Machine_Learning
1.Python Basics with Numpy

sigmoid_derivative(x)=f(x)(1-f(x))(length, height, 3)를 넣으면 벡터값(length x height x3, 1)을 리턴해주는 함수axis = 1, keepsdim =1 에 대한 설명은 여기 참고하면 도움이 된다.
2.Logistic Regression with a Neural Network mindset

아래서 사용하게 될 "data.h5" 데이터셋은cat (y=1)과 non-cat (y=0)으로 레이블된 m_train 트레인셋cat (y=1)과 non-cat (y=0)으로 레이블된 m_test 테스트셋각각의 이미지는 (num_px, num_px, 3)의 shape을
3.Planar data classification with one hidden layer

여기서는 2-클래스 데이터 세트인 "flower"를 사용할 것이다. 위 코드를 실행시켜 시각화하면 아래와 같이 출력된다.X와 Y가 어떻게 생겼는지 확인해보자.clf = sklearn.linear_model.LogisticRegressionCV();clf.fit(X.T,
4.Building Deep Neural Network : step_by_step.ver

대략적인 순서를 적어보자면,처음에 parameters을 초기화 해 준 다음, ReLU Forward->Sigmoid Forward에 넣고 Loss를 계산해 준 후, Backward에 넣어서 learning_rate값과 함께 parameters을 업데이트 해 준다. 위
5.Deep Neural Network-Application

여기에서는 각각의 정의된 함수의 코드를 설명하지 않는다. 함수의 내용을 알기 위해서는 이전 글을 참고하길 바란다.이전 글에서 설명했던 함수들을 가지고 전체 DNN모델을 만들어보자. 잘 이해했다면 이번 내용은 어렵지 않다.이번 글에서는 "고양이 vs 안고양이" 데이터셋을
6.순환 신경망 Recurrent Neural Network(RNN)

RNN은 기본적으로 '시간 개념이 있는 데이터'들을 처리하기 위한 신경망이다. xt는 현재의 입력으로써, 입력을 받은 후 Cell에서 루프를 사용하여 입력에 대한 출력값을 다시 입력으로 사용하게 된다. 따라서 yt는 과거와 현재의 정보를 동시에 반영한 출력값이다.
7.Initialization (with blue/red dots in circles dataset)

Neural Network를 하면서 맨 처음에 하는 일, weights와 bias를 초기화하는 일에 대해 조금 더 깊이 알아보려고 한다. 여기서 weight와 bias를 잘 초기화한다면, 조금 더 빨리 원하는 결과에 도달할 수 있을 것이다.만약 parameter들이 좋
8.RNN Language Model (char 단위)

아직 이 블로그에선 언급한 적이 없지만, NNLM (Neural Network Language Model)이라는 모델이 있다. 이 모델에 대해서 간략하게 설명하자면, 문장의 단어들 중에서 사용자가 지정한 n개의 단어들만 입력받을 수 있다. 여기서 발생하는 문제점이 있
9.Regularization(L2 Regularization, Dropout)

이번 글에서는 정규화(Regularization)에 대해 알아보겠다.만약 우리가 가지고 있는 데이터가 그렇게 크지 않다면, overfitting이 될 가능성이 크기 때문에 overfitting되지 않게 하기 위해 Regularization을 꼭 해줘야 한다.왜 정규화가
10.Gradient Checking

Gradient Checking에 대해서 알아보자. 이는 back propagation의 검증을 위해 꼭 필요한 단계이다.먼저 1D Gradient checking부터 확인해보자.알고있는 1D 선형 함수를 생각해보자.세타라는 parameter가 있고, x를 input으
11.Simple RNN/LSTM 이해하기

이 글에서도 데이터를 가지고 실습을 하긴 했지만, 이 글에서는 보다 자세한 이해를 위해 설명하려고 한다.우선 RNN과 LSTM을 테스트하기 위한 임의의 입력을 만들어주자.이전 글에서도 언급했다시피, 오른쪽으로 갈 수록 안쪽 차원이 된다.Simple RNN에서는 이렇게도
12.Reuters News Classification (로이터 뉴스 분류하기)

이번 글에서는 kears.datasets안에 있는 reuters 데이터에 대해 분류해 보겠다.불러온 데이터셋을 트레이닝 세트와 테스트 세트로 나눠주자.모양을 확인해보자.8982개의 훈련용 뉴스 기사, 2246개의 테스트용 뉴스 기사,46개의 카테고리를 확인할 수 있다.
13.IMDB Classification (IMDB 이진 분류)

이번에는 이진 분류를 해 볼 것이다.이진 분류란, 어떤 데이터에 관해서 0이나 1로 분류되는 것을 말한다. tensor에서 제공하는 IMDB 리뷰 데이터를 가지고 분류해보자.데이터를 각각 X_train, y_train, X_test, y_test에 저장하자.궁금했던 것
14.ELMo

ELMo는 Embeddings from Language Model의 약자이다. 직역하면 "언어 모델로부터 얻는 임베딩" 이라고 해석할 수 있다. 이전에 배웠던 GloVe같은 경우는 play의 벡터값과 비슷한 것들에는 단순히 playing, game, played, pl
15.Optimization Methods

이전에는 Gradient Descent를 사용해서 parameter를 업데이트하고 Cost Function을 최소화했다. 이번에는 다른 Optimization Method를 통해 속도를 높이고 비용을 최소화하는 알고리즘을 배워보자.언제나 그랬듯, package먼저 다운
16.Multi-Kernel 1D CNN

우선 제목에서의 1D Multi kernel이 무엇인지 알아보자.위 그림은 커널이라는 행렬로 임베딩 행렬의 가장 맨 위 부터 가장 맨 아래까지 순차적으로 훑으면서 겹쳐지는 부분의 임베딩 행렬과 커널의 원소의 값을 곱하여, 모두 더한 값을 출력으로 한다. 위 그림의 예시
17.Intent Classification

이번에는 이전 글에서 설명한 Multi-Kernal 1D CNN을 가지고 의도 분류(Intent Classification)를 해 보려고 한다.의도 분류는 챗봇에서 주로 사용되는데, 예를들어 "주말에 문 여는 대치동 맛집 추천해줘"라는 문장의 의도는 "맛집 추천"이 될
18.Intent Classification

이전 글에서 의도분류에 대해서 설명하고, 영어 버전으로 실습을 해 보았다. 이번에는 한국어로 실습을 해보도록 하자. 그리고, 이전에는 멀티 커널 CNN으로 모델을 구축했었는데, 이번에는 LSTM으로 모델을 구축해볼 것이다. 패키지를 불러와주자.이번에는 한국어에 대해 전
19.POS Tagging with Bidirectional LSTM

이번 글에서는 양방향 LSTM을 이용해 품사 태깅을 해 볼 것이다. 양방향을 쓰게되면 문장의 처음과 끝 문맥을 잘 반영할 수 있게 된다.패키지를 다운받아주자.NLTK에서는 토큰화와 품사 태깅이 완료된 데이터를 불러올 수 있다.데이터를 tagged_sentences안에
20.Introduction to Tensorflow

이번 글에서는 넘파이를 사용하지 않고 프레임워크를 통해 더 간단하게 모델을 구축할 수 있는 방법을 소개하겠다.먼저 패키지를 다운받아주자.텐서플로우 2.3 버전을 사용할 것이기 때문에, 아래 코드를 통해 버전을 확인해주자.이하 버전이라면 다운받아 사용하면 된다.다운받아
21.Named Entity Recognition 개체명 인식

이번 글에서는 개체명 인식을 소개한다.개체명 인식은 대표적인 시퀀스 레이블링 태스크에 속하는데,시퀀스 레이블링이란 x1, x2, x3, ... ,xn에 대해서 y1, y2, y3, ... ,yn을 각각 부여하는 작업을 말한다.아래 예제 파일을 미리 가져와보겠다.각 단어
22.Named Entity Recognition with BiLSTM

이번에는 이전글의 두번째 버전으로 새로운 파일로 실습해보자.
23.Named Entity Recognition with BiLSTM + CNN

이번 글에서는 여기서 사용한 데이터셋과 전처리를 이용하여 다른 모델을 만들어 볼 것이다. 이전에서는 BiLSTM을 이용했지만 이번에는 BiLSTM과 CNN을 동시에 이용하여 만들어보자. 이번 내용에서는 단어(Word)와 글자(Character)의 차이를 헷갈리지 않도
24.Building RNN - step by step

오랜만에 쓰는... 공부글...패키지부터 설치해준다. 간단한 원리를 알아보는거라 넘파이만 사용한다.input Tx와 output Ty의 길이가 같다면, 기본적인 RNN모델은 아래와 같이 생겼다.RNN의 single sell구조를 확인해보자.가장 기본적인 RNN cell
25.Faster R-CNN Background

R-CNN전체적인 흐름이 궁금해서 논문 찾아보면서 정리해보려고...Object Detection (객체 탐지) : 시멘틱 객체 인스턴스를 감지 ex) 얼굴, 보행자 검출Classification + Localization : 시멘틱 객체를 찾았다. Object
26.Faster R-CNN Method and Results

핵심 : 하나의 unified 된 네트워크로 detection을 수행전체적으로이런 느낌인데, 순서를 설명하자면그렇다면 Fast R-CNN과 다른 점은 무엇일까이전 글에서도 설명했다시피,Fast R-CNN은 전체 영상을 CNN으로 받아 bounding box와 class
27.DL Day1

(딥러닝을 처음 배운다 ... 생각하고 정리하기)딥러닝 관점에서 생각하는 두 개의 일차함수가 서로 다른 함수인 이유:빨간색 그래프와 파란색 그래프가 다른 이유는?동일한 입력값->다른 출력값 을 갖기 때문여기서 공통점은 둘다 일차함수 y=ax+b 라는 것y=ax+b 여기
28.DL Day2

저번 시간에는 $y=a^x+b^$를 따르는 것 처럼 보이는 dataset을 만들고, 이에 따라 $\\hat{y}=ax+b$를 만드는 모델을 만들었다.어떻게? gradient based learning 을 이용해서 loss를 최소화하는 방향의 gradient로 a,b를
29.Backpropagation 코드실습
결과
30.인공 뉴런 개요
기지국에서 코드를 불러준다. "1 1 -1 -1 아 전화왔어"모든 핸드폰에서 자신이 "1 1 -1 -1"인지 같은 자리수끼리 더한 후 곱한다.가장 큰 수한테 전화가 온다=> "코릴레이션" 얼마나 유사한지 측정하기 때문에 배터리가 계속 닳는것즉, 조난을 당하면 바로 꺼야
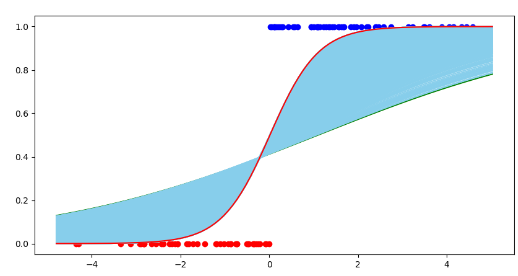
31.DL Day4
지난 글에서는 Sigmoid 에 대해서 살펴보았었다.Sigmoid는 로짓을 확률로 바꿔주는 함수!$$\\sigma\\left(x\\right)=\\frac{1}{1+e^{-x}}\\Longrightarrow\\frac{1}{1+e^{-\\left(ax+b\\right)
32.Binary Cross Entropy 도함수 구하기

저번 글에서 배웠던 $$J=y\\cdot -log(\\hat{y})+(1-y)\\cdot-log(1-\\hat{y})$$라는 Loss function이 있었다.이제 이 함수를 살짝 고쳐보자. 마이너스가 많으니 앞으로 뺀다!$$J=-y\\cdot log(\\hat{y
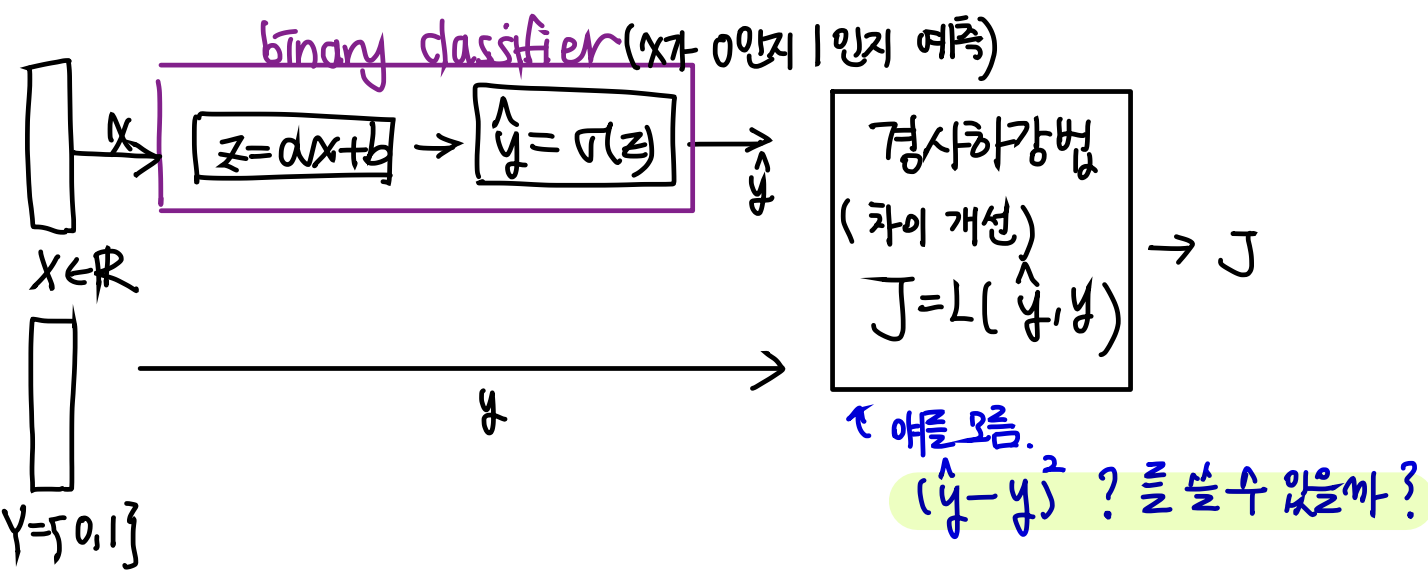
33.Backpropagation

지금까지 배운 내용을 생각해보자.input x를 binary classifier에 집어넣는다. 그리고 손실함수를 구한다음에 손실이 적어질 때까지 학습시킨다.전체적인 플로우는 이해했다.그렇다면 어떻게 학습시킬 것인가?사실, 마지막 단계까지 왔으면, 마지막 Loss함수에
34.Artificial Neuron

지난 글에서 Artificial Neuron에 대한 간단한 개요를 작성했었다.보고 오면 이해하는데 도움이 될 수도 있다.은 두 가지 함수로 이루어져 있다."Affine Function"↓"Activation Function"에서 inputdms $f(x1, x_2, ,
35.Hyperplane and Decision Boundaries of Hyperplane

우선 $y=ax+b$라는 그래프를 생각해보자.이 그래프는 좌표평면을 이등분한다.위 초록색 직선을 기준으로 만약 y가 x+2보다 크다면 위쪽 부분에, 작다면 직선 아래쪽 부분에 있을 것이다.특징을 적어보자.$\\mathbb{R}^2$안에 존재하면서 $\\mathbb{R}
36.실습 with MNIST Dataset

MNIST dataset은 사람의 손글씨(숫자 0~9)의 이미지를 가지고 있는 dataset이다.아래 그림처럼 생겼다.이 데이터의 정보는 아래와 같다28x28 gray scale image → width, height 모두 28픽셀Training data: 60000개
37.Cross Entropy 실습

데이터를 만들어보자. torch.randn을 이용하여 random numbers from a normal distribution with mean 0 and variance 1 을 가져온다.tensor(-0.6459, 0.8710, -0.4781, 0.6219, -
38.Softmax
저번 글에서 언급한 Multilayer Perceptrons에 대해서 마지막 레이어에서 affine function만 통과하면, 출력은 5개 출력인데 -무한에서 +무한까지 가능하다.만약 마지막에 Sigmoid를 넣으면 독립적인 값이 나와서 합이 1이 나오지 않는다.따라
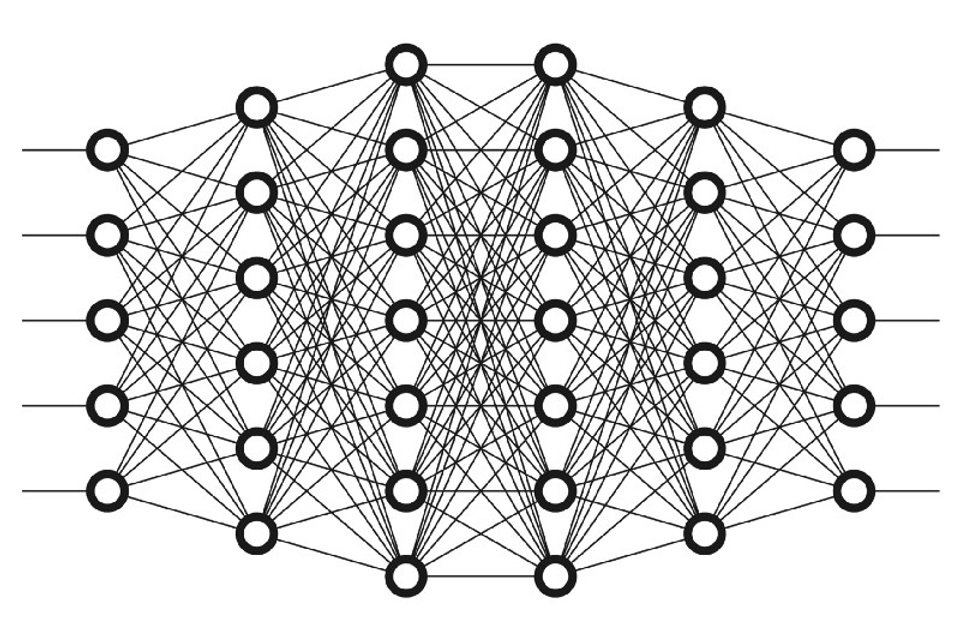
39.Neural Network 구현하기
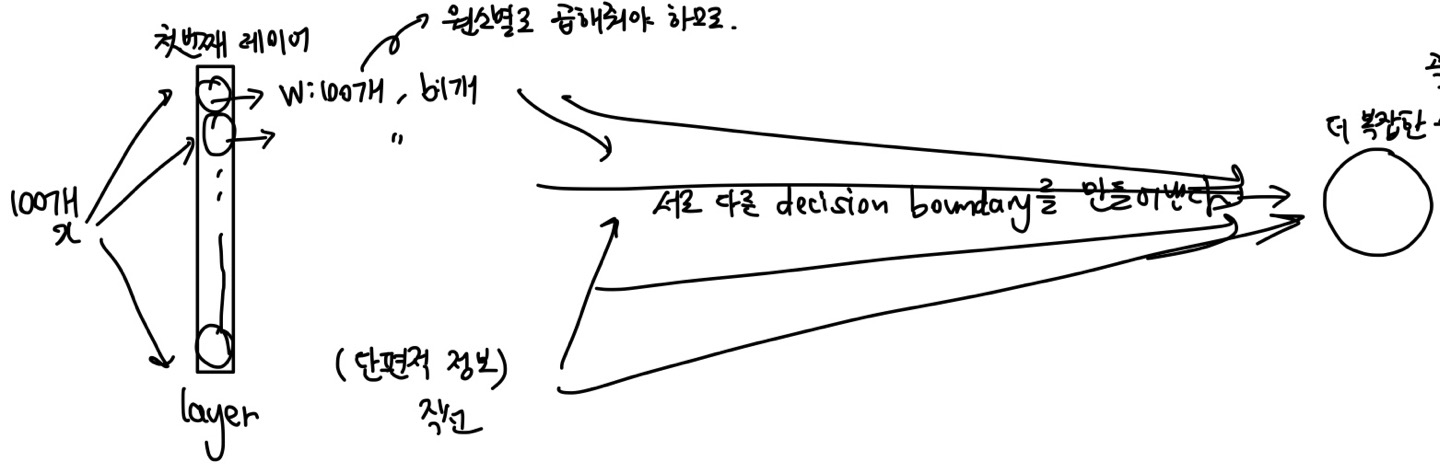
input : Flattened MNIST Image => (784, ) vector위 그림에서 x는 784개가 될 것이다.그리고 첫번째 레이어에서 뉴런이 128개를 넣으면, 128개의 필터가 있다는 뜻이다!각각의 뉴런들은 affine & sigmoid 를 거쳐서 각각
40.Multilayer Perceptron 학습시키기

데이터가 다운로드 되고 데이터 정보를 출력해 볼 수 있다.저번 글에서 해당 모델에 대한 설명을 적어놓았다.
41.MNIST on MLP 실습

batch size : 한 번에 학습을 할 때 몇 개의 이미지를 사용할 것인가 \- 지금 쓰는 이미지는 크기가 작아서 괜찮지만 나중에는 이미지 파일 크기가 커지면 이것저것 고려할게 많아진다.LR : Learning Rate : $w:=w-LR\*dJ/dw$에서 gra
42.Convolutional Layer
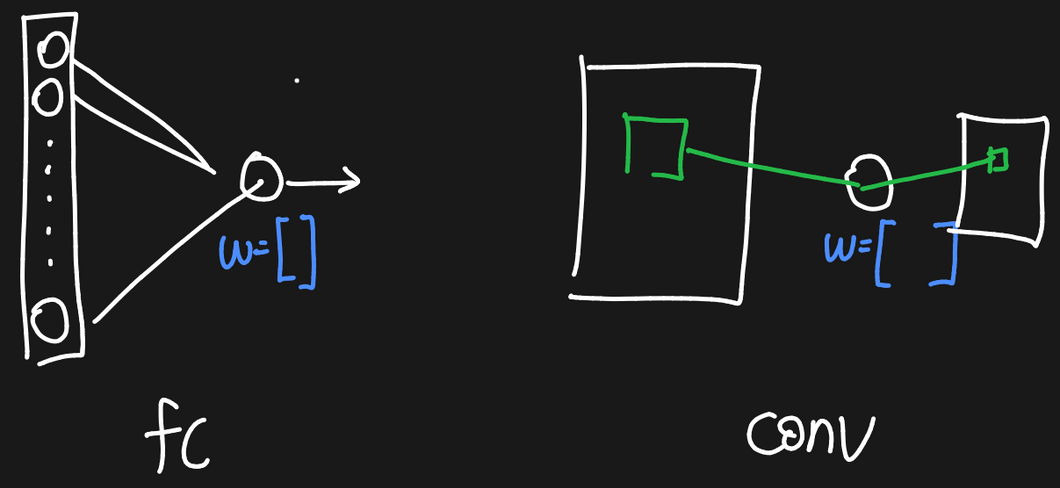
Image에 대한 correlation → sliding window와 filter의 원소별 곱 → 합 \- deep learning에서 말하는 convolution은 사실 correlation Fully-connected layer입력이 $N$개가 있으면 neur
43.Pooling Layer
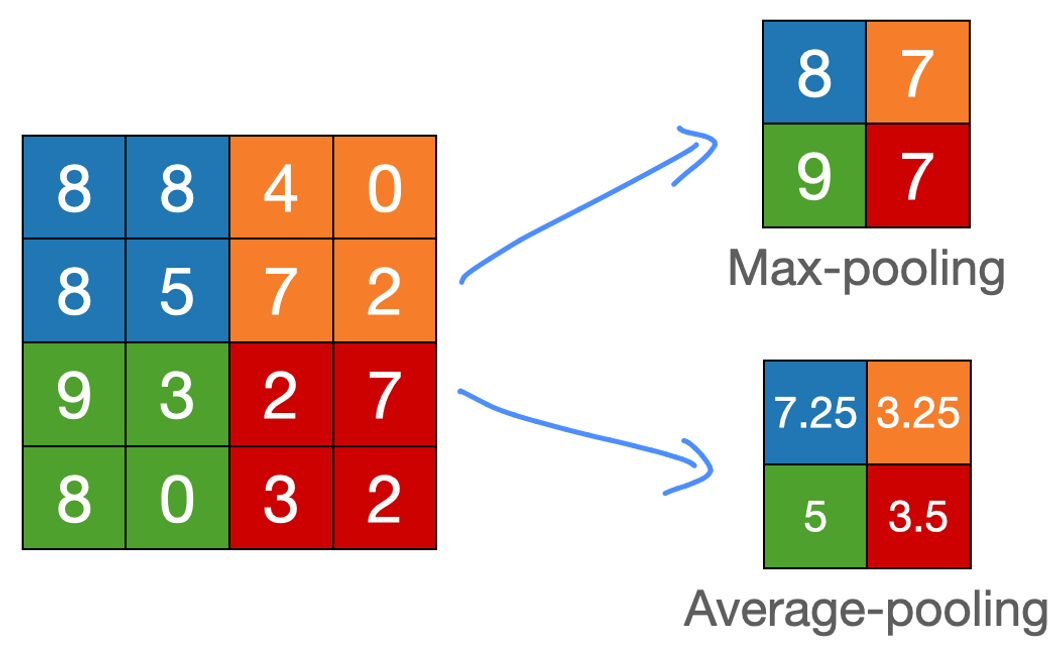
2x2 filter와 stride=2인 상태 → 원소별 곱하고 총 합 X → window에 들어있는 값들의 최댓값/평균일반적으로 $F = 2,\\; S=2$(non-overlapping window), $P = 0$계산의 편의를 위해 $H$는 2의 배수라고 가정$$\\
44.LeNet5 구현하기
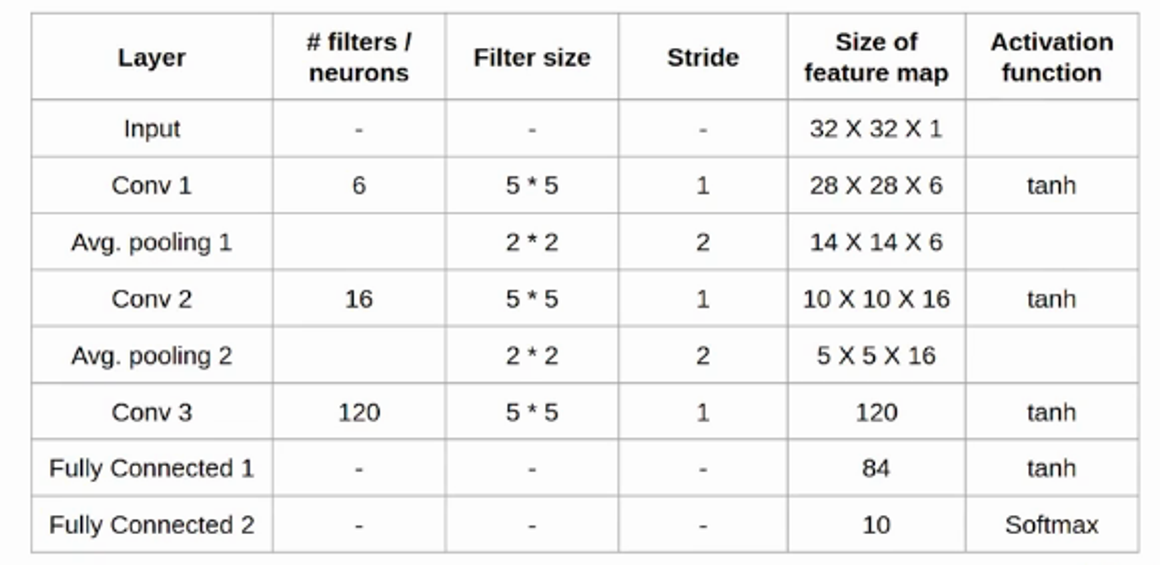
Architecture Table Code