- Image에 대한 correlation → sliding window와 filter의 원소별 곱 → 합
- deep learning에서 말하는 convolution은 사실 correlation
Fully-connected layer vs Convolutional Layer Lv.1
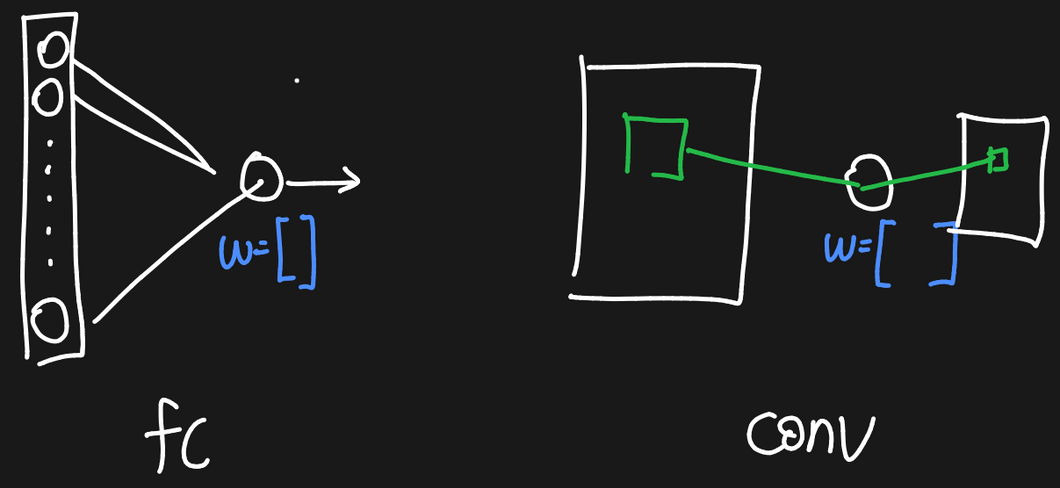
- Fully-connected layer
- 입력이 개가 있으면 neuron에 개 전체가 입력됨
- 이를 위해서 weight의 개수는 입력의 개수와 동일
- 모든 와 를 서로 곱하고 이 값들을 모두 더함
- weight는 벡터
- Convolutional Layer
- 뉴런에 이미지 전체가 입력되는 것이 아니라, 이미지의 window가 입력 → 이 window에 대하여 하나의 값이 출력(초록색)
- 이렇게 입력되는 초록색 입력을 receptive field라고 부름
- convolutional layer의 입출력
- 입력: 이미지
- 출력: 이미지(뉴런이 이미지를 입력받아 만드는 출력)
- weight는 행렬
- 뉴런에 이미지 전체가 입력되는 것이 아니라, 이미지의 window가 입력 → 이 window에 대하여 하나의 값이 출력(초록색)
Fully-connected layer vs Convolutional Layer Lv.2
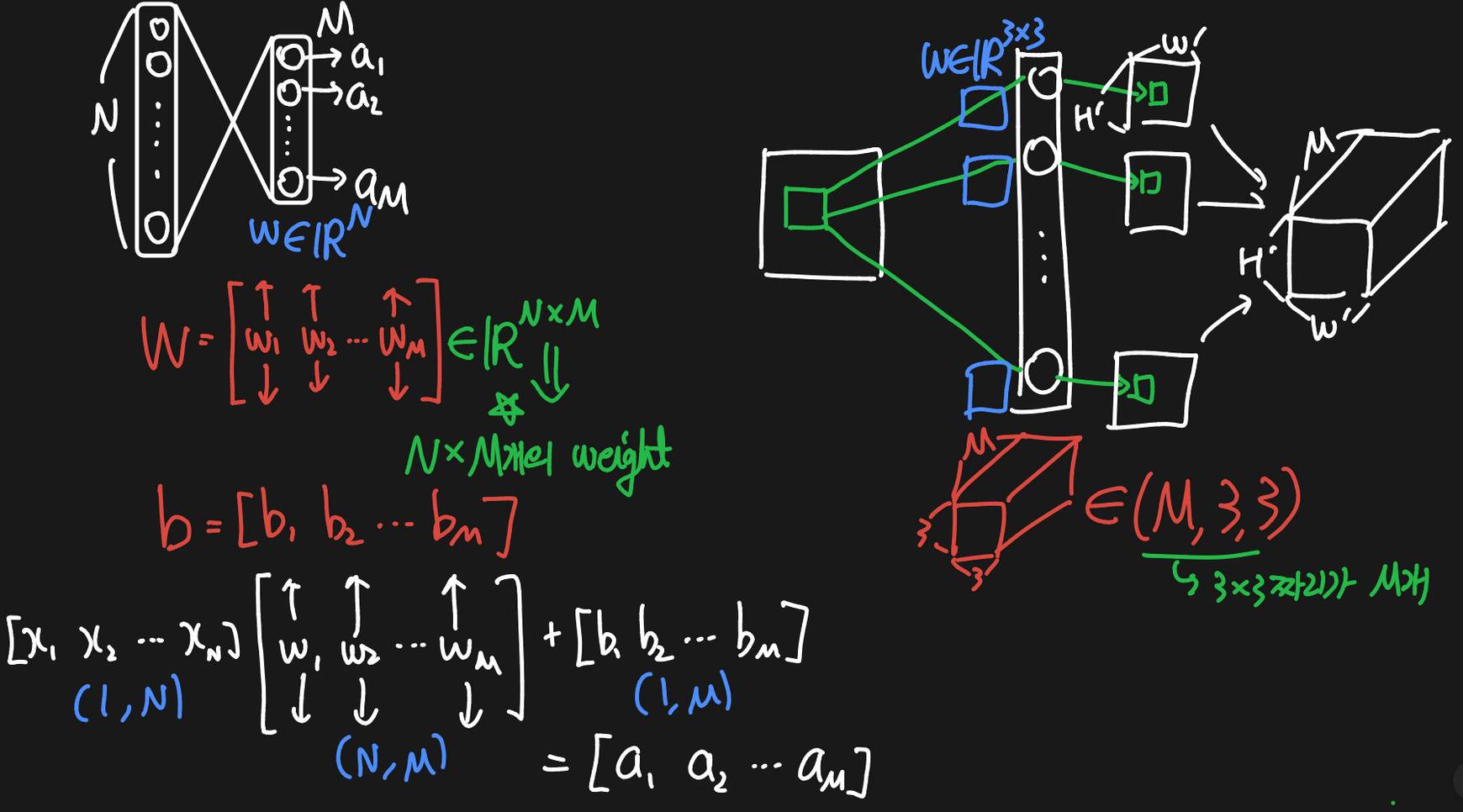
- convolutional layer의 입출력
- input:
- output:
- → filter의 개수
코드 실습
import torch
import torch.nn as nn
# in_channels=1 -> 흑백 이미지 입력
# out_channels=4 -> filter 4개
# kernel_size=3 -> (3, 3) filter
conv = nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3)
input_ = torch.randn(1, 10, 20) # (10, 20)의 흑백 이미지
print(f"input shape: {input_.shape}\n")
print("Parameter Shape:")
print(f"weight: {conv.weight.shape}") # (4, 3, 3)
print(f"bias: {conv.bias.shape}\n") # (4,)
output = conv(input_)
# H' = H - F + 1 = 10 - 3 + 1 = 8
# W' = W - F + 1 = 20 - 3 + 1 = 18
print(f"output shape: {output.shape}")LeNet5
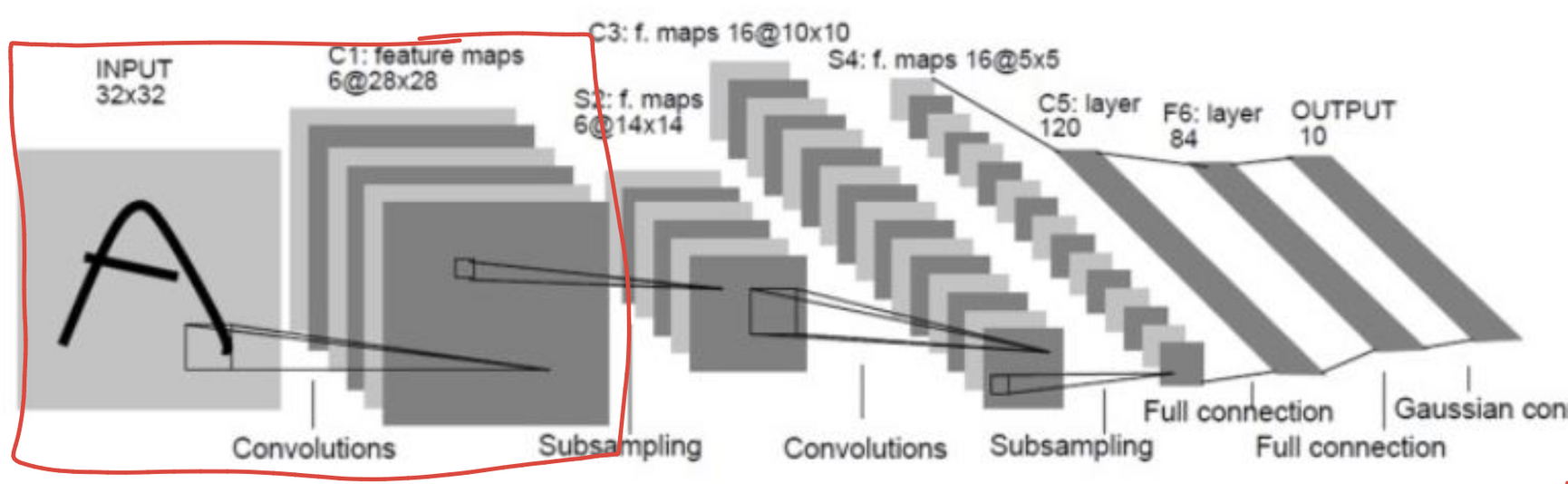
import torch
import torch.nn as nn
conv = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
input_ = torch.randn(1, 32, 32) # (1, 32, 32)
print(f"input shape: {input_.shape}\n")
print("Parameter Shape:")
print(f"weight: {conv.weight.shape}")
print(f"bias: {conv.bias.shape}\n")
output = conv(input_)
print(f"output shape: {output.shape}") # (6, 28, 28)LeNet5의 첫번째 layer까지만 구현해보기
- Object
- Model에 nn.Conv2d 써보기
- forward에 출력함수 써보기
import torch
import torch.nn as nn
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv1_act = nn.Tanh()
def forward(self, x):
print(f"input: {x.shape}")
x = self.conv1_act(self.conv1(x))
print(f"after conv1: {x.shape}")
return x
model = LeNet5()
test_input = torch.randn(1, 32, 32)
output = model(test_input)Fully-connected layer vs Convolutional Layer Lv.3
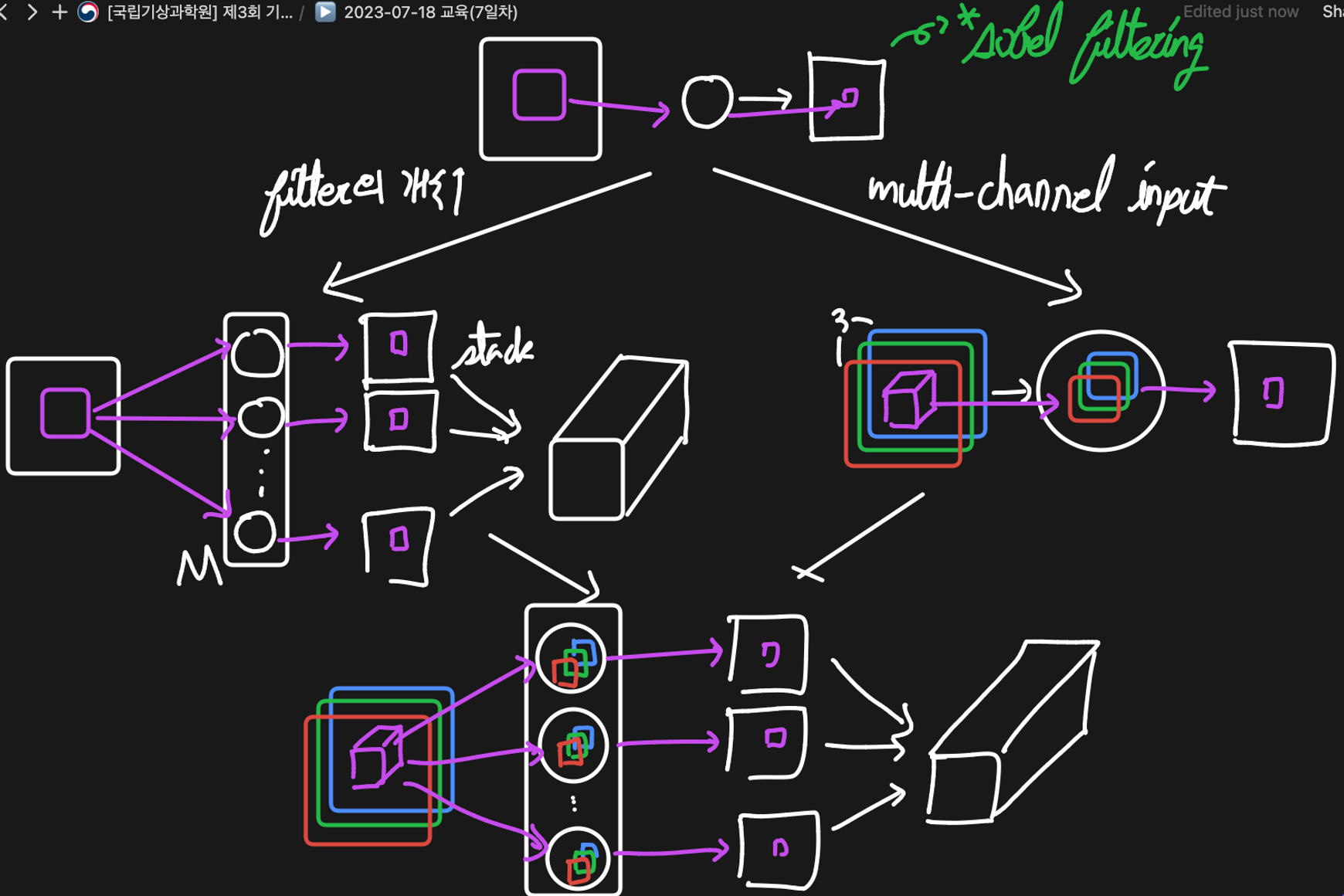
입력 채널이 여러개인 경우(예. 컬러 이미지가 들어올 경우)
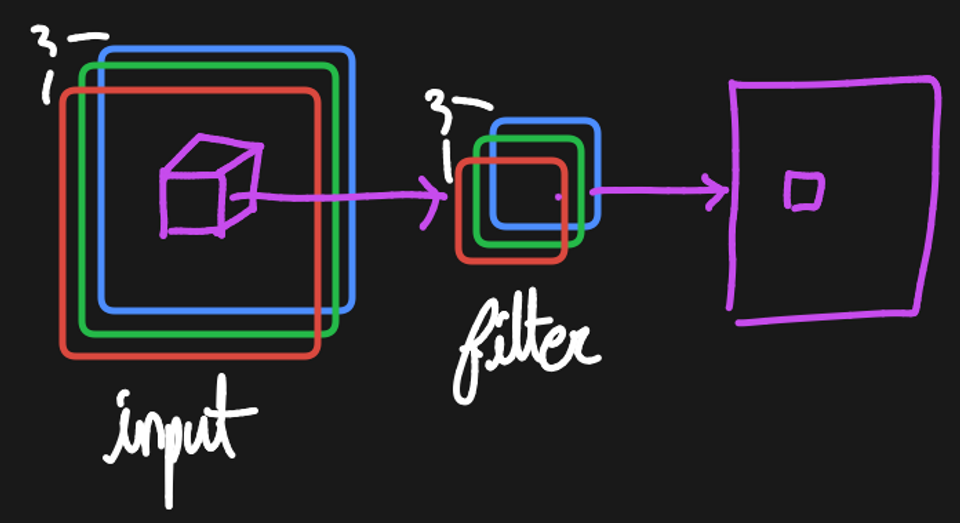
- 핵심
- 입력의 채널만큼 필터도 같은 개수의 채널을 가진다. ⇒ 이미지 채널 수 = 필터 채널 수
- 여러 개의 채널을 가지더라도 (patch ~ filter의 원소별 곱셈 후 총합)의 개념은 변하지 않기 때문에 1장의 이미지를 출력
Convolutional Layers
Code
import torch
import torch.nn as nn
conv = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
input_ = torch.randn(6, 32, 32)
print(f"input shape: {input_.shape}\n")
print("Parameter Shape:")
print(f"weight: {conv.weight.shape}") # [16, 6, 5, 5]
print(f"bias: {conv.bias.shape}\n") # [16]
output = conv(input_)
print(f"output shape: {output.shape}") # [16, 28, 28]LeNet5 Convolutional Layer 만들기
import torch
import torch.nn as nn
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv1_act = nn.Tanh()
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
self.conv2_act = nn.Tanh()
self.conv3 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
self.conv3_act = nn.Tanh()
def forward(self, x):
print(f"input: {x.shape}")
x = self.conv1_act(self.conv1(x))
print(f"after conv1: {x.shape}")
x = self.conv2_act(self.conv2(x))
print(f"after conv2: {x.shape}")
x = self.conv3_act(self.conv3(x))
print(f"after conv3: {x.shape}")
return x
model = LeNet5()
test_input = torch.randn(1, 32, 32)
output = model(test_input)Stride
- 이미지에 sliding-window가 한 칸씩 이동하면 너무 연산량이 많다ㅠㅠ
- 이미지에서 두 픽셀씩 이동한다고 해도 성능에는 차이가 없을 것 같다.
- 두 마리 토끼(연산량과 성능)를 잡는 방법 → sliding-window가 2칸씩 뛰기
- 더 많은 칸을 뛸 수도 있음
- filter size가 3x3이 아니라 11x11라면, 7칸씩 뛰어도 괜찮을 것 같다 - Sliding-window가 몇 칸씩 뛰는가 → stride
- stride=2 → 2칸씩 뛴다 - stride의 영향
- stride가 증가할수록 → 더 성큼성큼 뛴다. → 연산량이 팍팍 줄어든다 → output image size가 줄어든다.
- 잠재적으로 중요한 feature들을 놓칠 위험성이 있다. → 성능이 떨어질 위험성이 있다.
- stride가 작을수록 → 더 촘촘히 검사 → 연산 load가 너무 크다 → output size도 거의 변화가 없다
- 중요한 feature를 놓칠 가능성이 적다. - Convolution이 진행될 때
- stride=2 이상일 때, 오른쪽 또는 아래로 더 이동하지 못하고 멈추는 경우가 발생할 수 있다.
Padding
- convolution은 태생적으로 input image보다 output image의 size가 줄어든다.
- filter의 center point가 양 끝에 올 수 없기 때문에
- 원본 주변에 0을 한 칸씩 두른다면?? → filter의 center point가 원본에 양 끝까지 올 수 있음
- input size = output size
- 이미지 주변에 특정 값을 추가하는 것 → padding
- 특히 0을 추가하면 zero-padding
- Convolutional layer에 들어오기 전에 input을 미리 바꾸는 것
IO Shape Formula
- IO Shape Formula
- : input의 height, width
- : output의 height, width
- : filter size
- : padding
- : stride
- Quiz
- 일 때 input size와 output size가 같기 위한 값 = 1
- 일 때 input size와 output size가 같기 위한 값 = 2

뜬금없지만 세계여행이 꿈입니다.
항상 좋은 글 감사합니다.