Compressing high-resolution data through latent representation encoding for downscaling large-scale AI weather forecast model
Paper Review
VAE를 이용하여 데이터 압축시켰는데도 원본 데이터랑 거의 비슷한 결과가 나옴
fuxi 모델의 저해상도 25km (0.5도) 예측 -> 고해상도로 변환 할 때 u-net사용.
여기서 사용한 정답값은 HRCLDAS 데이터셋 (1km)로 사용
unet이 저해상도 fuxi 예측을 고해상도로 변환할 때 vae로 압축된 데이터를 사용하여 훈련이 가능하도록 함.
Variational Autoencoder, VAE
일반적으로는 인코더로 압축하고 디코더로 복원하는데 여기서 더 확장된 개념인 확률적(latent) 잠재 공간을 통해 데이터를 압축하고 생성함.
일단 encoder로 입력 데이터 x를 잠재 공간의 정규 분포로 매핑해서 평균/표준편차를 예측. 이 두개를 사용해서 잠재 벡터 z를 샘플링한다.
z를 생성하기 위해서는, 평균/표준편차를 통해 샘플링한다. 샘플링은 reparameterization trick을 사용한다.
z를 입력으로 받아, 원본 데이터랑 유사한 출력을 생성한다.
'잠재 공간이 정규 분포를 따르도록'학습하게 되는데, 여기서 reconstruction loss, LK divergence loss를 최소화한다.
이게 내가 알고있던 내용이고, 여기 논문에서 나오는 건
인코더에서 잠재 벡터로 변환하기 위해 resent, downsampling 블록으로 구성되었다. 여기서 swish 활성화 함수랑 그룹 정규화를 통해 더 정교하게 압축함.
잠재 백터 샘플링은 똑같은듯
디코더에서는 업샘플링과 컨볼루션 을 통해서 재생성하는데, upsampling을 위해 Bilinear interpolation을 사용한다.
파인 튜닝도 추가함.

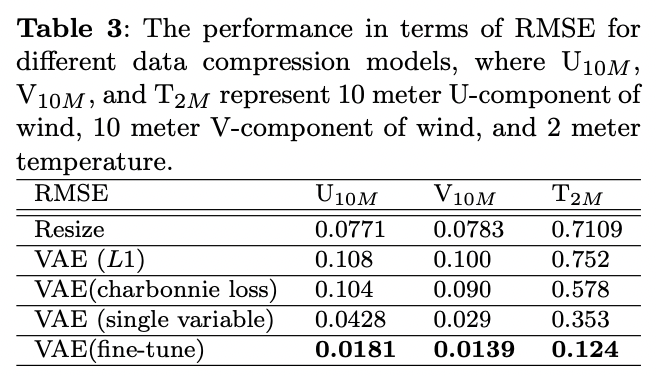
vae fine tuning이 rmse기준에서 우수함.
결과를 보면
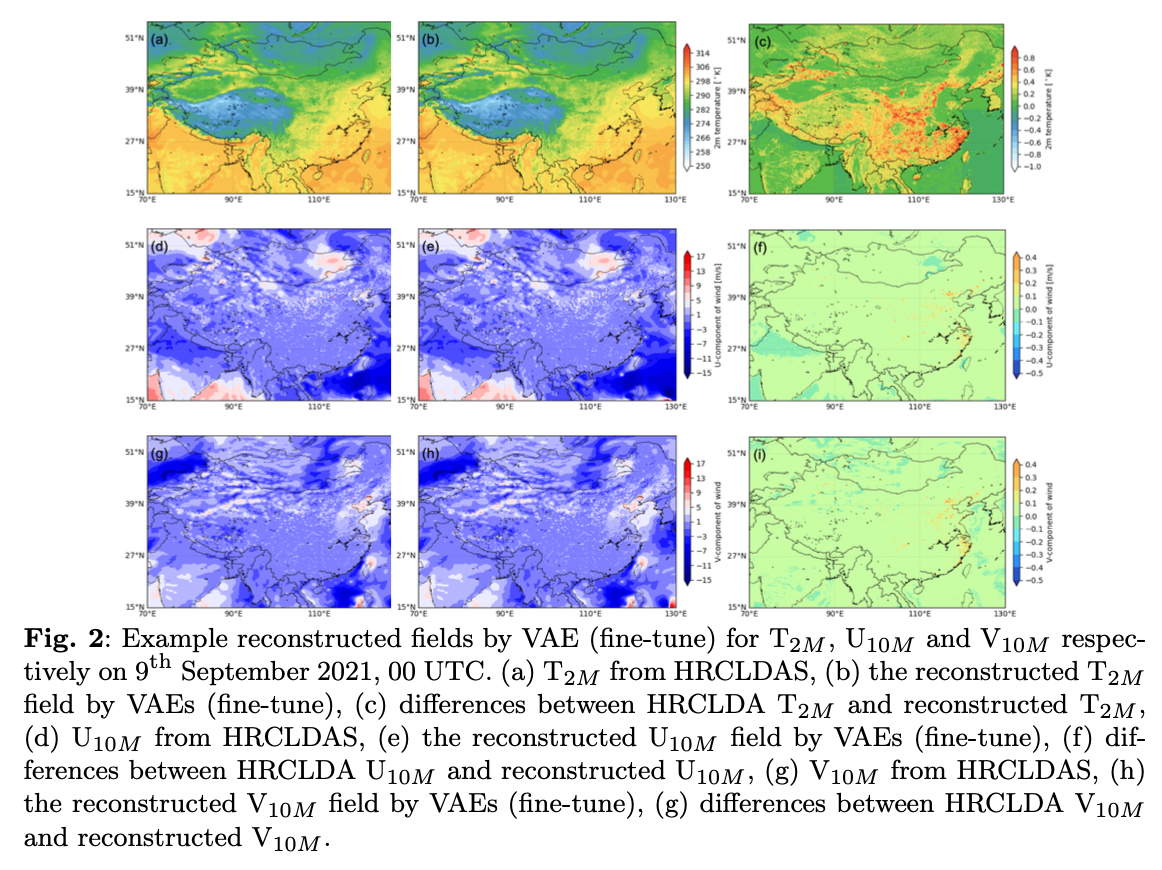
a가 HRCLDAS이고 b가 VAE fine tuning한거 c가 차이
인데 뭐 거의 비슷 따이
Limitations
- 지형 데이터 미반영 : 히말라야 등 고도 변화가 큰 곳에서 특징 포착 못함
- 소규모 패치 단위로 학습하고 복원하는 과정에서 아티팩트 발생했음
- 압축하면서 정보손실 .. 스케일이 더 크면 더 감소할 수 있음. 근데 이 논문에서는 큰 영향을 미치지 않는다고 함.
Overall...
0.25도도 높은데 1km까지 할 수있다니 ...
근데 뭐 성능은 비슷하다 하니...
추가적으로 지형 정보나 ...
아니면 GAN 기반 기법이랑 결합해서 다운스케일링 하는 모델
등등도 되지 않을까
