데이터를 확인하다 보면 아래와 같이 문자로 되어있는 셀을 발견하게 된다.
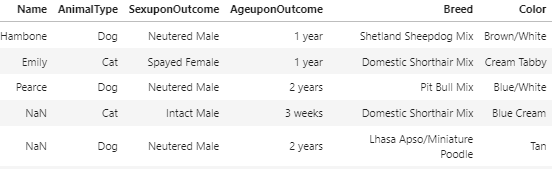
이런 데이터들은 컴퓨터가 인식하지 못하기 때문에, 모조리 숫자로 바꿔줘야 한다.
그 전에 어떤 셀들이 문자로 되어있는지 확인해 보자.
cat_cols = all_data2.columns[all_data2.dtypes == object]
cat_cols어떤 columns의 데이터가 dtypes == object 즉 문자로 되어있는지 확인할 수 있다.
해당 예시에서는
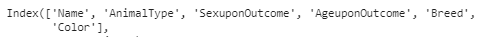
위와 같은 셀들의 데이터가 문자로 되어있다는 것을 확인할 수 있다. 이제 문자를 숫자들로 바꿔보도록 하자.
참고로 여기서 설명하는 문자를 숫자로 바꾼다는 얘기는
Animal Type이 Cat이라면 0, Dog 이라면 1 이런식으로 인코딩해준다는 얘기이다.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
for i in cat_cols:
all_data2[i] = le.fit_transform(list(all_data2[i]))
all_data2모든 문자 셀들에 대해 fit_transform을 해주면 된다.
그 인자로 해당 셀들을 넣어주게 되는데, 여기서 list로 변환해준 이유는 무엇일까?
바로 Null 값을 처리해주기 위함이다.
처리라기 보다, 만약 list로 변환해준다면 Null이라는 문자를 새로 인식해서 모든 null값들은 같은 숫자로 변환되어 처리될 것이다.
만약 데이터에 null값이 없다면 list는 생략해도 상관 없다.

뜬금없지만 세계여행이 꿈입니다.