자료구조
내가 이해한 선에서 간단하게 축약하자면 자료구조란 데이터 값들을 담아두는 방식을 의미한다.
하나의 데이터를 한 장의 종이로 빗대었을 때 종이를 뭉치로 엮어둘 수도 있고 한 장씩 파일에 껴놓을 수도 있고 바닥부터 쌓아두거나 필요한 위치에 각각 따로 둘 수도 있다. 어떤 방식이 가장 효율적인지는 종이가 필요한 상황에 따라 자주 다루는 방식에 따라 달라질 수 있다.
이와 같이 자료구조의 각 특징을 살펴보고 데이터의 형태나 접근 방식과 가장 적합한 구조를 선택할 수 있다.
Stack
First In Last Out 후입 선출
Stack Big O
Insertion : O(1)
Deletion : O(1)
Search : O(n)stack 스택 구조는 책을 쌓는 것으로 자주 비유된다. 예를 들어, 바닥부터 차례로 책을 쌓아 올린다고 가정했을 때 첫 번째로 놓은 책이 가장 아래에 있고 마지막으로 놓은 책이 가장 위에 위치하게 된다. 이 때, 원하는 책 한권을 찾아야 한다면 가장 마지막에 올려놓은 맨 위에 책부터 하나 하나 확인해 나가야 하는 것과 같다.
한 권의 책 = 하나의 데이터와 같다고 생각할 수 있다.
실제 사용에서는 command + z키로 작성된 코드나 텍스트를 지우는 경우나 메모 앱에 그림을 그린 뒤 '뒤로' 버튼을 누르는 경우에 가장 마지막에 작업한 것부터 뒤로 돌아가는 모습에서 쉽게 스택 구조를 찾아볼 수 있다.
스택 적용으로는 세 번째 프로젝트에 캔버스를 끼웠는데 이후 더 작업하게 된다면 path를 스택 구조로 쌓아서 실행 취소를 누르면 마지막에 그린 path 부터 하나씩 지우는 상황에서 적용 해 볼 예정이다.
Queue
First In First out 선입 선출
Queue Big O
Insertion : O(1)
Deletion : O(1)
Search : O(n)Queue 큐는 정확히 스택의 반대이다. 이름처럼 줄 서는 것과 같다. 먼저 줄 선 데이터가 먼저 나가는 것.
실제 적용했던 예시로는 sorting algorithms 시각화시 애니메이션 효과를 위해 시간 지연이 있어야 하는데 알고리즘 내에 setTimeout을 걸어서 정렬을 지연시키려면 애니메이션과 초단위로 불필요하게 철저한 계산이 필요했다.
따라서 먼저 함수를 돌려 정렬 순서를 큐 구조로 쌓아두고 애니메이션 작업시 먼저 쌓인 데이터부터 차례로 가져와 화면에 그려주었다. 이 경우에는 애니메이션에서 필요한 시간만 계산하여 setTimout을 걸어두면 되었다.
Linked List
Linked List 연결 리스트는 각 node(데이터를 가진 최소 단위) 들이 위치한 자리의 뒤, 혹은 앞/ 뒤의 정보를 함께 가지고 있는 자료 구조이다.
Linked List Big O
Insertion : O(1)
Deletion : O(1)
Search : O(n)
Linear Linked List 단방향 연결 리스트
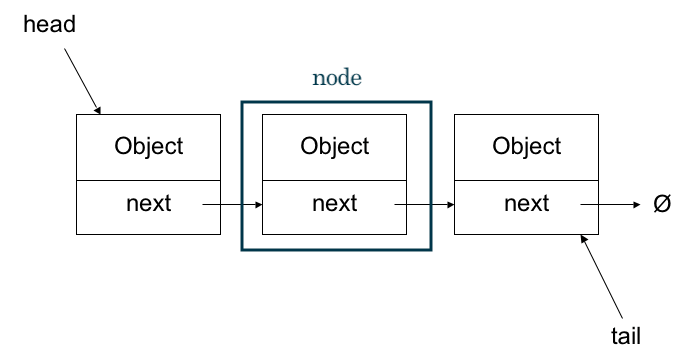
단방향 연결 리스트에서 각 노드들은 바로 뒤의 정보를 가지고 있다.
즉, value 값과 next 값이 하나의 node를 이룬다고 볼 수 있다.
가장 첫 번째 정보를 head, 가장 마지막 정보를 tail라고 일컬으며 tail의 next 값은 null이다.
예를 들어 한 사람씩 차례로 입장 가능한 상점에 단방향 연결 리스트 구조로 대기를 하고 있다고 가정했을 때, 내 다음 사람이 누구인지만 기억한다면 물리적인 줄을 있지 않더라도 다음 사람을 불러 입장 가능하게 해줄 수 있다. 이때 대기 줄에 누군가 한 명 추가하거나 삭제한다면 추가/ 삭제할 위치의 앞 사람에게만 변경된 정보(변경된 다음 사람의 정보)를 알려주면 된다. 여기서 나와 내가 알고 있는 다음 사람에 대한 정보를 하나의 노드(데이터)라고 일컫는다.
Doubly Linked List 양방향 연결 리스트
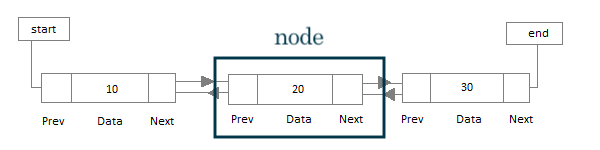
양방향 연결 리스트들은 노드 뒤의 정보를 가지고 있는 단방향 연결 리스트에서 추가로 앞의 정보도 가지고 있는 것이다.
즉, value값과 previous, next 값이 하나의 node를 이룬다고 할 수 있다.
위와 비슷한 예시를 이어가 양방향 연결 리스트로 대기를 하게 된다면 누군가 추가/ 삭제가 되었을 때 해당 위치의 앞 뒤 사람들의 변경된 정보만 전달하면 된다. 이때 나와 내 앞, 뒤 사람에 대한 정보를 하나의 노드로 묶게 된다.
linear ? doubly?
Liner 장단점
단방향 연결은 Head의 정보나 위치를 알지 못하면 혹은 중간 노드의 정보가 손실되면 데이터 전체/일부를 사용할 수 없다는 치명적인 단점이 있으나 메모리 차지가 작다는 장점이 있다.
Doubly 장단점
양방향 연결은 이전 노드 지정을 위해 단방향보다 메모리를 더 많이 차지한다는 단점이 있으나
전체 길이의 중간을 기준으로 head 부터 next의 정보로, tail 부터는 prev의 정보로 검색할 수 있어 물론 최악의 경우에는 모든 노드를 검사해야할 일도 있겠지만 상황에 따라 앞 뒤의 탐색 방향을 정해야 한다면 양방향 연결 리스트가 유용하다.
array list? linked list?
연결 리스트는 배열과 자주 비교 언급되는데 다루는 자료를 접근 방식에 따라 장단점이 있을 수 있다.
array list 장단점
array는 각 데이터가 index 번호를 가지고 있어 위치 값을 안다면 정보 검색의 시간 복잡도가 O(1)으로 빠르다는 장점이 있으나,
앞 뒤 데이터의 정보를 모른 채 독립적으로 존재하는 것이기 때문에 추가/ 삭제시 해당 index의 뒤쪽 데이터의 index 번호를 모두 변경해주어야 한다는 단점이 있다.
linked list 장단점
연결 리스트는 각 노드들이 앞/뒤의 정보를 가지고 있어 순차적으로 검색 해야만 정보에 접근할 수 있으므로 검색의 시간 복잡도가 O(n)으로 array list보다 느리다는 단점이 있으나,
각 요소들이 연결되어 있기 때문에 추가/ 삭제시 위에 언급한 것처럼 해당 노드의 앞 뒤 노드 정보만 변경해주면 되므로 시간 복잡도가 O(1)으로 빠르다는 장점이 있다.
검색이 잦은 데이터라면
array list를,
추가/ 삭제가 잦은 데이터라면linked list를 사용하는 것이 유용하다.
Hash Table
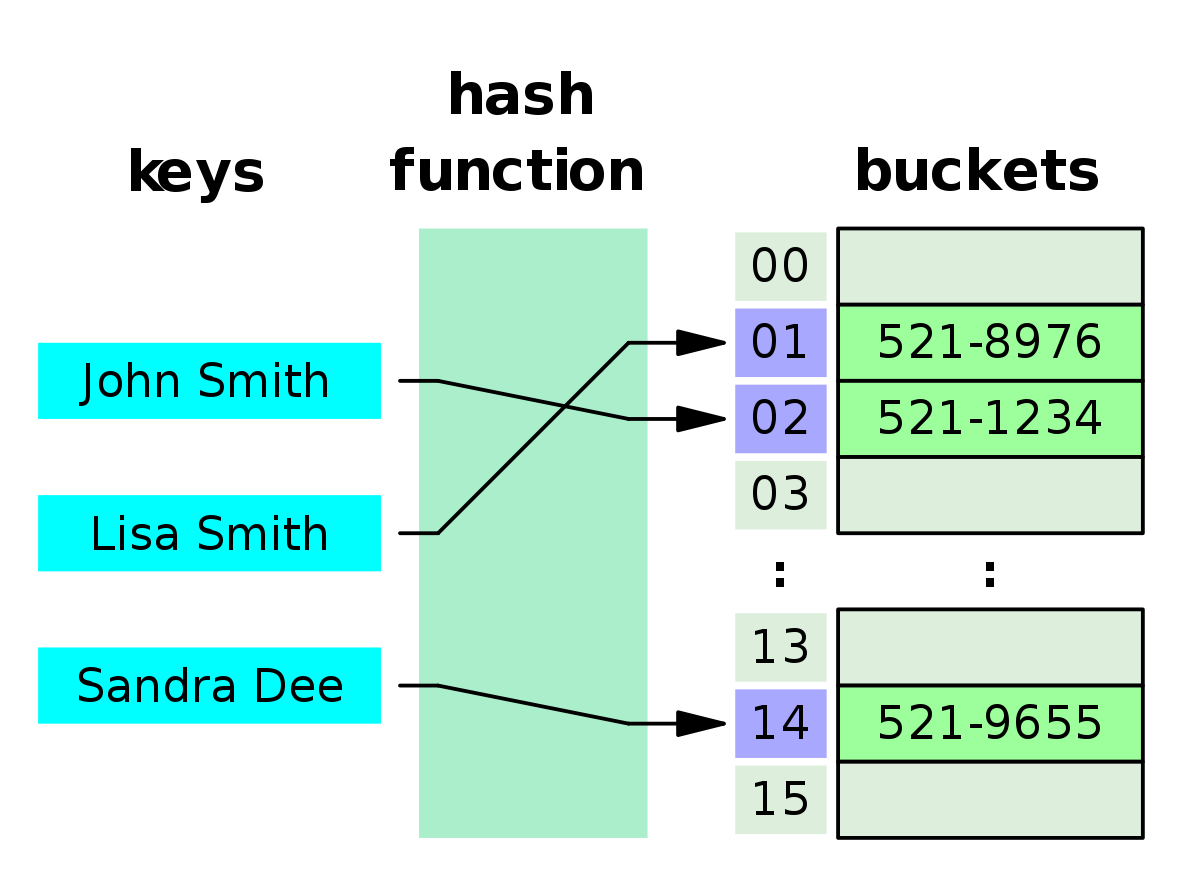
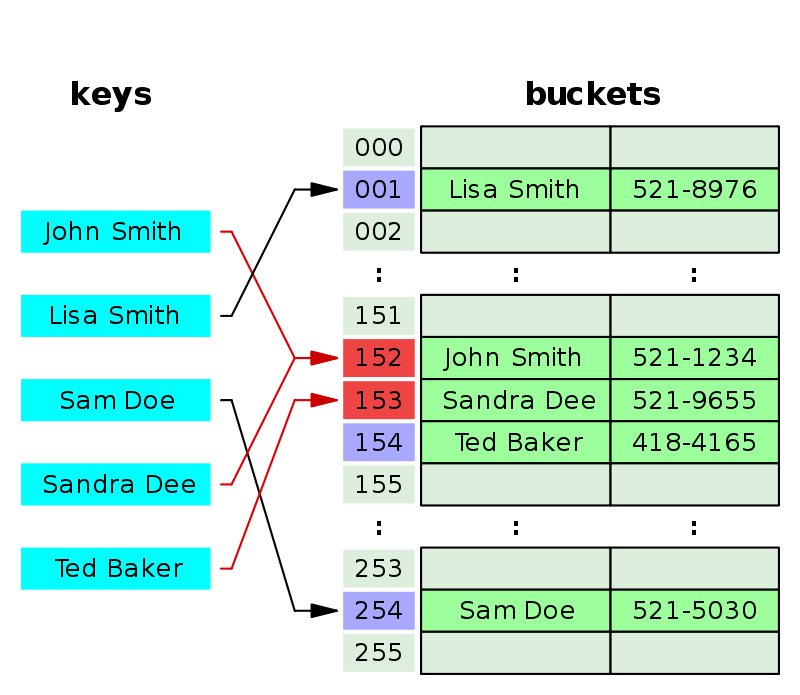
위의 자료와 같이 Hash Table 해시 테이블 구조는 key값을 Hash function 해시 함수에 입력하면 hash고유한 해시 값이 반환되며 해당 해쉬의 위치에 value 값을 저장하는 구조이다.
자바스크립트의 객체(object)가 내부 로직에서는 해시 테이블 구조으로 구성된다고 한다.
또한 해시 테이블 구조는 휴대전화 주소록과 자주 연관되는데 예를 들어, Lisa 번호를 저장할 때 Lisakey가 해시 함수에 입력되면 짜여진 함수에 따라 4라는 hash가 반환되어 해당 위치에 Lisa의 번호value를 저장하는 것이다.
hashing, bucket, slot
key값이 hash값으로 변환되는 과정을 hashing이라 하며,
hash값을 주소로 하여 value값이 저장되는 최종적인 위치를 bucket버킷 혹은 slot슬롯 이라 일컫는다.
Hash Table Big O/ when no collisions
Insertion : O(1)
Deletion : O(1)
Search : O(1)하나의 key값에 하나의 hash값이 반환되기 때문에 추가/ 삭제/ 검색의 속도가 매우 빠르다.
Hash function?
정해진 로직에 의해서 인자로 들어온 정보에 고유한 값을 정해서 반환해주는 함수로 해시 테이블 구조의 상당 부분은 이 함수의 역할에 달려 있다.
Hash function 이 반드시 갖추어야 할 것
- 같은 input에 반드시 같은 output이 고유한 값으로 반환되는 것
- 인자 정보에 따른 해시 값이 고르게 분포되는 것.
해시 함수가 위의 역할을 제대로 하지 못한다거나 혹은 정해진 메모리보다 더 많은 정보가 입력된다면, 해시 충돌이 나게 된다.
what is collision?

인자의 정보가 다른데 반환된 해시 값이 같을 경우 collisions 충돌이 발생했다고 한다.
주소록에 저장하는 정보가 많을수록, 혹은 주소록 메모리의 크기가 1,000명으로 제한되어 있다거나 하는 등의 이유로 불가피한 충돌이 발생하게 된다.
해시 함수의 로직이 아무리 정교하게 짜여져 있다고 하더라도 백만 개의 정보를 저장할 수 있는 메모리에 2,450개의 key값만 입력하더라도 95%의 확률로 같은 hash값이 반환될 수 있다고 한다. 참고
How to solve collision?
아무리 완벽한 해시 함수도 충돌을 발생시킨다고 한다면 충돌 발생을 어떻게 대처하는가? 역시 중요해진다.
1. Closed addressing / Open hashing (chaining)
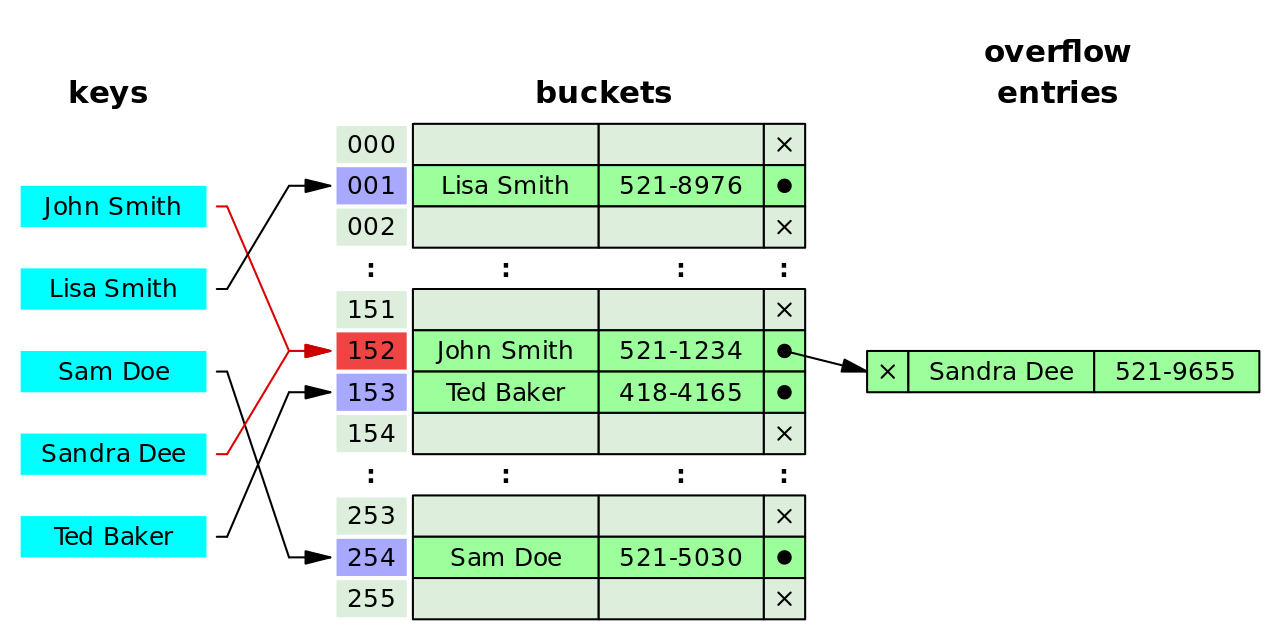
충돌이 난 해시 값에 체이닝을 걸어 정보를 저장하는 방식이다.
체이닝의 경우 반환된 해시 값에 이미 데이터가 저장되어 있다면 listed list나 배열과 같은 구조를 연결시켜 충돌을 해결하기 때문에 상대적으로 간단한 해시 함수 사용이 가능하며 추가 메모리 확장이 가능하다는 장점이 있으나
2. Open addressing / Closed hashing
충돌이 난 해시 값에서부터 바로 다음에 혹은 정해진 만큼의 수 다음에 비어있는 해시 주소를 찾아 정보를 저장하는 방식이다.
반환된 해시 값이 아닌 다른 주소에 값을 저장하기 때문에 open addressing, closed hashing의 의미를 이해할 수 있다.
하나의 저장 공간 내에 모든 정보를 저장하기 때문에 해시 충돌시 저장 공간을 위한 추가적인 작업이 없어도 된다는 장점이 있으나 이후 데이터가 많아져도 메모리의 크기를 확장할 수 없다는 단점이 있다.
Hash Table의 장단점
앞서 언급한 것처럼 해시 테이블은 인자에 따라 고유한 값을 반환해주기 때문에 해쉬 테이블 구조는 검색/ 추가/ 삭제 의 속도가 빠르다는 장점이 있으나, 해시 함수의 질에 따라 성능이 크게 달라질 수 있으며
1. 랜덤하게 값을 배치하기 때문에 순서 정보가 필요한 경우.
2. 정보의 크기를 예측하기 어려운 경우. (공간을 먼저 확보한 후 함수를 실행하기 때문에 이후 메모리가 부족해질 수 있기 때문)
에는 비효율적이라는 단점이 있다.
자료 구조를 구현한 적은 있으나 해시 테이블이나 연결 리스트를 프로젝트에 직접 사용한 적은 없어 첫 번째 프로젝트 db에 redis를 껴서 연결 리스트나 해시 테이블을 사용해볼 예정...
