Recap of Accomplishments
2023-09-18
- 다른 지역에서의 power분포 확인 후 분포가 좀 고른 지역만 선발
locations = ['영암에프원태양광b', '[서인천]발전부지내 태양광 1단계',
'[서인천]발전부지내 태양광 2단계', '군산복합2단계태양광',
'삼랑진태양광#1', '삼랑진태양광#2', '수질복원센터태양광']

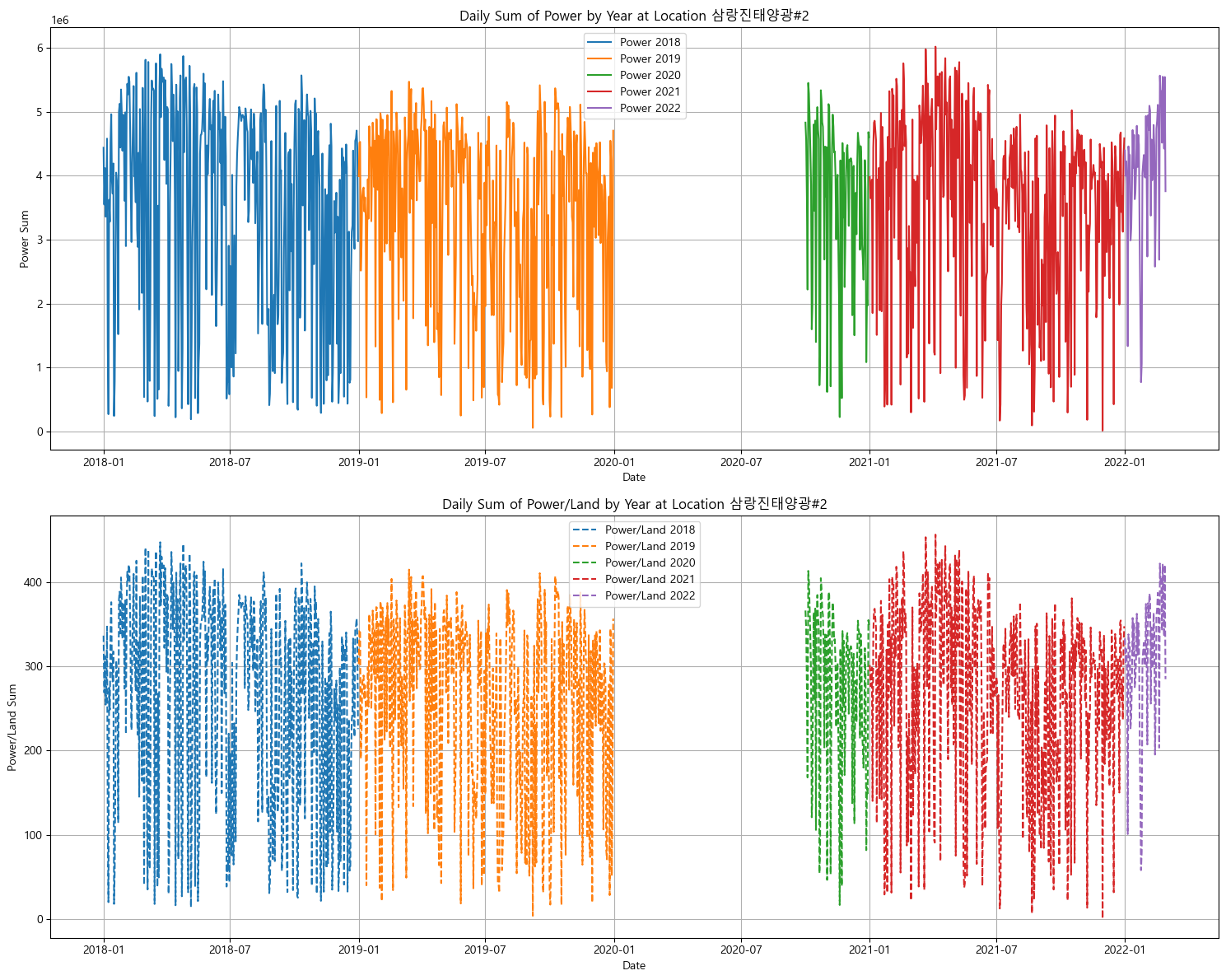
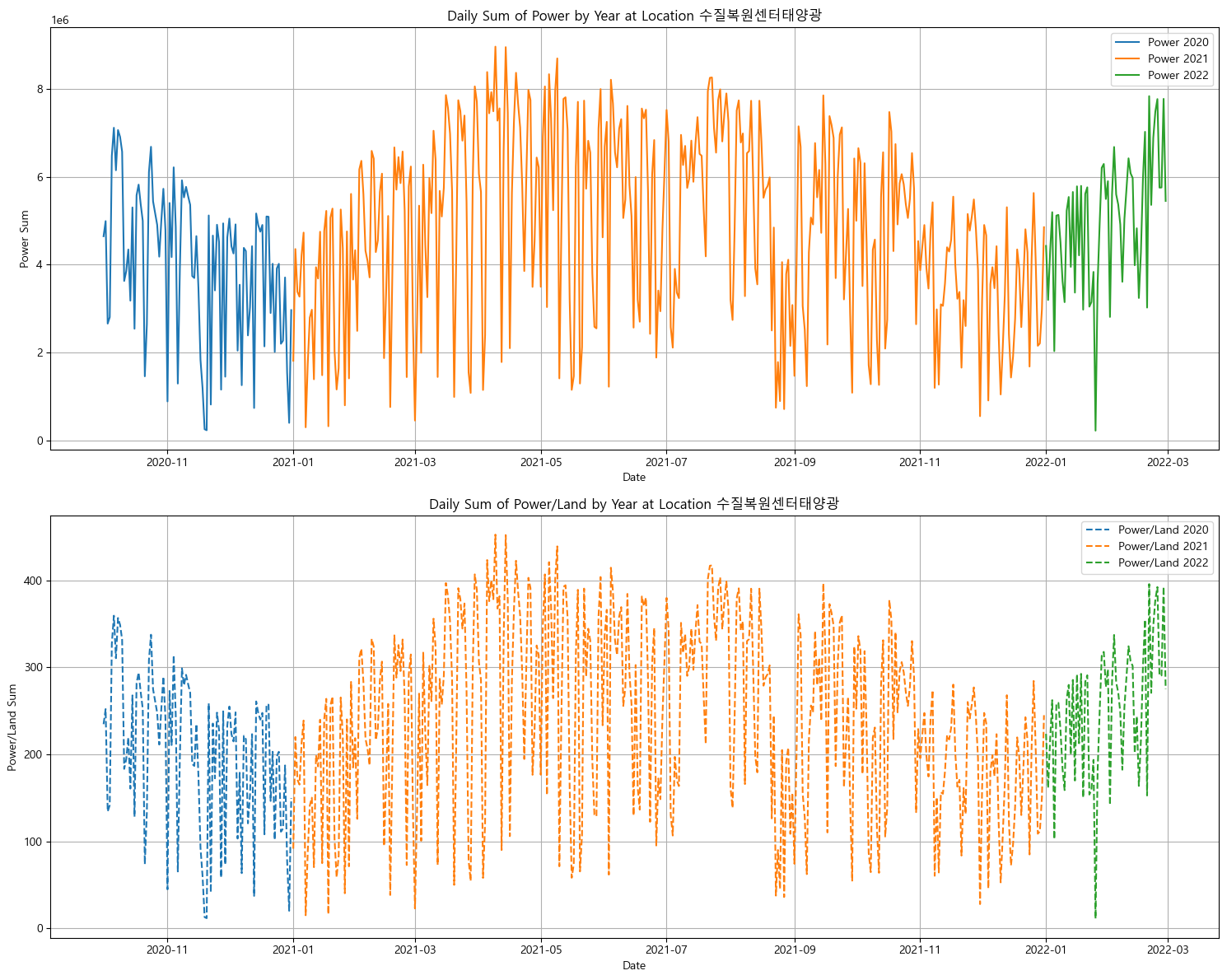
-
분포가 이상한 지역
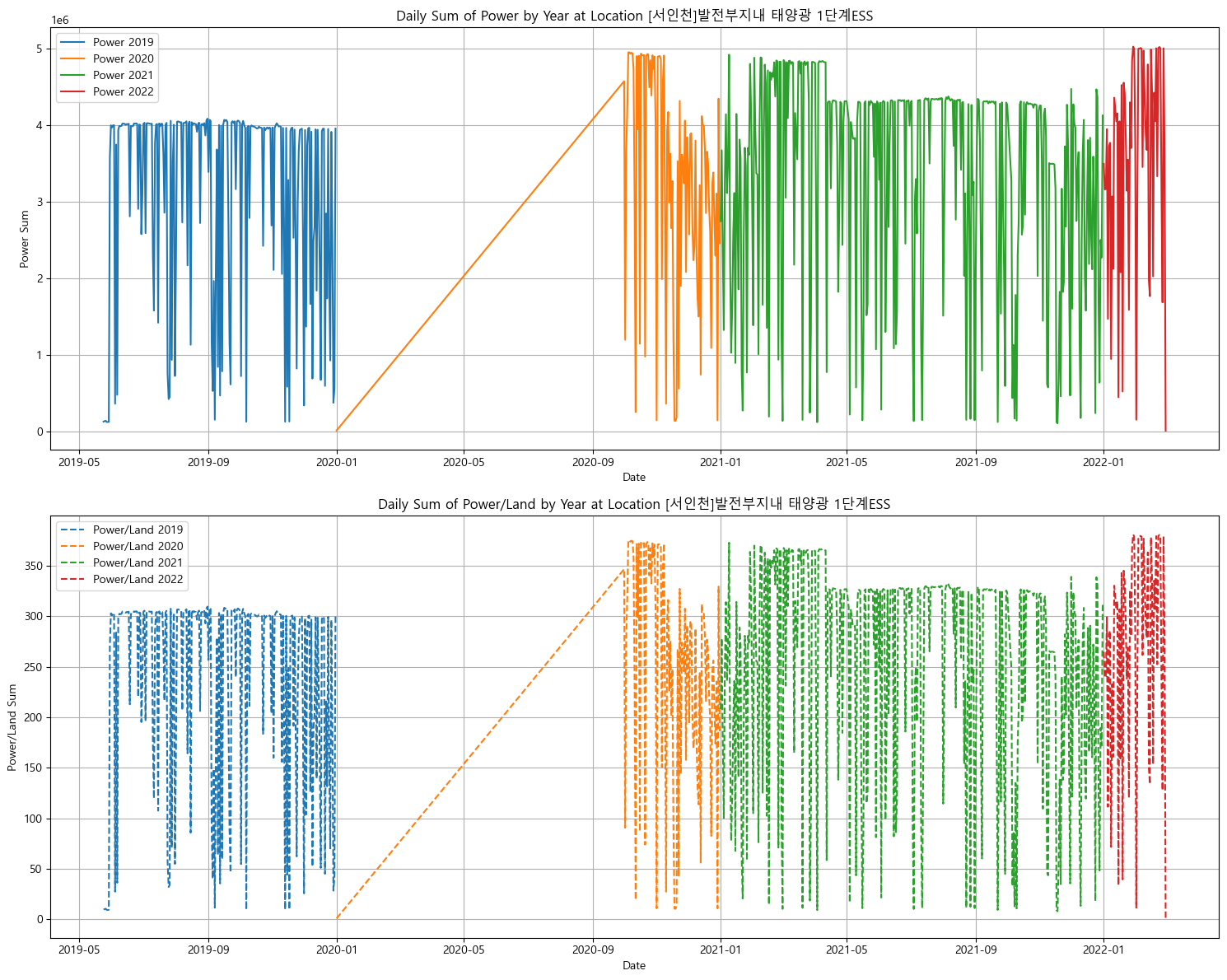
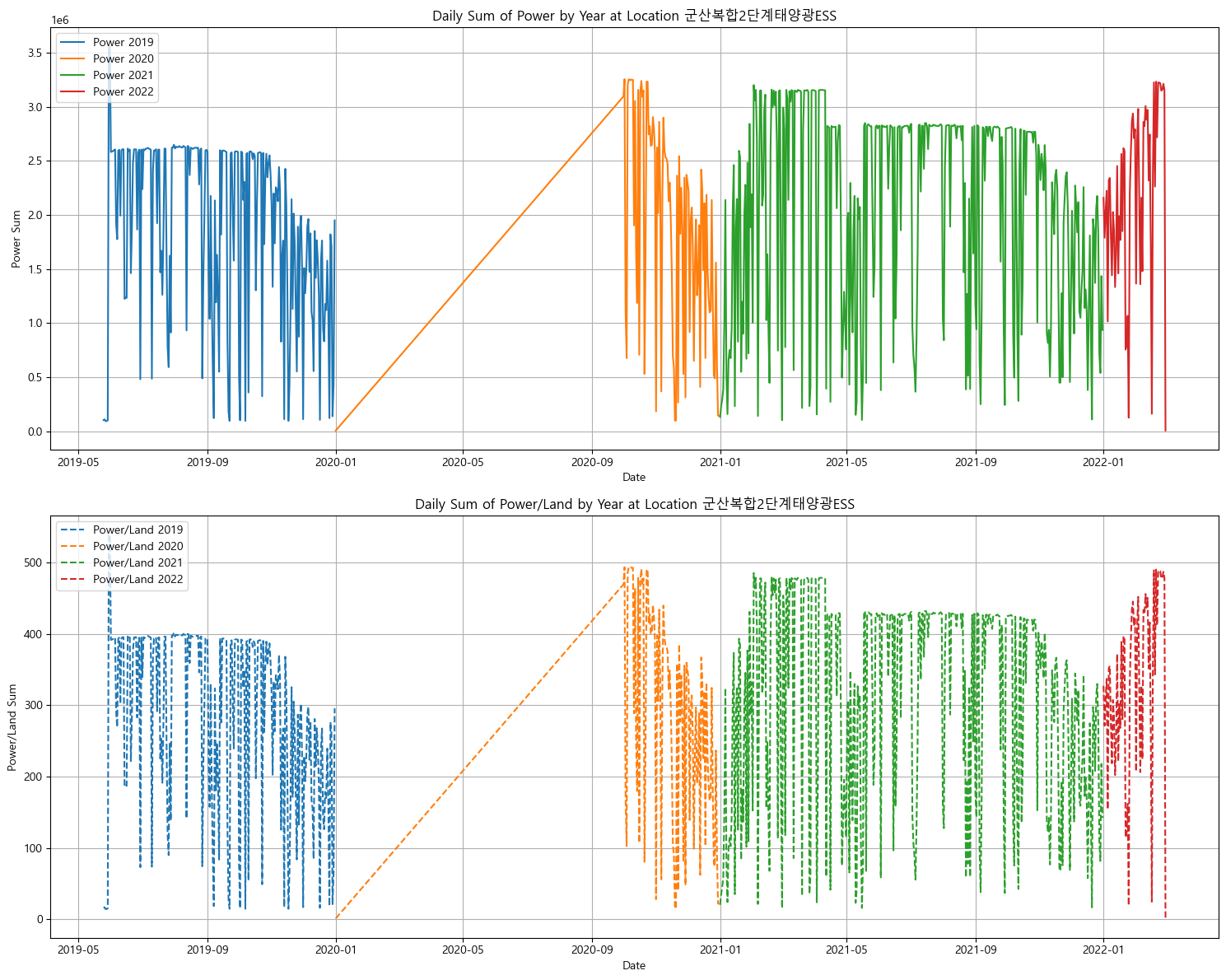
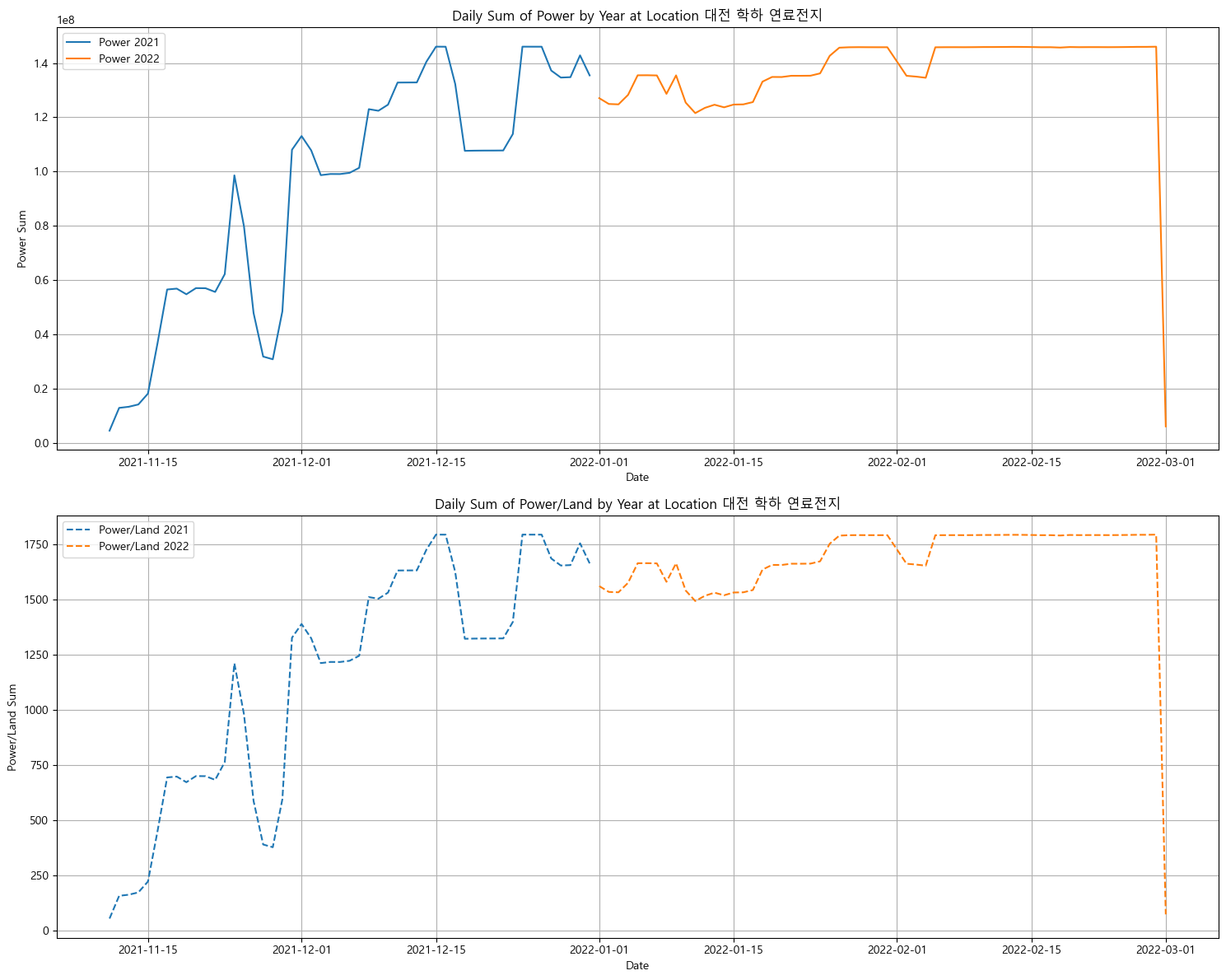


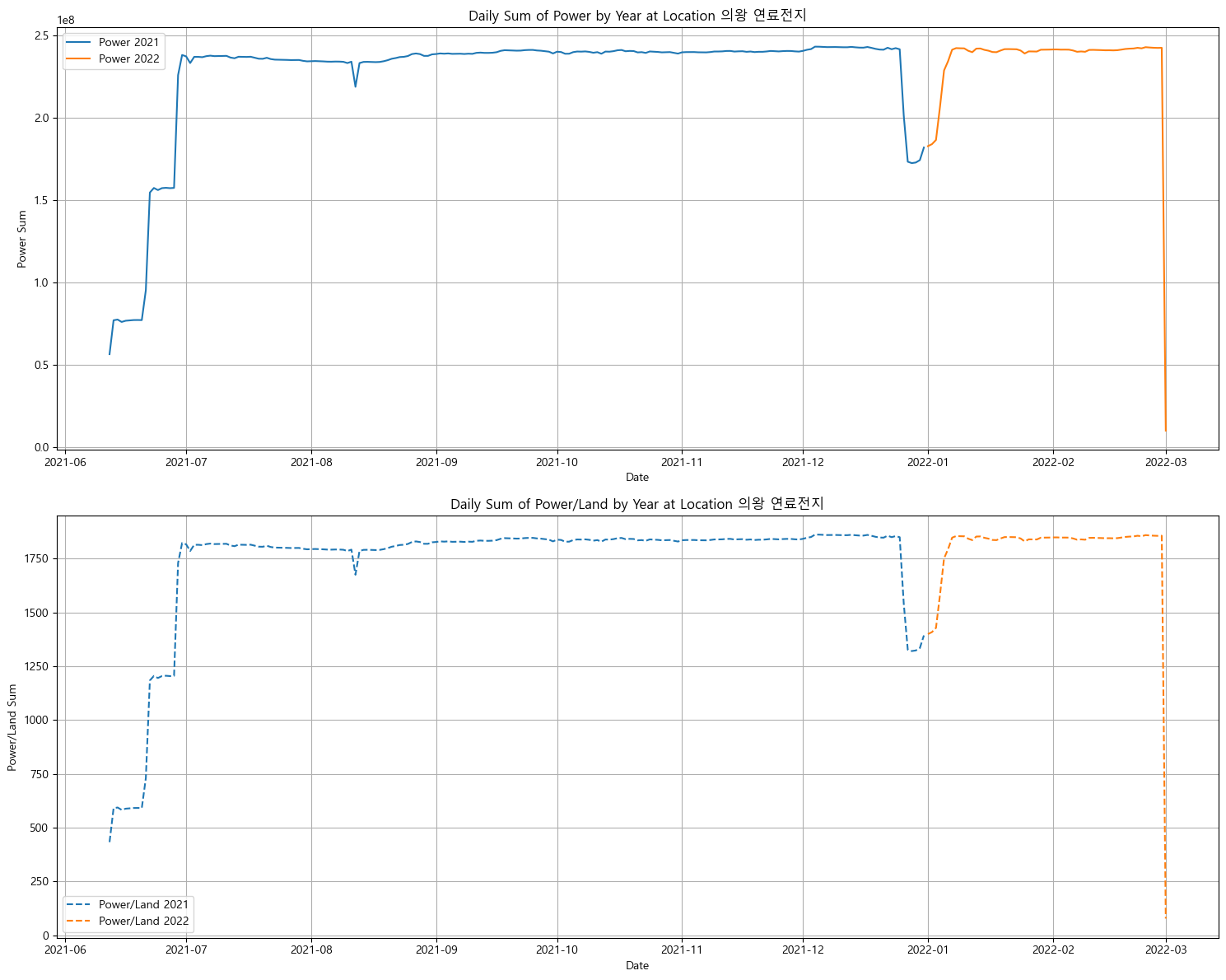
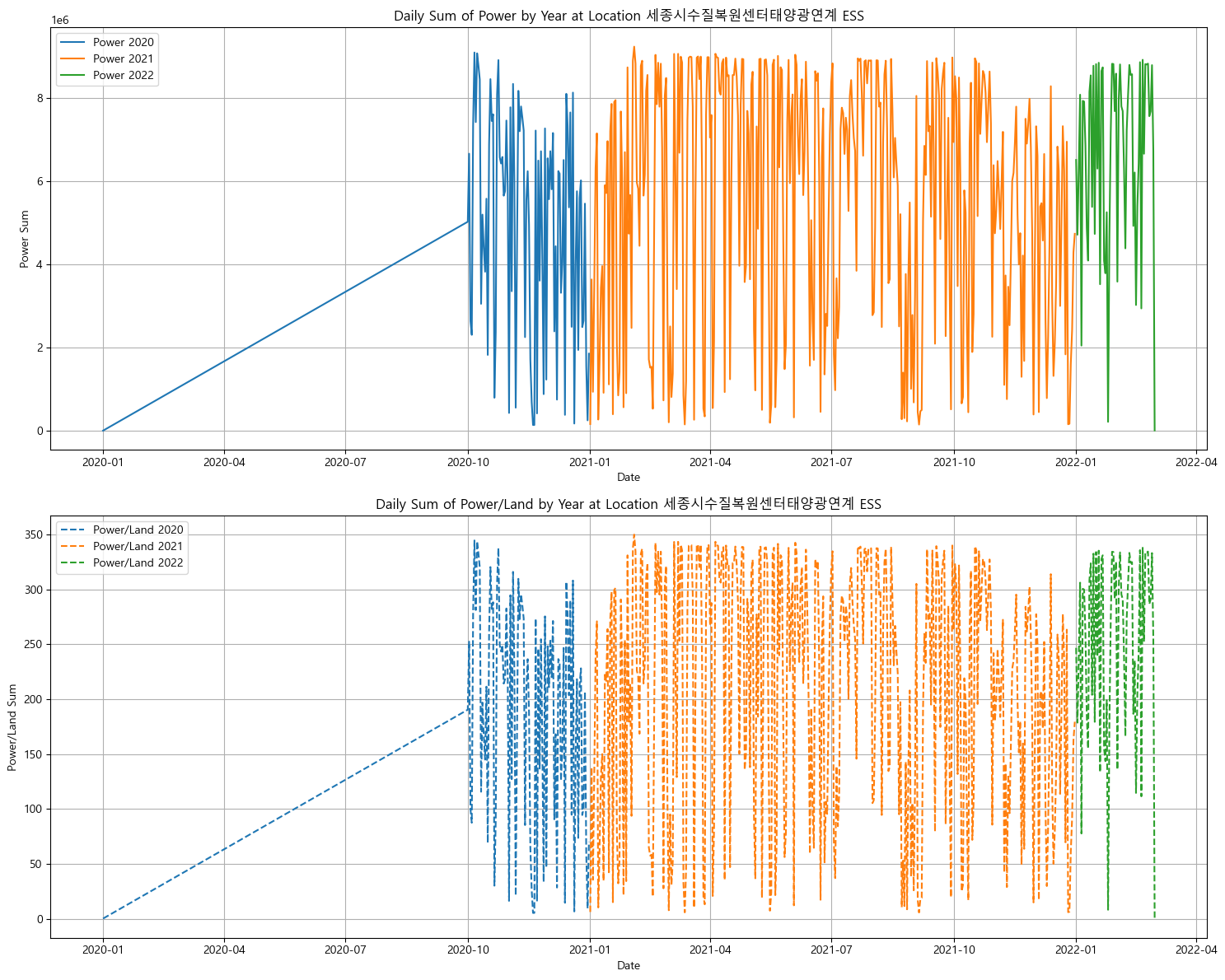

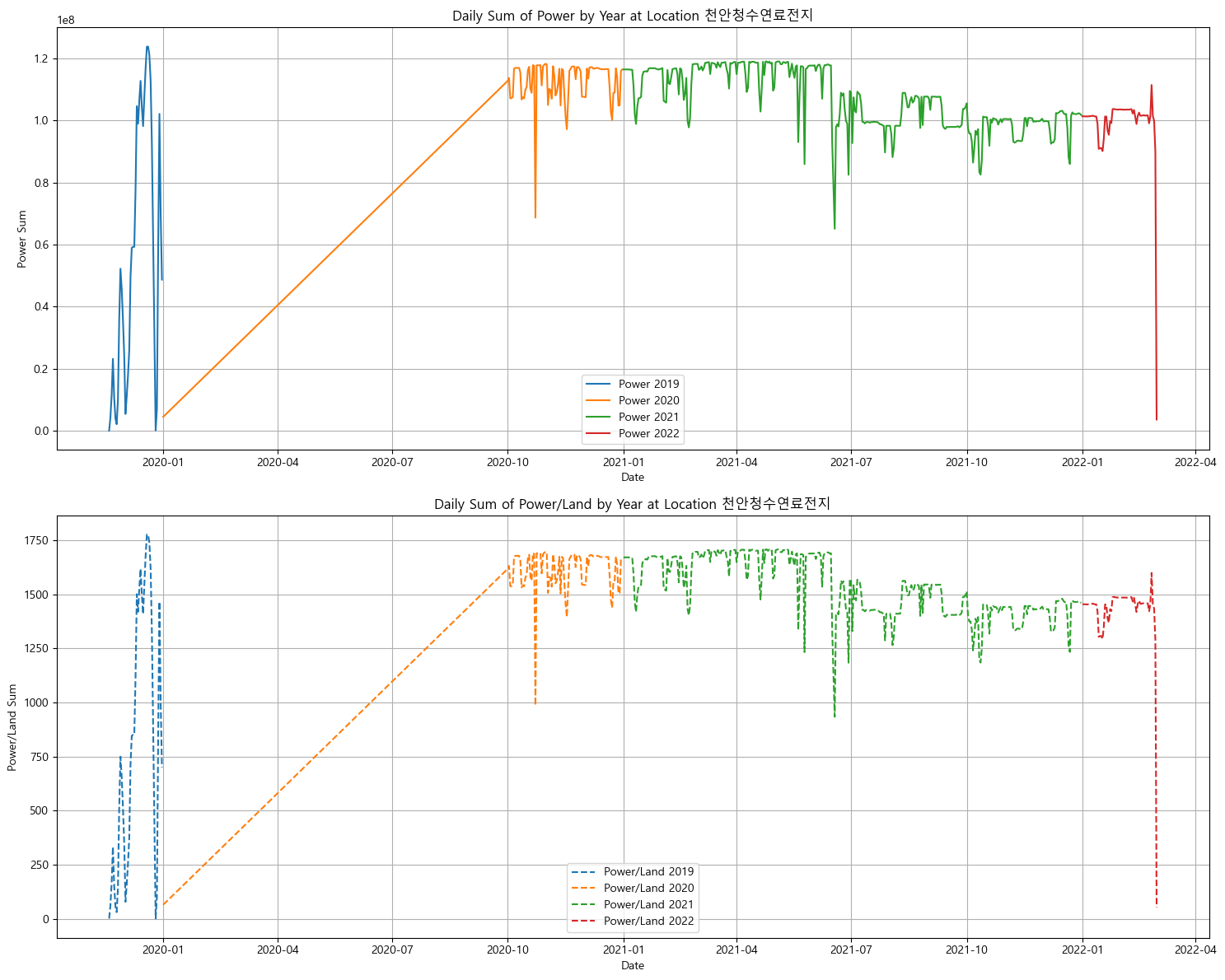
풍력 데이터도 섞여있다고 하고 중간에 비어있는 날짜가 너무 많다... 다 제거하였음. -
오늘부터 백준 문제를 다시 열심히 풀어보기로...
2023-09-19
- 실험 첫번째 : 한 지역 데이터를 test로, 나머지를 train으로 해서 각 지역마다 어떻게 결과가 나오는지 돌려봤다.
- NGBoost 모델
영암지역 앞부분은 꽤 잘 맞는다.


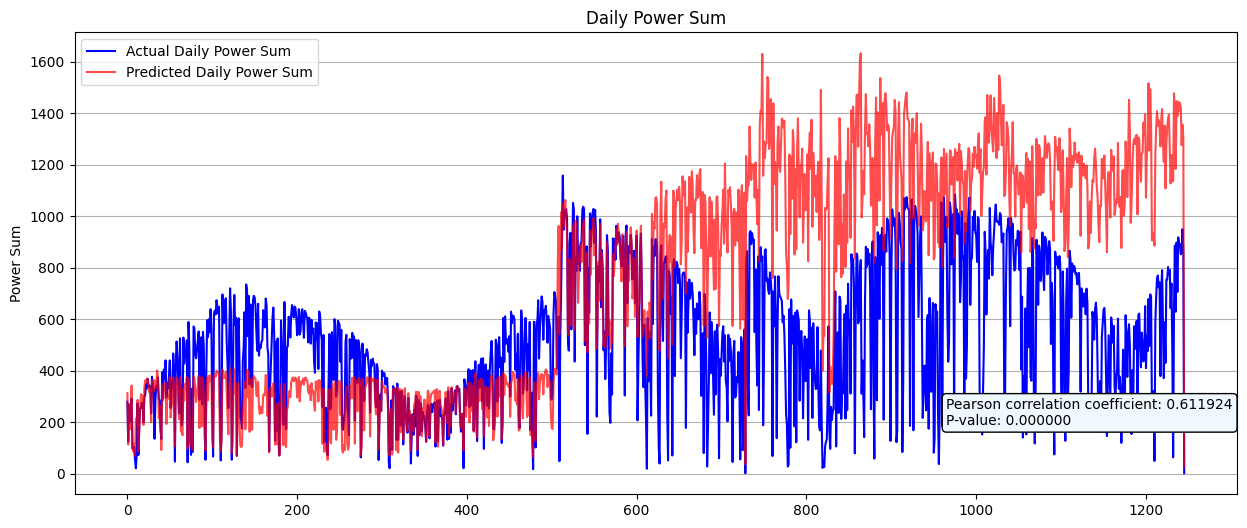
다른지역 뒷부분 갈수록 값이 엄청 튀는데
군산지역 데이터를 보면 최대값이 700정도로 발전량이 엄청 많다.
아마 이 데이터 때문에 그런 것 같아서 군산 지역 데이터를 뺐다.만약 데이터가 나중에 부족하다면 이 데이터 스케일을 조정해서 추가해도 되긴 함.
- 갑자기 생각난 <한 지역에 여러개의 발전소가 있을 수 있다>
그래서 발전소별로 다시 발전량을 살펴봤다.
- 0 영암에프원태양광b 165.0
43698 [서인천]발전부지내 태양광 1단계 112.0
44423 [서인천]발전부지내 태양광 1단계ESS 112.0
45951 [서인천]발전부지내 태양광 2단계 112.0
46543 군산복합2단계태양광 140.0
47277 군산복합2단계태양광ESS 140.0
48806 대전 학하 연료전지 133.0
50222 삼랑진태양광#1 288.0
50847 삼랑진태양광#2 288.0
51493 서인천연료전지 112.0
52909 서인천연료전지2 112.0
54325 세종시수질복원센터태양광연계 ESS 239.0
55858 수질복원센터태양광 239.0
56703 의왕 연료전지 119.0
58119 장흥풍력 260.0
59468 천안청수연료전지 232.0
적합하지 않은 발전소는 다 지웠다.
군산복합2단계태양광을 테스트로 정하고, 나머지 위치 다 지우고 학습
2023-09-20
- 최박사님이 주신 일

8개의 station에 대해서 ML모델로 돌린 MAE를 각각 구하고, 그래프로 나타내기
각 station 별로 MAE :
[0.12377421028387381, 0.11014021305114155, 0.09894573563731025, 0.0978738588458203,
0.11180930292552234, 0.11560595055737166, 0.108832655880442, 0.14337362440044435]
가장 잘 나온게 9.8%정도 오차율이다.

그리고 stn=5에서 그림을 그려봤다.
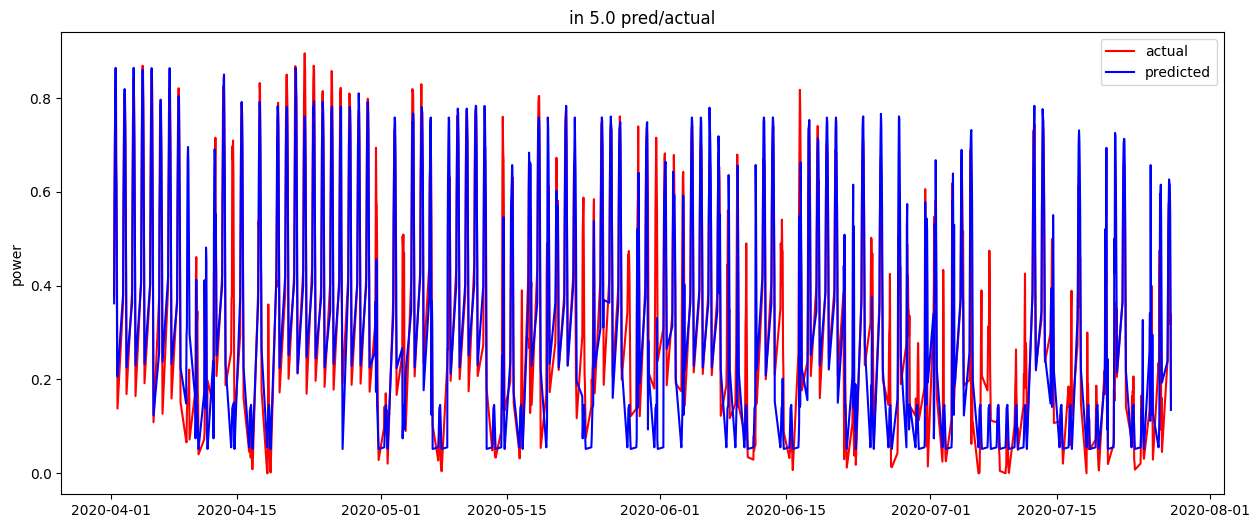
양상이 조금 특이하다.......
뭔가 이상한 것 같아 그림을 그려봤다.
아래가 실제 shortwave값이다.

그리고 아래는 박사님이 test값으로 주신 모델값이다.

shortwave는 음수가 나올 수 없는데 음수값이 존재했다. 이 부분을 말씀드리니 모델자료에 오차가 있어서 관측이랑 평균이 같아지게끔 보정을 했었는데, 이렇게하니 (-)값이 생긴 줄 모르셨다고...
그래서 다시 보정해서 주신다고 하셨다.
데이터가 2020년 4월부터 8월까지 밖에 없어서 특별한 규칙을 띄지 않는 것 같아 보인다...
2023-09-21
뭔가 많이했다.....
- 지역별로 train/test 나누기
영암이 제일 데이터가 규칙적이라 영암으로 실험해봤는데
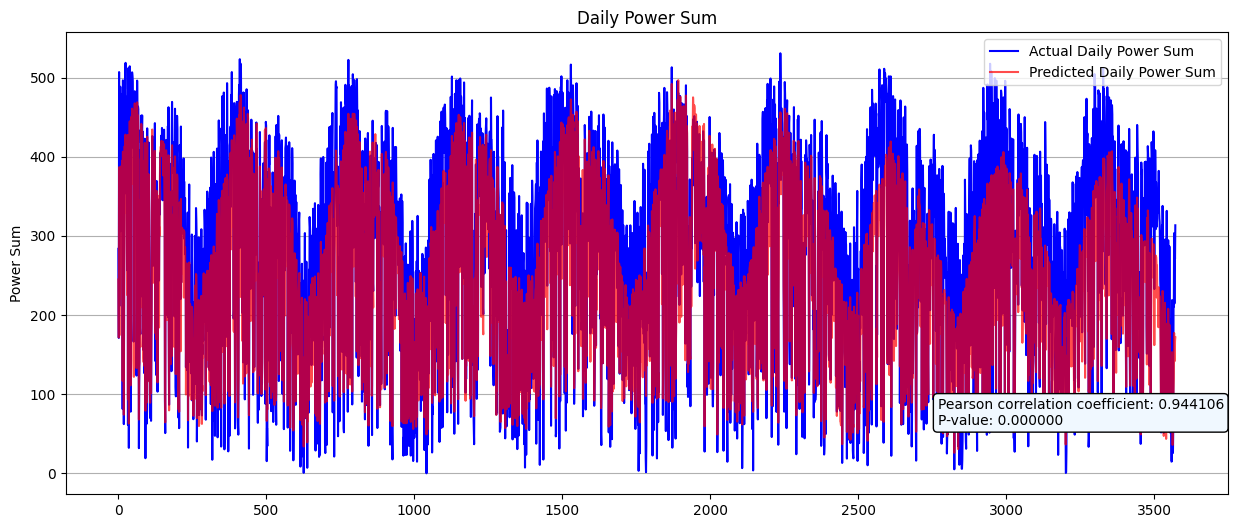
오차율이 12%정도 된다.
근데 생각보다 결과가 안좋아서 이 방법은 패스
- 시간별로 train/test 나누기
- 사용한 모델은 NGBoost

이런식으로 나눴다.
학습시킨 후 각 지역별로 어떻게 예측했는지 살펴보았다.
| 서인천1단계 | 서인천2단계 | 삼람진태양광#1 | 삼람진태양광#2 | 수질복원센터 | 영암F1 |
|---|---|---|---|---|---|
| 23% | 5% | 8% | 8% | 19% | 5% |
가장 안나온 서인천 1단계

가장 잘나온 서인천2단계 & 영암F1


- 일단 돌려볼 수 있는 것 중에서 머신러닝은 NGBoost가 성능이 제일 좋은 것 같은데
위 결과는 아직 파라미터 학습을 시키지 않은 결과임.
아쉬운 부분이 있다면
- 데이터가 더 고르면 좋을텐데...
인데 모든 발전소가 그렇지 않을테니 이런 것들도 고려할 수 있는 모델이 있으면 좋겠다.
NGboost 모델 파라미터까지 학습시켜서 비교해보기
2023-09-22
- 아침 대역2 수업
- 벌써 3주가 지났다. 수업들은 날 열심히 복습하고 틈틈히 수식 정리해서 보는데 수식을 유도하고... 정리하고 어렵지 않지만 수식과 어떤 이론을 연결시키기가 쉽지 않은 듯;;
아무래도 필기는 교수님이 칠판에 적어주시는 걸 적다 보니까 나중에 돌이켰을 때 이 수식이 뭘 의미하는건지 어려워서 2주차부터는 교수님이 하시는 말씀을 좀 꼼꼼히 적으려고 하는중... - 그래도 수업은 재밌다 !!! 새로운 걸 배우는 건 언제나 재밌따..
-
최정박사님 보내드린 피겨가 갑자기 잘못된 것 같아서 다시 그려봤다.
역시 잘못됐던 거였음. 쨌든 데이터를 기다리고 있는 중. -
교수님께서 말씀하셨던 long wave... 어쩌구... 가 장파인 것 같아서 찾아보니 기상청 사이트에는 없었다. 오늘 직접 여쭤보니 장파 맞다고 하심. 없어서 패스.
-
데이터 양이 많아지고 머신러닝 하나로 하기가 힘든 것 같아서 여러 딥러닝 모델들을 돌려도 괜찮을 것 같다고 생각했다. 특히 Tabnet!!!!! 이걸 써보기 위해서 오늘 GRU를 비교를 위해 써봤다.
더 많은 딥러닝 모델들을 시도해볼 예정이이다.
- GRU 결과
| 서인천1단계 | 서인천2단계 | 삼람진태양광#1 | 삼람진태양광#2 | 수질복원센터 | 영암F1 | |
|---|---|---|---|---|---|---|
| NGboost파라미터학습X | 23% | 5% | 8% | 8% | 19% | 5% |
| GRU파라미터학습O | 25% | 3% | 8% | 9% | 21% | 4% |
여기서 중요한 점은 GRU는 파라미터 학습을 했고 NGBoost는 안했음
규칙적인 데이터에 대해서는 GRU가 더 잘 나오는 것 같은데
이상치가 많은 데이터에 대해서는 NGBoost가 더 잘나온다!
NGBoost 파라미터를 학습시키면 아마 더 잘나오지 않을까?
그치만 그 전에 다른 딥러닝 모델들을 먼저 학습시키고 싶으니.....
다음주는 딥러닝 모델들 위주로 학습하고 결과를 살펴보는것으로
Next Week's Agenda
- 월-수만 일할 수 있음
- TabNet, TimesNet, LightCTS 돌려보겠음
- 가장 잘 나온 모델 기준으로 튜닝하고, 모델 디자인하는걸로!
