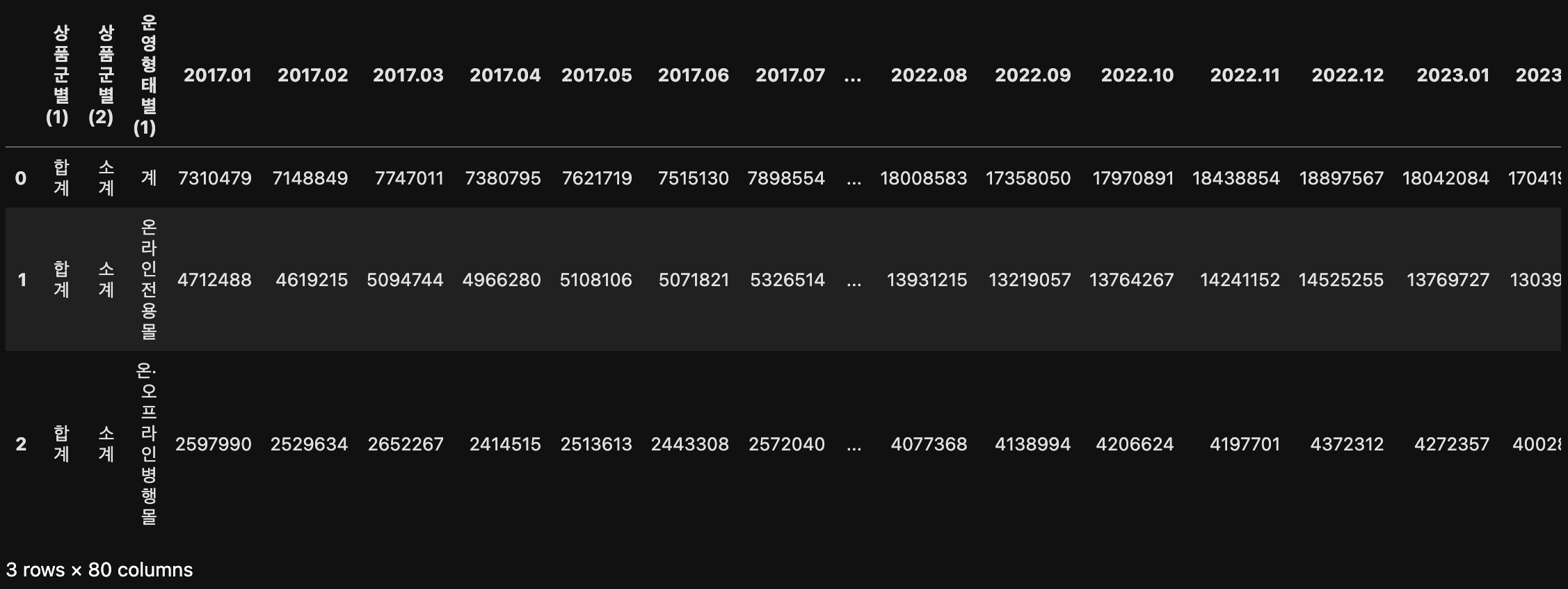
'상품군별(1)' 열의 합계만 걸러서 보여주는 것을 확인할 수 있다.
df[df["상품군별(1)"] != "합계"]== 대신 `!=₩를 넣으면 '상품군별(1)' 열의 합계가 아닌 값들만 아래와 같이 보여준다.
result 데이터프레임으로 바꾸면 다음과 같이 합계가 없는 것을 확인할 수 있다.
result[result["상품군별(1)"] != "합계"]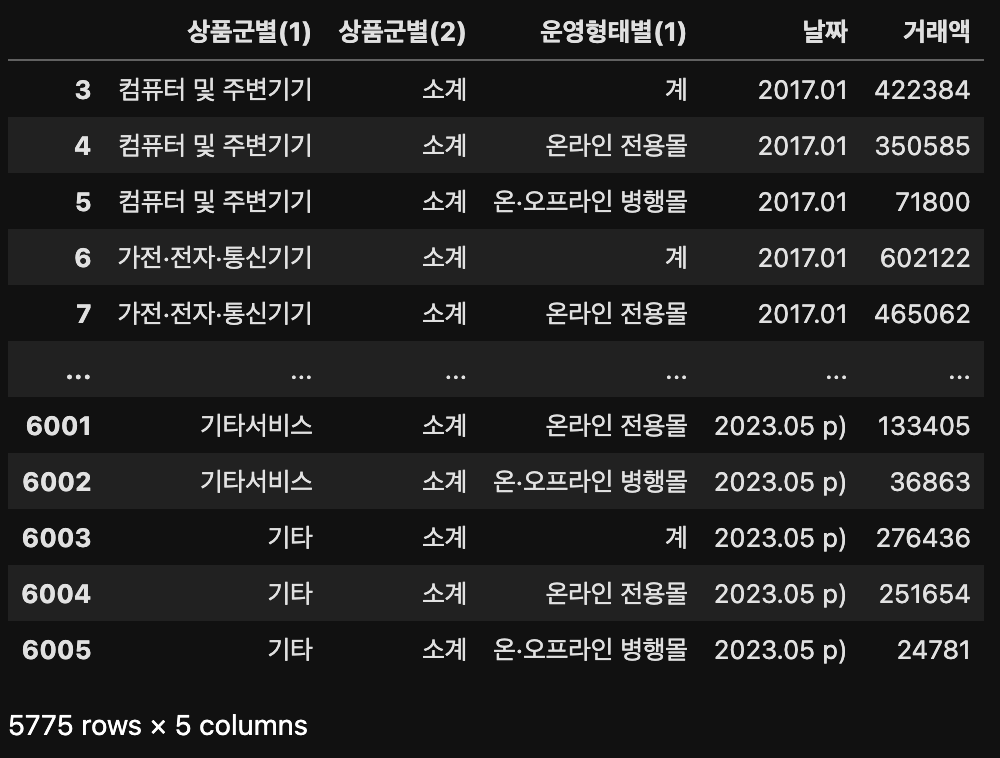
따라서 '상품군별(1)'에서 합계를 제외한 데이터를 result 변수에 지정하면된다.
result = result[result["상품군별(1)"] != "합계"]result["상품군별(1)"].unique()
# 결과값:
# array(['컴퓨터 및 주변기기', '가전·전자·통신기기', '서적', '사무·문구', '의복', '신발', '가방',
# '패션용품 및 액세서리', '스포츠·레저용품', '화장품', '아동·유아용품', '음·식료품', '농축수산물',
# '생활용품', '자동차 및 자동차용품', '가구', '애완용품', '여행 및 교통서비스', '문화 및 레저서비스',
# '이쿠폰서비스', '음식서비스', '기타서비스', '기타'], dtype=object)'상품군별(1)' 열의 unique한 값을 보니 첫번째에 쓰여있던 '합계' 행이 정상적으로 제외된 것을 확인할 수 있다.
result["운영형태별(1)"].unique()
# 결과: array(['계', '온라인 전용몰', '온·오프라인 병행몰'], dtype=object)result.head()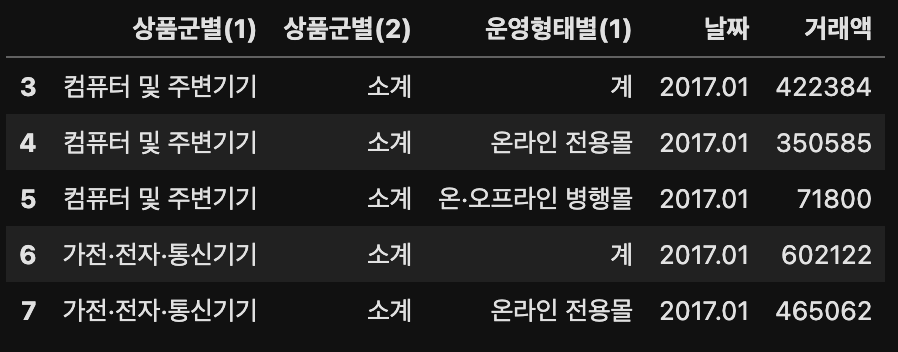
'운영형태별(1)' 열에는 (온라인 전용몰 + 온/오프라인 병행몰)을 합친 계가 있는 것을 확인할 수 있다. 중복된 값이기 때문에 제거하기로 한다.
result[result["운영형태별(1)"] != "계"]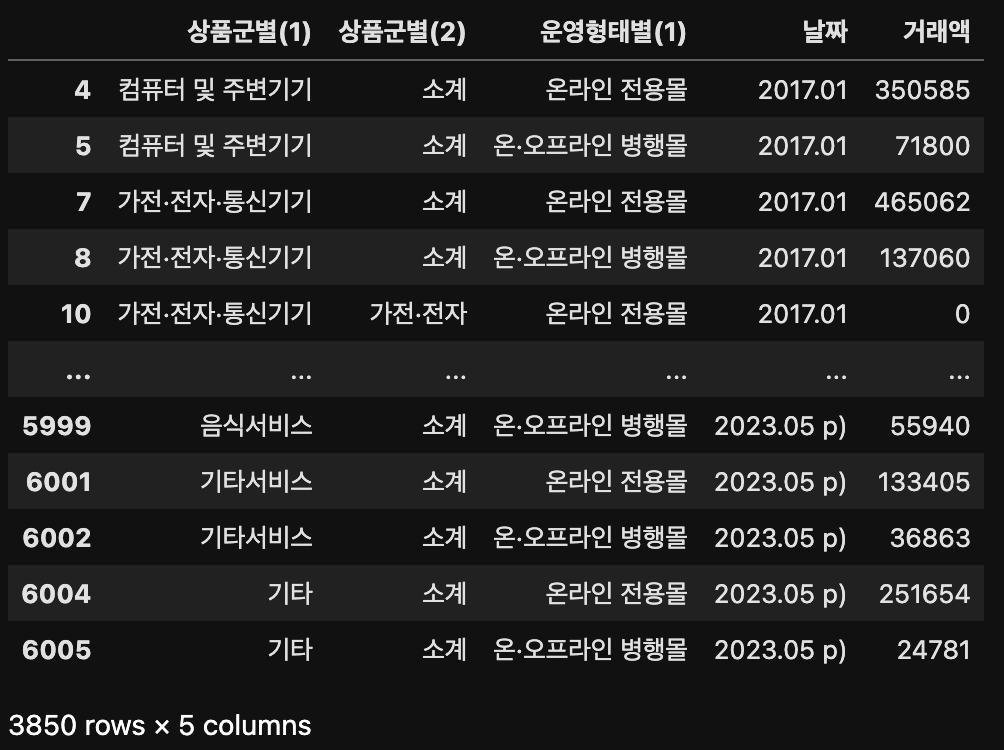
'운영형태별(1)' 열에서 '계' 가 제외된 것을 확인할 수 있다. 따라서 result라는 변수에 지정해주기로 한다.
result["운영형태별(1)"].unique()
# 결과: array(['온라인 전용몰', '온·오프라인 병행몰'], dtype=object)'운영형태별(1)' 열의 유니크한 값을 확인하면 '계'가 없어진 것을 확인할 수 있다.
모든 중간 집계 값의 존재를 제거하였으니 3번 문제점(가전, 전자, 통신기기 카테고리 세분화)을 해결해보자.
result[result["상품군별(1)"] == "가전·전자·통신기기"]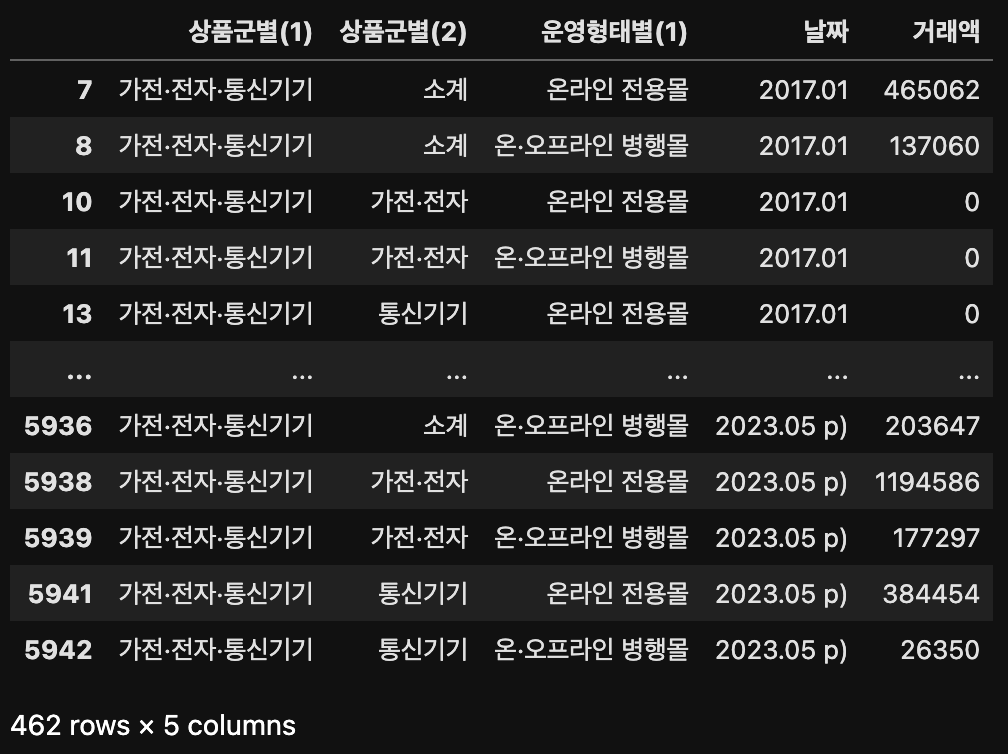
'상품군별(1)'은 소계, 가전/전자, 통신기기로 분류되어 있는 것을 확인할 수 있으며 대시(-)를 0으로 바꿨던 흔적을 발견할 수 있다.
2017년에는 가전·전자·통신기기를 분류하지 않아서 거래액이 0이지만 소계는 거래액이 잘 표기가 되어있는 것을 보아 가전/전자와 통신기기의 합이 소계이기 때문에 카테고리로 분류할 필요가 없다고 판단하여 소계만 남기고 나머지 카테고리는 제외하겠다.
result[result["상품군별(2)"] == "소계"]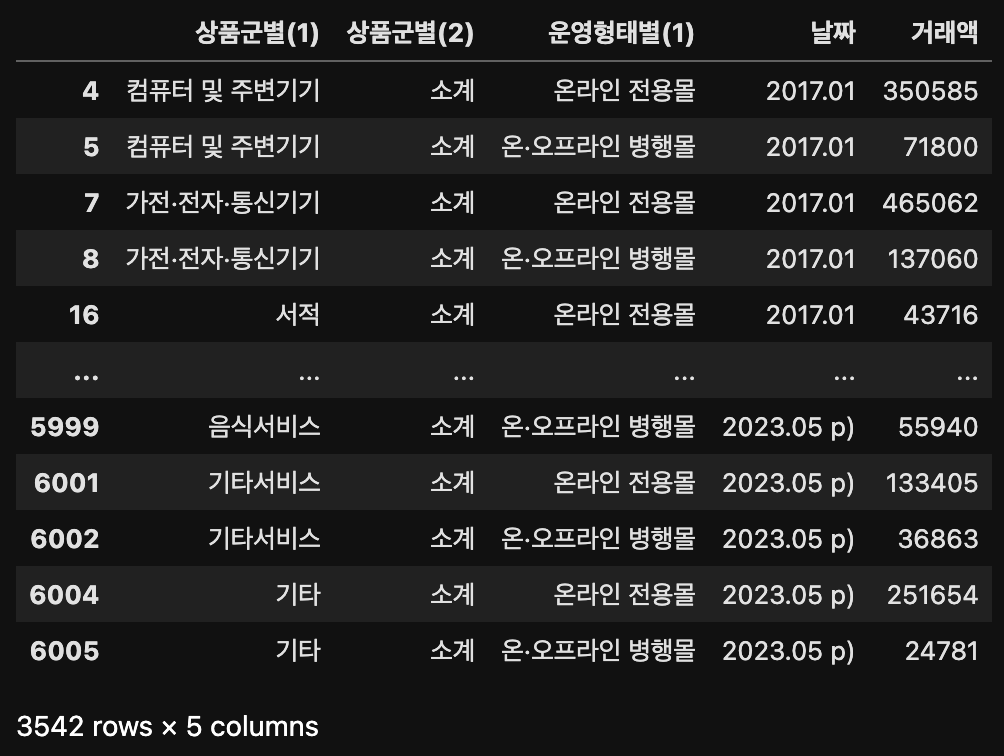
위와 같이 가전/전자, 통신기기로 나눠져있던 상품군별(2)가 소계만 있는 것을 확인할 수 있다.
따라서 원하는 값이기에 바로 result 변수에 넣어주겠다.
result = result[result["상품군별(2)"] == "소계"]result["상품군별(2)"].unique()
# 결과: array(['소계'], dtype=object)여기까지 위에서 짚었던 문제점 중 중간 집계 값과 총합이 존재 한다는 점, 가전·전자·통신기기가 두개로 세분화되어 있어서 불필요하단 점, 모든 문제를 해결하였다.
마지막으로, '상품군별(2)'에는 소계만 있다. 한가지 분류이기 때문에 불필요하기에 '상품군별(2)'를 제외하겠다.
result.drop("상품군별(2)", axis='columns')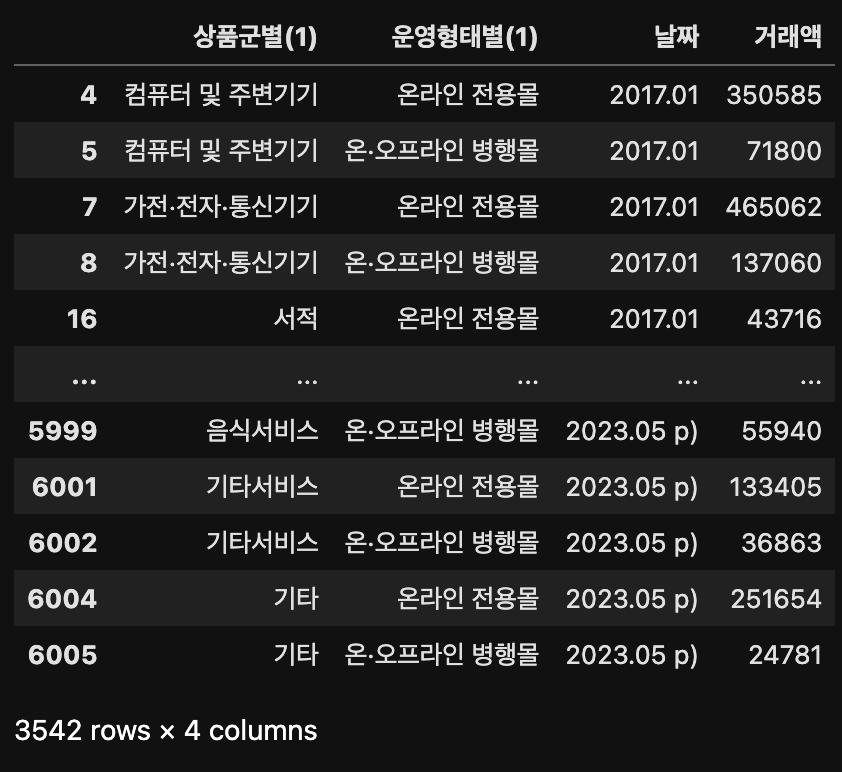
위에서는 5개의 컬럼('상품군별(1)', '상품군별(2)', '운영형태별(1)', '날짜', '거래액')이 있었는데 위의 코드를 통해 4개의 컬럼만이 존재하는 것을 확인할 수 있다.
따라서 inplace=True 옵션을 사용하여 결과값에 반영을 한다.
result.drop("상품군별(2)", axis='columns', inplace=True)
result.head()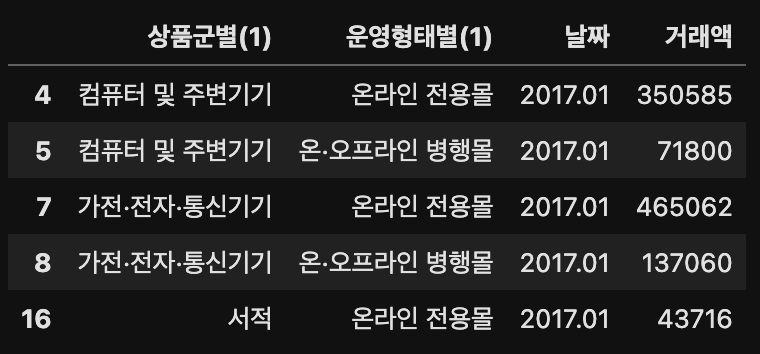
result["날짜"].unique()
# 결과값:
# array(['2017.01', '2017.02', '2017.03', '2017.04', '2017.05', '2017.06',
# '2017.07', '2017.08', '2017.09', '2017.10', '2017.11', '2017.12',
# '2018.01', '2018.02', '2018.03', '2018.04', '2018.05', '2018.06',
# '2018.07', '2018.08', '2018.09', '2018.10', '2018.11', '2018.12',
# '2019.01', '2019.02', '2019.03', '2019.04', '2019.05', '2019.06',
# '2019.07', '2019.08', '2019.09', '2019.10', '2019.11', '2019.12',
# '2020.01', '2020.02', '2020.03', '2020.04', '2020.05', '2020.06',
# '2020.07', '2020.08', '2020.09', '2020.10', '2020.11', '2020.12',
# '2021.01', '2021.02', '2021.03', '2021.04', '2021.05', '2021.06',
# '2021.07', '2021.08', '2021.09', '2021.10', '2021.11', '2021.12',
# '2022.01', '2022.02', '2022.03', '2022.04', '2022.05', '2022.06',
# '2022.07', '2022.08', '2022.09', '2022.10', '2022.11', '2022.12',
# '2023.01', '2023.02', '2023.03', '2023.04 p)', '2023.05 p)'],
# dtype=object)'날짜' 열의 유니크한 값을 확인하면 맨 마지막 두개의 날짜 값에 " p)"가 있는 것을 확인할 수 있다. 따라서 모든 날짜 값을 통일하기 위해 " p)"를 제거해주자.
" p)"를 제거하기 위해 아래와 같이 함수를 만들자.
def removep(x):
x = x.replace(" p)", "")
return xresult["날짜"].apply(removep)
# 결과값:
# 4 2017.01
# 5 2017.01
# 7 2017.01
# 8 2017.01
# 16 2017.01
# ...
# 5999 2023.05
# 6001 2023.05
# 6002 2023.05
# 6004 2023.05
# 6005 2023.05
# Name: 날짜, Length: 3542, dtype: objectremovep 함수를 적용하니 위와 같이 " p)"이 있던 맨 마지막 결과값이 정상적으로 제거된 것을 확인할 수 있다.
하지만 removep 함수는 " p)"를 제거하기 위해 3줄을 할애했다. 더 쉽게 쓸 수 있는 방법은 lambda 함수로 다음과 같이 한줄로 쓸 수 있다.
result["날짜"].apply(lambda x: x.replace(" p)", ""))
# 결과값:
# 4 2017.01
# 5 2017.01
# 7 2017.01
# 8 2017.01
# 16 2017.01
# ...
# 5999 2023.05
# 6001 2023.05
# 6002 2023.05
# 6004 2023.05
# 6005 2023.05
# Name: 날짜, Length: 3542, dtype: object위와 같이 removep 함수를 적용한 것과 lambda 함수를 적용한 것과의 결과가 동일한 것을 확인할 수 있다.
result["날짜"] = result["날짜"].apply(lambda x: x.replace(" p)", ""))
result.tail()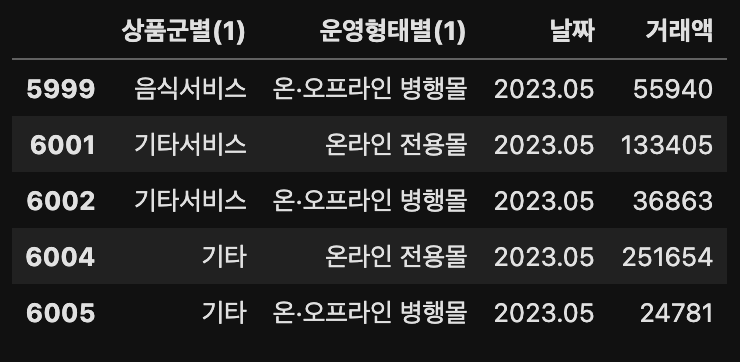
다시 result["날짜"] 변수에 넣어주고 유니크값을 확인하니 '날짜' 열의 맨 마지막 두 값에 " p)"가 제거된 것을 확인할 수 있다.
다음으로 날짜를 보면 2023.05로 되어있기에 lambda 함수를 사용하여 해당 값을 2023/05로 바꾸는 작업을 하겠다.
result["날짜"].apply(lambda x: x.replace(".", "/"))
# 결과값:
# 4 2017/01
# 5 2017/01
# 7 2017/01
# 8 2017/01
# 16 2017/01
# ...
# 5999 2023/05
# 6001 2023/05
# 6002 2023/05
# 6004 2023/05
# 6005 2023/05
# Name: 날짜, Length: 3542, dtype: objectresult["날짜"] = result["날짜"].apply(lambda x: x.replace(".", "/"))
result.head()
5. 데이터 저장하기
파일을 오픈할 때 인코딩 옵션을 주지 않아서 한글이 깨졌기에 저장할 때는 인코딩 옵션을 주어서 오픈할 때 인코딩 옵션을 안줘되 되게 하자.
result.to_csv("데이터.csv", encoding='cp949', index=False)