- 분류: Language Model
- 저자: Google
- paper: Attention Is All You Need
- 키워드: Transformer, Attention
*논문에 언급되지 않은 내용이 포함되어 있을 수 있습니다. 이는 보다 쉬운 이해를 위해서 포함되었습니다.
0. 핵심 아이디어
기존의 RNN이나 CNN 없이, Self-Attention만으로도 더 좋은 시퀀스 모델을 만들 수 있다.
1. Transformer 모델의 등장과 장점
기존 시퀀스 변환 모델의 한계
- 기존 모델은 복잡한 순환 신경망(RNN) 또는 합성곱 신경망(CNN) 기반
- 순차적 계산의 제약: RNN은 입력 시퀀스의 각 위치에 대해 순차적으로 계산으로 수행하므로 병렬 처리가 어려움
- 장거리 의존성 문제: RNN은 입력 시퀀스에서 멀리 떨어진 위치 간의 의존성을 학습하는 데 어려움을 겪음. 정보가 순차적으로 전달되는 과정에서 소실/희석의 가능성 있음
- CNN의 제한적인 수용 영역: CNN은 고정된 크기의 필터를 사용하기 때문에 전체 시퀀스에 대한 정보를 얻기 위해서는 여러 계층을 거쳐야 함. 이 과정에서 장거리 의존성 학습이 어려워질 수 있음
- 인코더와 디코더를 포함하는 구조
Transformer 모델의 특징
- Attention 메커니즘만을 사용하여 순환 및 합성곱을 완전히 제거
- 병렬화 용이, 훈련 시간 대폭 단축
Transformer 모델의 성능
- WMT 2014 영어-독일어 번역에서 28.4 BLEU 달성, 기존 최고 결과보다 2 BLEU 이상 향상
- WMT 2014 영어-프랑스어 번역에서 41.8 BLEU 기록, 새로운 단일 모델 최고 성능
- 8개의 GPU로 3.5일 만에 훈련 완료
2. Transformer 모델의 배경과 특징
- Transformer: self-attention 메커니즘을 활용하여 입력과 출력의 표현을 계산하는 최초의 전이 모델
*self-attention: 단일 시퀀스 내의 여러 위치 간의 상관관계를 계산하여 시퀀스의 표현을 생성하는 메커니즘
- 순차적 계산 감소를 목표로 함
- 병렬 처리를 통한 효율적인 연산
- 입력과 출력 간의 거리가 멀어질수록 의존성을 학습하기 어려워지는 문제 해결
- reading comprehension(독해), abstractive summarization(생성 요약), textual entailment(함의 분석) 등의 작업 가능
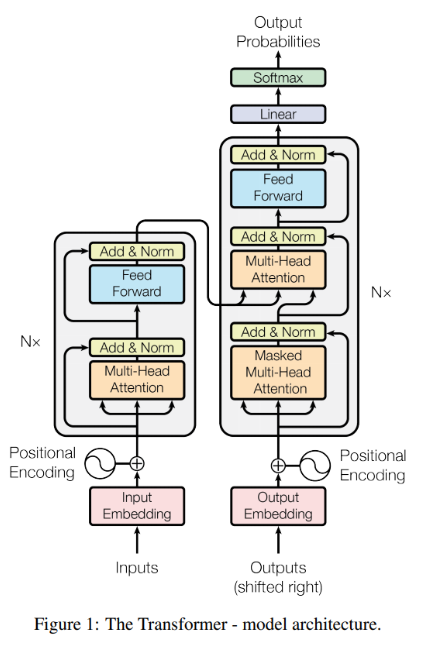
3. 모델 아키텍처 및 어텐션 메커니즘
Encoder-Decoder
가장 경쟁력 있는 신경망 시퀀스 변환 모델에서 채택되는 형태.
- Encoder: 입력 시퀀스를 연속 표현으로 매핑
- Decoder: 표현을 활용하여 출력 시퀀스 생성
모델의 자동 회귀 특성으로 decoder는 생성된 이전 시퀀스를 추가 입력으로 사용하여 다음 시퀀스를 생성하는 데 활용
Attention: ‘입력의 어떤 부분이 중요한가?’
쿼리와 키-값 쌍의 집합을 매핑하여 출력을 생성, 이 때 쿼리와 키의 맞춤도를 기반으로 가중합을 계산
(+) 쿼리와 키의 맞춤도(compatibility)
어텐션 메커니즘에서 두 벡터가 얼마나 잘 맞는지(연관성이 높은지) 측정하는 개념
-
쿼리(Q): 현재 처리 중인 단어가 ‘어떤 정보를 찾고 싶은지’ 나타냄
-
키(K): 각 입력 단어가 ‘어떤 정보를 가지고 있는지’ 나타냄
맞춤도가 높을수록 해당 키에 해당하는 값(Value)이 더 중요한 정보로 간주
Scaled Dot-Product Attention: 맞춤도를 계산하는 방법
Scaled Dot-Product Attention

쿼리와 키 벡터 간의 내적을 계산하고, 이를 기반으로 softmax 함수를 통해 가중치를 할당하며 값을 도출
- : 쿼리와 키의 내적(dot product)를 계산해 맞춤도 측정
- : 키 벡터의 차원 수로 나누어 값이 너무 커지는 것을 방지
- softmax: 결과를 확률 분포로 치환
쿼리와 키의 내적이 크면(큰 값이 나오면) 맞춤도가 높음 → 높은 가중치
쿼지와 키의 내적이 작으면(작은 값이 나오면) 맞춤도가 낮음 → 낮은 가중치 부여
텍스트 간 의미 관계를 내적으로 계산하는 이유
-
단어(텍스트)를 벡터로 표현하는 이유
컴퓨터는 텍스트를 직접 이해할 수 없기 때문에, 텍스트를 수치화(벡터화) 해야 함.
Transformer에서는 각 단어를 고유한 고차원 벡터(임베딩 벡터)로 변환해서 연산을 수행
→ 단어 자체가 아닌, 단어를 표현하는 벡터들의 관계를 기반으로 의미를 비교
(예) 단어 ‘king’과 ‘queen’이 의미적으로 가깝다면, 두 단어의 벡터 표현도 가까운 위치에 있을 것
-
내적(dot product)이 관계를 측정하는 이유
[1] 벡터의 내적은 유사도(silmilarity)를 측정하는 방법 중 하나
*벡터의 내적은 두 벡터의 방향이 얼마나 비슷한지 표현*- 내적 값이 크면 → 두 벡터가 유사한 방향을 가짐 → 의미적으로 비슷
- 내적 값이 작거나 음수 → 두 벡터가 다른 방향을 가짐 → 의미적으로 다름
[2] 코사인 유사도(cosine similarity)와 연결
코사인 유사도: 두 벡터가 이루는 각도의 코사인 값을 이용해서 유사도를 측정하는 방법내적을 계산하는 방식도 유사한 개념. 내적이 크면 두 벡터의 방향이 비슷하고, 내적이 작으면 두 벡터의 방향이 다름을 의미[3] 행렬 연산 최적화
내적을 사용하면 대량의 벡터 연산을 빠르게 수행할 수 있음 (예) $QK^T$ 연산: Q(쿼리 행렬)과 $K^T$(키 행렬)를 한번에 내적 계산 가능, GPU 병렬 연산 활용 가능, 효율적
Multi-Head Attention: Attention 병렬로 수행하기
여러 개의 Attention 레이어를 병렬로 실행하여 각각의 쿼리, 키, 값에 대한 정보를 통합
→ 다양한 시각에서 문맥 정보를 동시에 고려할 수 있게 됨
왜 여러 개의 Attention을 사용할까
-
단일 Attention만 사용하면 하나의 시점에서 한 가지 관계만 학습할 수 있음 하지만 언어에서는 같은 단어라도 여러 가지 의미적 관계를 가질 수 있음
(예) ‘The animal didn’t cross ther street because it was too tired.’
→ 여기서 it이 animal을 가리킨다는 관계를 찾는 Attention이 필요
-
병렬 연산이 가능해져 학습 속도 증가 → 효율적
Multi-Head Attention
멀티 헤드 어텐션은 여러 개의 독립적인 Attention 연산을 수행한 후, 그 결과를 결합하는 방식으로 동작
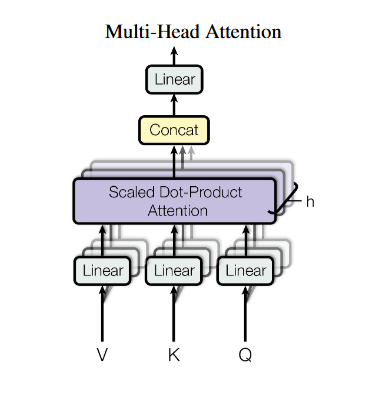
각 헤드는 다음처럼 독립적으로 Scaled Dot-Product Attention 수행
- : 각 헤드마다 다른 가중치 행렬
- : 여러 개의 헤드 결합
- : 최종 선형 변환을 위한 가중치 행렬
즉, 각 헤드는 서로 다른 방식으로 중요한 부분을 집중(attention) 하게 되고, 마지막에 이를 결합하여 최종 결과를 생성
Multi-Head Attention 사용 영역
- Encoder Self-Attention: 입력 문장의 어텐션
- Decoder Self-Attention: 출력 문장의 어텐션
- Encoder-Decoder Attention: 입력과 출력 간 어텐션
Multi-Head Attention의 동작
멀티 헤드 어텐션을 적용하면, 각 헤드가 문장 내에서 서로 다른 패턴을 찾음
(예) 어떤 헤드는 ‘문법적 구조(주어-동사 관계)’를 학습, 어떤 헤드는 ‘대명사 해석’을 학습
4. Self-Attention 구조와 효율성
Self-Attention의 효율성

self-attention, RNN, CNN의 연산 복잡도를 비교한 결과, self-attention은 RNN 보다 병렬화가 가능하며, CNN보다 더 짧은 경로로 정보 전달이 가능
Positional Encoding: 위치 정보 추가하기
모델이 입력 시퀀스의 상대적/절대적 위치를 이해할 수 있도록 정보 제공
- 방법: sin, cos 함수 사용
- 이유: 상대적 거리 정보 유지 가능
실험 결과, 학습된 위치 임베딩과 사인 함수 기반 위치 인코딩의 결과는 거의 동일, 따라서 사인 함수 기반 버전 채택
Self-Attention의 장점
- 병렬 처리 가능(RNN 보다 빠름) → 계산량 감소
- 장거리 관계 학습 가능(CNN보다 효율적) → 신호의 경로 길이가 짧음
- 모델 해석 가능성 증가: 각 단어가 어디를 집중해서 보는지 시각화 가능
*경로 길이를 줄이는 방법이 향후 연구에서 제시될 것
모델 훈련 및 데이터 세트
실험에 사용된 데이터 셋
- WMT 2014 English-German (450만 개 문장)
- WMT 2014 English-French (3600만 개 문장)
사용한 하드웨어
- NVIDIA P100 GPU 8개
- Base 모델: 12시간 학습 (10만 step)
- Big 모델: 3.5일 학습 (30만 step)
Optimizer 및 Regularization 기법
Adam Optimizer
- 학습률 스케줄링초반에는 학습률을 증가시키고, 이후 점차 감소시키는 방식
Regularization: 과적합 방지
- Dropout 사용 (Base 모델: 10%, Big 모델: 30%)
- Label Smoothing (레이블 스무딩, )
- 모델이 너무 확신하지 않도록 하기 위해 적용
- perplexity는 증가하지만 BLEU 점수는 개선
(+) Perplextity(혼란도, PPL)
언어 모델의 성능을 측정하는 지표 중 하나, 모델이 얼마나 ‘예측을 잘 하는지’를 나타내는 값
- 낮을수록 모델이 더 정확하게 예측 → 좋은 모델
- 높을수록 모델이 예측을 헷갈려함 → 안 좋은 모델
- : 문장의 총 단어 수
- ): 이전 단어들을 보고 다음 단어 가 나올 확률
모델이 예측한 확률값의 로그 평균을 지수로 변환한 값, 이 값이 작을수록 모델이 다음 단어를 더 잘 예측하고 있다는 뜻
Transformer의 성능
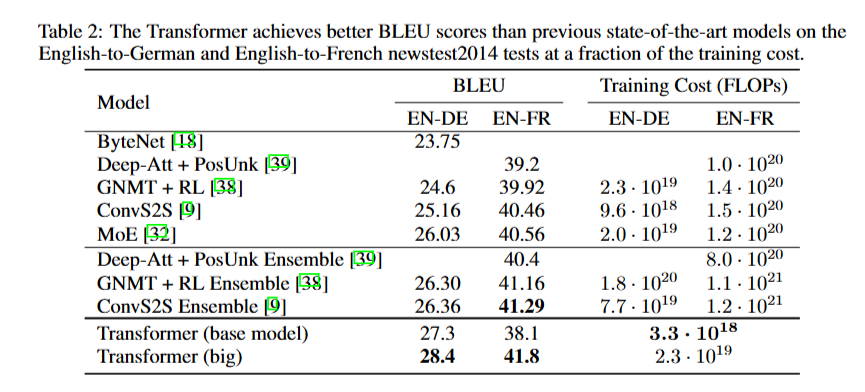
- WMT2014 영어-독일어 번역 작업에서 Transformer(big) 모델이 28.4의 BLEU 점수를 기록하여 이전 모델들보다 2.0 이상 높은 점수로 최신 기중 중 하나를 수립
- WMT2014 영어-프랑스어 번역 작업에서도 Transformer(big) 모델은 41.0의 BLEU 점수를 달성하여 이전 모델들의 성능을 뛰어넘었으며, 1/4의 훈련 비용
성능 최적화
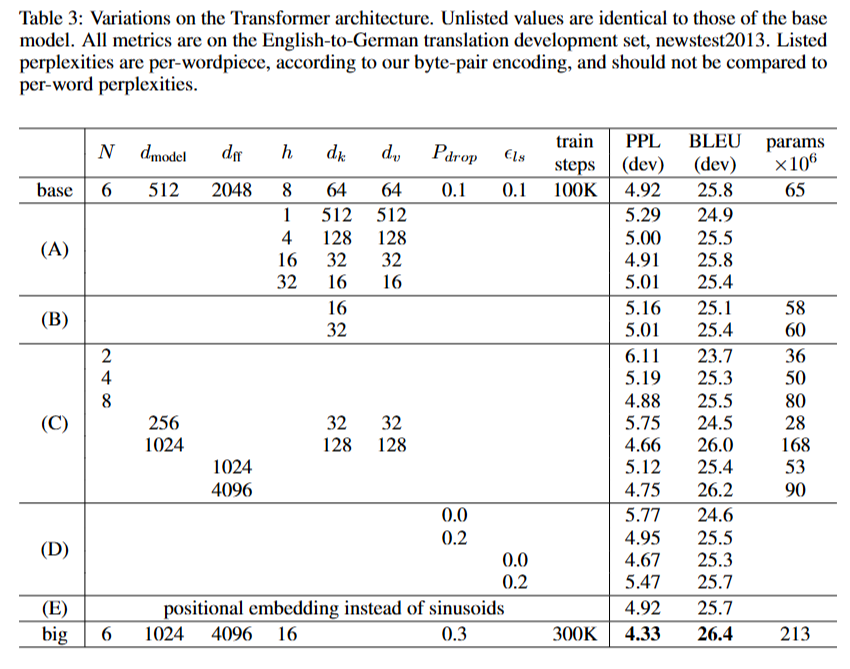
모델의 크기와 드롭아웃이 효과적인 성능 개선 요소로 관찰됨
모델 평가
28.4 BLEU를 달성한 것은 상당히 우수한 성능. 기존의 최고 결과보다 2 BLEU 이상 향상된 결과
(+) BLEU(Bilingual Evaluation Understudy)
기계 번역의 품질을 평가하는 데 사용되는 지표(범위: 0 ~ 100), 점수가 높을수록 번역 품질 우수
- 20 ~ 30 BLEU: 양호한 수준, 어느 정도 의미 전달이 가능하지만 오류가 있을 수 있음
- 30 ~ 40 BLEU: 우수한 수준, 대부분의 의미가 정확하게 전달되며 자연스러운 번역에 가까움
- 40 + BLEU: 매우 우수한 수준, 인간 번역에 근접한 품질을 나타냄
5. 결론
Transformer의 주요 기여
기존의 RNN 및 CNN 기반 모델보다 더 빠르고, 더 강력한 성능을 보임
- Recurrent Layer 없이 더 빠르게 학습 가능
- WMT 2014 English-German & English-French 번역에서 SOTA 성능 달성
- 기존 모델보다 2.0 이상 증가된 BLEU
- 병렬 학습 가능으로 GPu에서 학습 능력 향상
- 장거리 의존성(Long-term Dependency) 학습 능력 향상
- self-attention을 사용하여 멀리 떨어진 단어 간 관계도 쉽게 학습 가능
향후 연구 방향
- 다양한 입력과 출력에 적용 가능
- 텍스트뿐만 아니라 이미지, 오디오, 비디오 등 다양한 데이터에도 적용 가능할 것
- 더 큰 입력 시퀀스를 다룰 방법 탐색
- self-attention은 계산량이 이므로, 긴 시퀀스를 처리하는 데 부담이 있음
- 이를 해결하기 위해 로컬 어텐션(local attention) 같은 기법을 연구할 필요가 있음
- 생성 모델의 비순차적(non-sequential) 구조 탐색
- 현재 Transformer의 디코더는 한 번에 하나씩 단어를 생성해야 함
- 하지만 모델이 동시에 여러 단어를 생성할 수 있는 방법도 연구할 가치가 있음
요약
1️⃣ Recurrent 구조 제거 (No RNN, No LSTM)
- 기존 Seq2Seq 모델은 RNN 계열(LSTM, GRU 등)을 사용했음
- 하지만 RNN은 순차적 처리(sequential processing)로 인해 학습 속도가 느리고, 병렬화가 어려움
- Transformer는 Self-Attention만 사용하여 모든 단어를 동시에 처리할 수 있도록 설계됨
2️⃣ Self-Attention을 통해 문맥(Context) 학습 가능
- RNN처럼 순차적으로 데이터를 입력받지 않아도, 모든 단어 간 관계를 한 번에 계산할 수 있음
- 특히 멀리 떨어진 단어(long-range dependency) 간의 관계도 쉽게 학습 가능
- 이를 위해 Scaled Dot-Product Attention을 사용하여 효율적으로 연산 수행
3️⃣ Multi-Head Attention을 사용하여 다양한 관계 학습
- 하나의 어텐션만 사용할 경우 한 가지 패턴만 학습할 수 있음
- 여러 개의 어텐션 헤드(Multi-Head Attention)를 병렬로 사용하여,단어 간의 다양한 관계(구문적, 의미적 관계 등)를 학습할 수 있도록 설계
4️⃣ Positional Encoding을 추가하여 순서 정보 보완
- Self-Attention은 모든 단어를 동시에 처리하므로, 단어의 순서를 직접 알 수 없음
- 이를 해결하기 위해 Positional Encoding (위치 정보 추가 기법)을 도입하여 순서 정보를 반영
5️⃣ 병렬 처리 가능 & 학습 속도 개선
- RNN은 순차적으로 학습해야 하지만, Transformer는 모든 단어를 동시에 처리 가능
- 이를 통해 GPU 병렬 연산을 극대화하여 학습 속도를 크게 향상
