HTML의 텍스트를 읽거나 쓰기 위해 innerHTML, innerText, textContent 속성을 사용한다.
각 속성의 특성과 장단점을 알아봐서 알맞게 사용해보자!
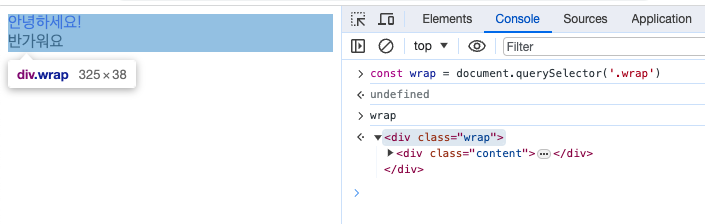
다음과 같은 HTML 구조를 생성하였다.
여기에서 div.wrap 요소를 선택하였다.
innerHTML
🔗 MDN - Element.innerHTML
"요소 내에 포함된 HTML E또는 XML 마크업을 가져오거나 설정합니다"
문자열을 HTML parsing하여 사용하는 경우에 적합

innerText
🔗 MDN - HTMLElement.innerText
"요소와 그 자손의 렌더링 된 텍스트 콘텐츠를 나타냅니다. innerText는 사용자가 커서를 이용해 요소의 콘텐츠를 선택하고 클립보드에 복사했을 때 얻을 수 있는 텍스트의 근삿값을 제공합니다."
MDN 설명대로 우리가 화면에 있는 값을 복사해왔을 경우 얻게되는 텍스트인 셈이다.
<br>, <style> 등의 태그가 무시된다.

textContent
🔗 MDN - Node.textContent
"노드와 그 자손의 텍스트 콘텐츠를 표현합니다."
- <script>, <style>, display:'none' 등 모든 요소의 콘텐츠를 가져온다.
<-> 사람에게 보이는, 읽을 수 있는 요소만 가져오는 innerText와의 차이!!!- HTML을 파싱하지 않기 때문에 성능이 좋습니다
- XSS 공격의 위험이 없습니다

요약
속성의 이름처럼
innerHTML은 HTML 요소까지 읽고 파싱할 수 있다.
innerTEXT는 화면에 보이는, 우리가 읽을 수 있는 텍스트를 가져온다.
textContent는 모든 요소와 텍스트를 가져온다.

코딩하는 고구마 🍠 Life begins at the end of your comfort zone