- 분류: Vision Model
- 저자: Alex Krizhevsky, IIya Sutskerver, Geoffrey E.Hinton
- 소속: University of Toronto
- paper: ImageNet Classification with Deep Convolutional Neural Networks
- 키워드: CNN, AlexNet, GPU Acceleration, dropout
1. 연구 배경
기존의 객체 인식 연구
기존의 객체 인식(Object Recognition) 모델들은 ML 기법 사용
성능을 높이기 위해서는 다음과 같은 조건이 필요
- 더 많은 데이터
- 더 강력한 모델
- 정교한 학습 기법(과적합 방지)
당시 사용되던 데이터 셋(NORB, CIFAR-10, Caltech-101)은 크기가 한정적
→ 대규모 데이터셋 부족. 모델이 복잡한 객체를 학습하는 데에 어려움을 겪음
ImageNet의 등장
ImageNet 데이터셋(1500만개 이상의 이미지, 22,000개 이상의 카테고리)의 등장으로 깊고 강력한 신경망 훈련이 가능해졌다.
기존 CNN은 (1) 높은 계산량으로 대규모 이미지 데이터셋에 적용이 곤란했으며, (2) 느린 학습 속도로 과적한 문제가 발생했으므로,
대규모 데이터셋에 효과적으로 적용할 수 있는 CNN 모델을 설계하고 학습하는 방법을 제안하는 것이 목표
2. 핵심 아이디어 및 방법론
대규모 CNN 모델 설계
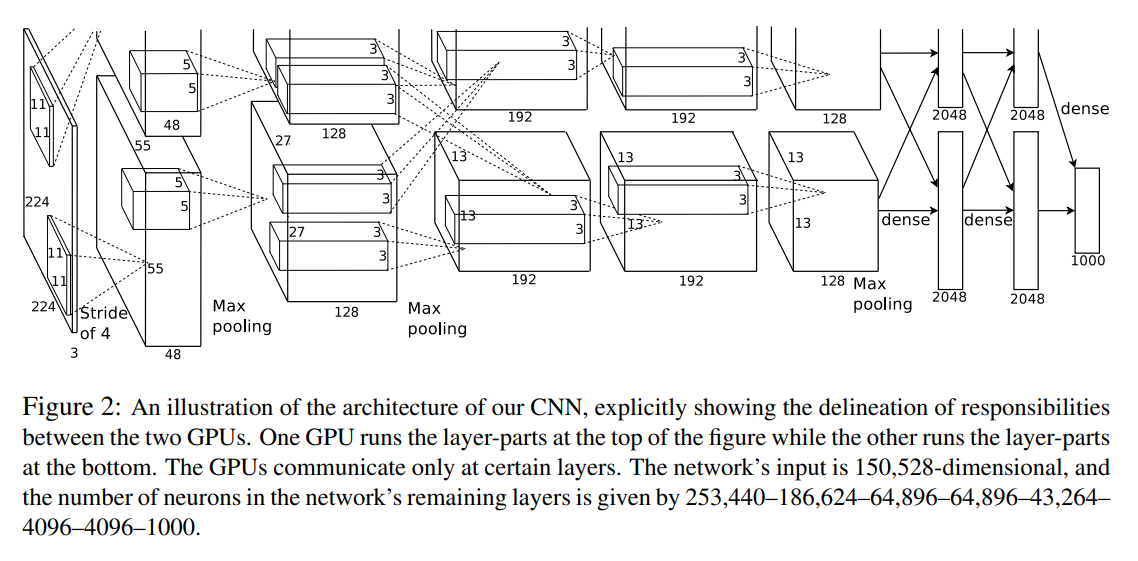
총 8개의 layer
- 5 convolutional layer
- 3 fully connected layer
- 출력층: 1000-way softmax
6000만개의 파라미터, 65만개의 뉴런
성능 개선 기법
1) ReLu 활성 함수 사용
- sigmoid, tanh 대비 6배 빠른 속도
- Vanishing Gradient(기울기 소실) 해결
2) GPU 병렬 학습
- 2개의 GTX 580 GPU에서 네트워크를 나누어 학습
- 일부 계층에서만 GPU 간 통신 → 계산량 최적화
- 단일 GPU 대비 1.7% Top-1, 1.2% Top-5 오류율 감소
(+) Top-1 Error Rate, Top-5 Error Rate
- Top-1 Error Rate: 모델이 예측한 가장 확률이 높은 1개의 클래스가 정답이 아닐 확률
- Top-5 Error Rate: 상위 5개 클래스 중 하나도 일치하지 않는 확률
3) 지역적 응답 정규화(Local Response Normalization, LRN)
CNN 모델에서 LRN을 대규모로 적용한 것은 최초
- 특정 뉴런이 과도하게 활성화되지 않도록 경쟁 메커니즘
- 일반화 성능 향상 → Top-1 오류율 1.4% 감소
4) 겹치는 풀링(Overlapping Pooling)
overlapping pooling으로 정의내린 것은 최초
- 기존 CNN 풀링: non-overlapping → 과적합
- stride = 2, window_size = 3 사용 → 일반화 성능 향상
- Top-1 오류율 0.4% 감소
3. 실험 및 핵심 작업
1) 데이터 셋
- ImageNet ILSVRC2010: 1000 클래스, 120만개 이미지
- Top-1, Top-5 오류율 평가
- input data: 256 256으로 resizing, 중앙 224 224 크롭
2) 학습 설정
SGD(Stochastic Gradient Descent)
- batch size: 128
- momentum: 0.9
- weight decay: 5e-4
- 초기 learning rate: 0.01 검증 성능이 멈추면 1/10로 감소
Dropout
대규모 CNN에서 적용한 최초의 사례
- fully connected layer에서 50% 뉴런을 랜덤으로 비활성화
- 과적합 방지 효과가 크게 나타남
- 학습 속도 약 2배 증가
1) 랜덤 뉴런 비활성화: 완전한 구조가 아니기 때문에 수렴이 느려짐
2) 다양한 네트워크 조합 학습
3) 일반화 성능 향상
(+) 학습 속도가 느려짐에도 사용하는 이유?
일반적으로 전체 성능보다 일반화 성능이 우선이기 때문에 속도를 희생하더라도 사용
훈련 시간
- NVIDIA GTX 580 (3GB) 2개
- 5-6일 훈련
4. 결과 및 비교 분석
1) ImageNet ILSVRC2010
- Top-1 오류율 : 37.5% (기존 최고 성능 47.1%)
- Top-5 오류율: 17.0% (기존 최고 성능 28.2%)
2) ImageNet ILSVRC2012
- 1개의 CNN 모델: Top-5 오류율 18.2%
- 5개의 CNN 모델 평균 결합: Top-5 오류율 16.4%
- ImageNet 전체 데이터로 pre-training 후, fine-tuning: Top-5 오류율 15.3%
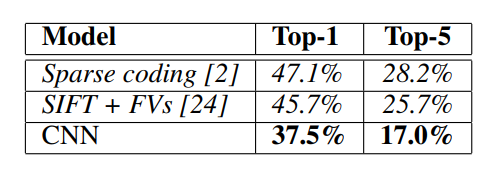

CNN 활용 시, 시존 모델 대비 오류율 크게 감소하는 것을 확인할 수 있음
여러 개의 CNN 앙상블 시, 추가적인 성능 향상 가능
5. 결론 및 향후 연구 방향
1) 연구의 기여
- 대규모 CNN 모델을 처음으로 대규모 데이터셋에 적용
- 기존 방식보다 오류율을 대폭 낮추고, 새로운 정규화 기법(LRN, Dropout 등) 도입
- CNN이 대규모 이미지 분류에서 효과적임을 입증
2) 향후 연구 방향
- 더 깊고 복잡한 네트워크 구조 연구
- 더 빠른 GPU & 더 큰 데이터셋 활용
- CNN을 비디오나 실시간 객체 인식에 적용 가능한지 탐색
3) 한계점
- 높은 연산 비용
- 모델 크기와 메모리 요구량: 모바일 & 임베디드 환경에서는 사용 곤란
- 데이터 증강에 대한 의존성 랜덤 크롭, RGB 변형 등의 데이터 증강 기법을 사용하였는데 이러한 작업은 훈련 시에만 적용 가능, 실제 배포 모델에서는 동일한 성능을 보장하지 못함
- 과적합 문제 해결을 위한 근본적 접근 부족 일부 기법이 과적합 방지에 도움을 줬지만, 여전히 대규모 데이터가 아니면 과적합이 일어남
- CNN의 구조적 한계 지역적(feature locality) 특징 학습에 강점을 가지지만, 전역적(global) 관계 학습에 한계를 가짐 (개별 이미지 내에서 특징을 추출하는 데에 강하지만, 이미지 간 관계 학습 곤란)

넓고 얕게? 좁고 깊게?