- 분류: ETC
- 저자: Geoffrey Hinton, Oriol Vinyals, Jeff Dean
- 소속: Google
- paper: Distilling the Knowledge in a Neural Network
- 키워드: knowledge distillation, model compression, soft targets
1. 연구 배경
머신러닝 모델의 성능을 향상시키는 일반적 방법
여러 개 모델을 학습한 뒤, 예측값을 평균 내는 앙상블
-> 대형 신경망 모델을 여러 개 사용
=> 계산 비용이 높아 실제 서비스에서 사용하기 곤란함
따라서, 앙상블 모델의 지식을 하나의 모델로 압축하는 법 제안
지식 증류(Knowledge Distillation)
2. 핵심 아이디어 및 방법론
- 지식 증류(knowledge distillation): 큰 신경망(또는 앙상블)의 지식을 작은 신경망에 전이
- 기존 모델이 예측한 소프트 타겟을 활용하여 새로운 모델 학습
(+) 소프트 타겟: 기존의 하드 타겟 대신 사용할 수 있는 확률 분포 형태의 정답 레벨- 하드타겟: 원-핫 형태의 정답 라벨
MNIST 숫자 분류(7) -> [0, 0, 0, 0, 0, 0, 0, 1, 0, 0]- 소프트타겟: 출력 확률 분포
MNIST 숫자 분류 -> [0.01, 0.02, 0.03, 0.01, 0.02, 0.05, 0.10, 0.65, 0.08, 0.03] - 순서
- 로짓 변환으로 정보량이 높은 확률 분포 생성
- 높은 온도를 사용한 softmax 적용
- 작은 모델이 큰 모델의 일반화 능력을 학습하도록 함
(+) 높은 온도를 사용한 softmax
1. softmax: 모델의 로짓을 확률 분포로 변환
- : 클래스 i에 대한 로짓값(모델의 출력값)
- T: 온도
- : 클래스 i에 대한 확률값
- 온도의 역할: 소프트맥스의 출력 확률 분포 조절
: 일반적인 softmax 확률 분포
: 확률 분포가 더 '확신'하는 형태가 됨 -> 가장 큰 로짓 값을 가진 클래스에 확률 집중
: 확률 분포가 더 부드러워짐 -> 여러 클래스에 대한 확률 값이 고르게 퍼짐 -> 가장 높은 확률을 가진 클래스와 그 외 클래스의 차이가 줄어듦
3. 실험 및 핵심 작업
1) MNIST 실험
- 두 개의 은닉층(각 1200개 RELU 유닛)을 가진 대형 신경망 학습 -> 테스트 에러 67개
- 작은 네트워크(800개 유닛, 은닉층 2개) 학습 -> 테스트 에러 146개 발생
-> 지식 증류 적용 시, 에러 74개로 감소
=> 작은 모델이 큰 모델의 일반화 능력을 학습했음을 의미
2) 음성 인식(Acoustic Model) 실험
- android 음성 검색에 사용되는 음향 모델(DNN) 기반 실험
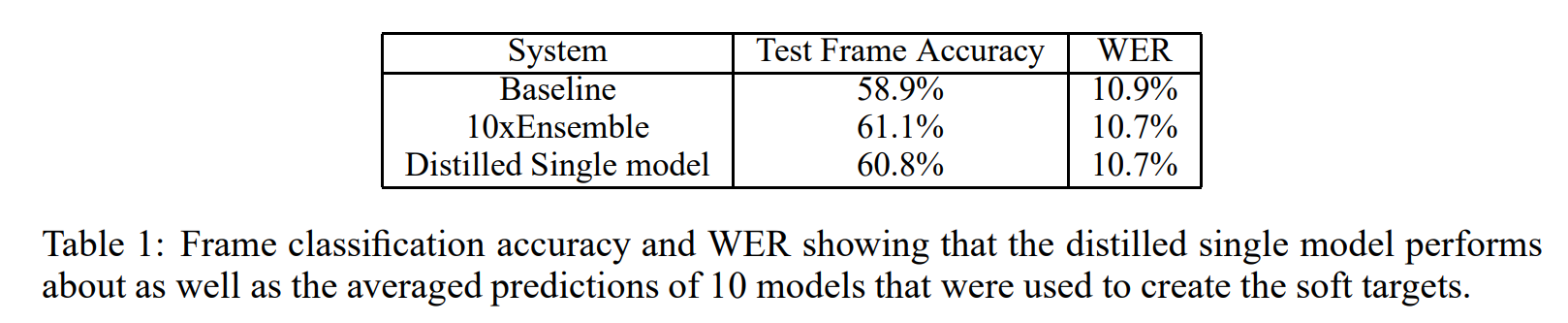
- test frame accuracy
음향 모델이 개별 음소 또는 HMM(hidden markov model)상태에 대해 올바르게 예측한 비율
*프레임 단위의 정확도가 높다고 새서 전체 단어 인식(WER)이 낮아지는 것은 아님 - WER(Word Error Rate, 단어 오류율)
WER가 더 메인 성능
3) 대규모 데이터셋(JFT)
- google 내부의 1억 개 이미지, 15000개 레이블 포함 대형 데이터셋
- '일반 모델(Generalist)'과 '전문가 모델(specialist)'를 조합한 새로운 앙상블 구조 제안
- 특정 클래스에 대해 학습한 '전문가 모델' 활용 시, 테스트 정확도 4.4% 향상
4. 결과 및 분석
1) 지식 증류의 효과
- 작은 모델도 큰 모델의 일반화 능력을 효과적으로 학습 가능
- soft target을 활용하면 적은 데이터로도 높은 성능 유지 가능
- 특정 클래스를 구별하는 전문가 모델 활용 -> 성능 더욱 향상
2) 실용적 이점
- 배포가 용이한 소형 모델을 만들 수 있음 -> 실제 시스템에서 유용
- 앙상블 모델의 예측력을 단일 모델로 압축하여 연산 비용 절감
- 음성 인식 & 이미지 분류 같은 대형 데이터셋에 적용 가능
5. 결론 및 향후 연구 방향
1) 의의
- 기존의 단순한 모델 압축 기법보다 효과적인 지식 전이 방법
- 소프트 타겟을 활용한 지식 증류 -> 모델의 일반화 성능에 기여
- 음성 인식 이미지 분류 등 다양한 분야에서 활용 가능함을 검증
2) 한계점 및 향후 연구
- 전문가 모델과 일반 모델을 결합하는 최적의 방법론 탐색 필요
- 보다 복잡한 데이터셋에서의 성능 평가 및 최적화 필요
- 추후 연구에서는 '전문가 모델의 지식도 다시 단일 모델로 증류할 수 있는지'에 대한 추가 실험 필요

넓고 얕게? 좁고 깊게?