Kaggle
1.데이터 불러오기

캐글에서 노트북을 켜고 첫번째 셀을 실행하게 되면 어떤 데이터들이 다운받아졌는지 확인할 수 있다. 데이터 파일은 보통 .csv 파일로 존재하게 되는데, 이 파일들을 열고 확인해보자.pd.read_csv로 해당 .csv파일을 열 수 있다.항상 코드 바로 아래에 저장한 내
2.pd.concat 데이터 합치고 분리하기
트레인과 테스트 데이터를 불러와준 후, 두 데이터 세트에 대해 동일한 작업을 해 줘야 하는데, 이 때 pd.concat을 사용할 수 있다.아래와 같이 사용한다.이렇게 되면 all_data로 두개의 데이터가 합쳐지게 된다. 합쳐지는 방식은 train데이터 뒤에 test데
3.dt. 날짜, 시간 데이터 처리하기

데이터 세트 중에 날짜와 시간 데이터를 포함하는 셀이 종종 존재한다.이런 데이터들은 해당 셀 안에서 처리할 수 없어, 각각 셀을 생성해서 값을 넣어줘야 한다.년, 월, 일, 시, 분, 초 각각에 셀을 만들어준 후, 해당 값을 넣어주면 된다.위 데이터에서는 셀 이름이 D
4..drop 데이터 셀 없애기
전처리 과정 중에 필요없는 셀들이 존재한다.얘네들을 살려두게 되면 나중에 모델링 하는데 방해가 되므로 미리 삭제하거나, 문자로 되어있어 따로 셀을 만들어 처리해서 기존 셀이 필요없어지는 경우가 있다.바로 이전 글에서 설명한 날짜 데이터에서도 다른 셀로 정보들을 옮겨버리
5.LabelEncoder 문자 데이터를 숫자로 변환
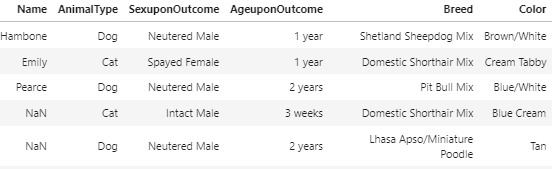
데이터를 확인하다 보면 아래와 같이 문자로 되어있는 셀을 발견하게 된다.이런 데이터들은 컴퓨터가 인식하지 못하기 때문에, 모조리 숫자로 바꿔줘야 한다.그 전에 어떤 셀들이 문자로 되어있는지 확인해 보자.어떤 columns의 데이터가 dtypes == object 즉 문
6.RandomForest 모델링
테스트 셋과 트레이닝 셋을 가지고 학습을 할 수 있다.맨 처음 모델로 랜포 모델을 소개한다.RandomForestRegressor의 인자로 사용되는 n_jobs는 cpu라고 생각하면 된다. 4혹은 -1로 작성하면 훨씬 더 빠르게 모델을 돌릴 수 있다. random_st
7.특정 셀에 데이터 삽입
예측 후 정답 칼럼이 생성되었으면, 정답을 제출할 파일(submission파일)에 해당 정답 데이터를 삽입해줘야 한다.sub데이터의 count칼럼에 result_cas데이터를 집어넣는 코드이다.이 코드를 작성하기 전에 당연히 submission 파일을 먼저 불러와준 후
8.submission파일 제출하기
sub에 정답 데이터를 삽입했으면, 제출하면 된다.정답 데이터 + .to_csv를 하면 데이터를 csv파일로 바꿔서 제출 할 수 있는 형태가 된다.인덱스는 포함하지 않을 것이므로 index = False로 설정해준다.만약 지금 진행중인 컴페티션에서 제출하는 경우, 파일
9.CatBoostClassifier 모델링
이전 글 랜포 모델링에 이어서 캣부스트로 모델링하는 방법을 소개한다.가장 간단한 CatBoostClassifier로 모델링을 할 수 있다. 코드 형식은 랜포와 똑같다!아래는 캣부스터 모델의 특징이다. 이런 트리 모델은 정형데이터에서 점수가 잘 나온다.트리=모델이라고 생
10..predict_proba 예측 형식

이전에 랜포를 소개하는 글에서 모델 학습 방법을 소개하면서 예측하는 방법도 같이 언급했었다.여기서는 조금 다른 예측 방법을 소개한다.캣부스트로 학습을 시켜준 코드를 먼저 확인해보자.여기서는 OutcomeType 셀에 대해서 학습을 시켜준 것 같다.이 셀의 내용을 확인해
11.sns.boxplot 그래프로 선형 관계 확인하기
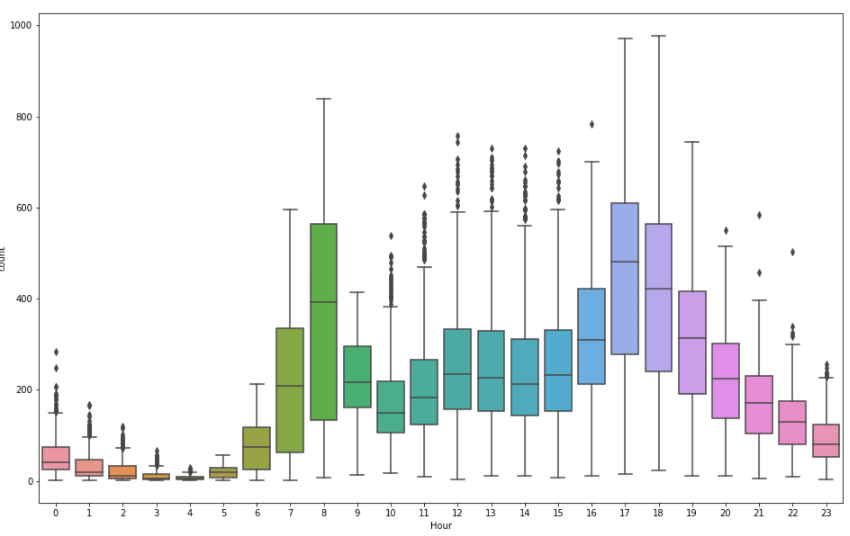
all_data\['Hour']는 x축all_data\['count']는 y축 bike sharing demand 대회의 예를 들자면 이런 그래프가 나오게 된다. 시간에 따른 자전거 대여 수이다. 해당 데이터에서는 튀는 값이 많아서 이후에 평일 데이터와 주말 데이
12.np.log np.exp 로 점수 올리기
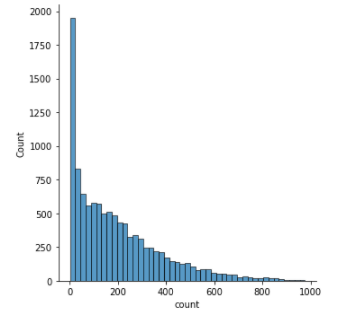
로그를 사용하기 전에 꼭 확인해 볼 한가지가 있다.이 그래프를 그려서 한쪽으로 쏠려있으면 로그를 사용할 것!이 그래프에 로그를 씌운 결과는 아래와 같이 확인할 수 있다.만약에 이렇게 로그를 사용할 수 있는 상황이라면위처럼 모델을 학습할때 집어넣으면 된다.np.log(t
13.특정 칼럼의 값을 바꾸기
만약 어떤 특정 칼럼에서 0이라는 모든 값을 1로 바꾸고 싶다면 아래 코드를 사용하면 된다.
14..corr() 특정 x값이 y값에 어떻게 영향을 주는지 확인하기
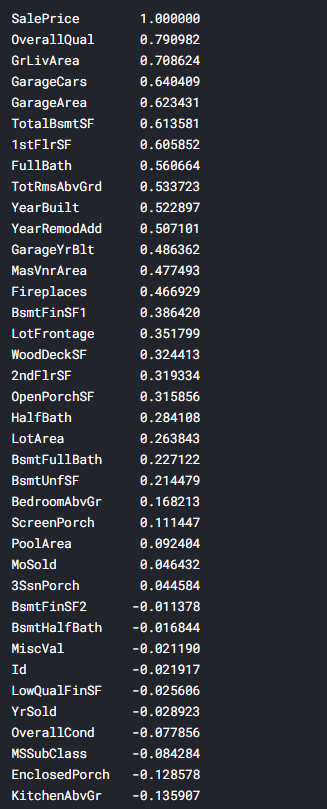
ascending = False를 인자로 넣어주게 되면 큰 순서로 정렬된다.이런 출력값을 확인할 수 있다.여기서는 물론 선형 데이터들만 확인할 수 있고, 음수로 표현된 부분은 반대방향으로 선형 관계가 있다는 것이다. 즉, 절대값이 중요하다.위 데이터의 설명을 조금 덧붙
15.feature_importances_ 칼럼의 중요도 확인하기
숫자형 + 문자형 칼럼의 중요도를 확인하기 위해서는 feature_importances\_를 사용할 수 있다.이렇게 넣어주면 각 칼럼의 중요도를 순서대로 확인할 수 있다.중요도가 0인 칼럼을 위에서 빼줘도, 해석을 위한 것이기 때문에 모델 점수 개선에 직접적으로 영향을
16.pd.get_dummies 원-핫 인코딩
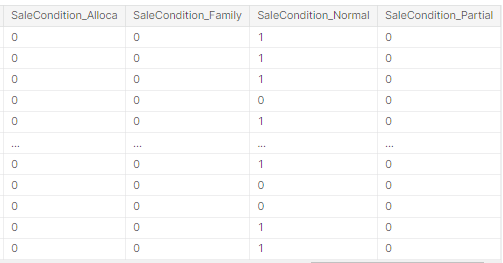
선형모델을 사용하는 경우 레이블 인코딩을 사용하게 되면 선형 모델이 각 클래스를 선형 관계로 이해해버리는 문제가 발생하게 된다.따라서 원-핫 인코딩을 해줘야 한다.예전 글에서도 한번 설명한 적이 있다.모든 클래스에 대해 칼럼을 생성하여 해당하는 칼럼에 1을 넣어주는 형
17..fillna() 빈 값 채우기
결측치를 채우는 방법에는 여러가지가 존재한다. 특정 대회의 결측치는 "데이터가 없어서" 결측치로 남겨놓는 것도 있다. 그래서 이런 데이터들은 "없다" 라는 느낌으로 채워줘야 하기 때문에 0으로 채우게 되면 모델이 오해할 소지가 생긴다.(기존 0과 겹칠 수도 있음)따라서
18.StandardScaler() 각 칼럼의 범위 차이가 큰 경우
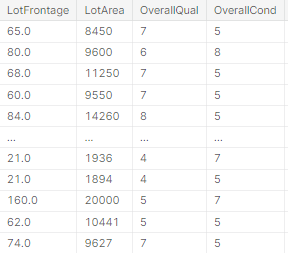
위 데이터처럼 각 칼럼의 최대-최소 범위 차이가 많이 난다면 StandardScaer함수를 사용해볼 수 있다.이것도 범위를 맞추는 여러 방법이 존재한다.여기서는 한가지 방법만 소개한다.
19.Ridge 선형 모델
많은 데이터가 선형일 때 이 모델을 고려해볼 수 있다.예를 들어, 이런 데이터인 경우.유의할 부분은 규제 부분이다. 하이퍼 파라미터를 잘 설정해줘야 한다.자동으로 설정하는 방법이 있다는데, 아직 배우지 않았다!일단 수동으로 수정했었는데, 알파값이 클 수록 결과가 좋았다
20.Image.open() 이미지 열어보기
해당 라이브러리를 임포트 하고 이미지 주소를 넣으면 이미지를 가져올 수 있다.
21.cv2.resize() 이미지 사이즈 조절하기
사진을 열어봤는데 이미지 크기가 너무 큰 경우 cv2.resize()를 이용하여 원하는 크기로 줄일 수 있다.맨 아래 코드로 줄인 이미지를 저장한다.그럼 출력파일에 저장되기 때문에 후에로 쉽게 접근할 수 있다.위 코드를 응용하여 전체 파일에 대해 사이즈를 조절해보자.
22.!unzip -q -o zip파일 열기
캐글에서 데이터셋을 옮겨올 때 zip파일 형식으로 된 데이터들을 사용하는 방법이다. n_train = len(os.listdir('./train'))n_test = len(os.listdir('./test'))print(f'Train images: {n_train}')
23.['Path']경로 셀 만들기

이미지 처리를 할 때면 파일의 경로를 만들어 줘야 하는 경우가 생긴다. 여기서는 Tensorflow-Help Protect the Great Barrier Reef대회로 예시를 들어보겠다.이런 경로 주소를 위 train.csv파일의 맨 오른쪽에 새로운 셀로 추가해보자.
24.'[]'결측치 제거하기
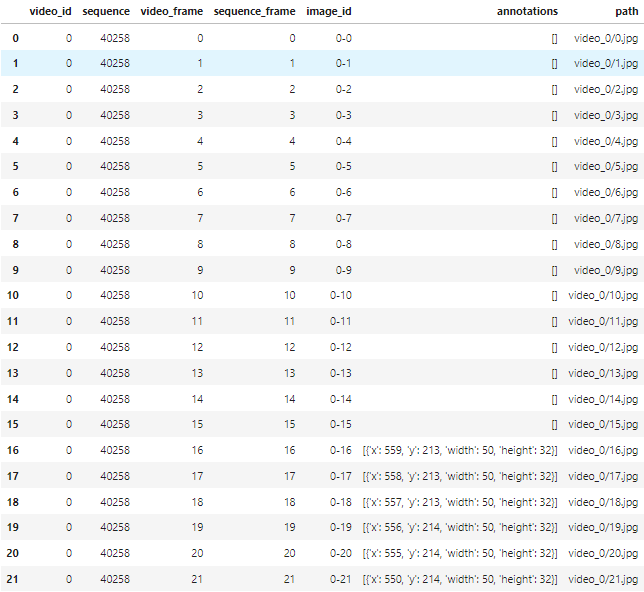
TensorFlow - Help Protect the Great Barrier Reef대회 문제를 풀다가 train을 찍어보니 아래처럼 0번부터 15번까지는 결측치가 있다는 걸 확인했다. 이를 지워주고자 한다.위 코드를 확인해보자. 우선 train안에서 string의
25.torch.ones()로 1값을 갖는 tensor생성하기
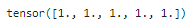
를 하게되면이런 결과가 출력된다.torch에 대한 함수는 여기서 자세히 확인하자.
26.to_csv중첩되어있는 json파일을 csv로 변환하기
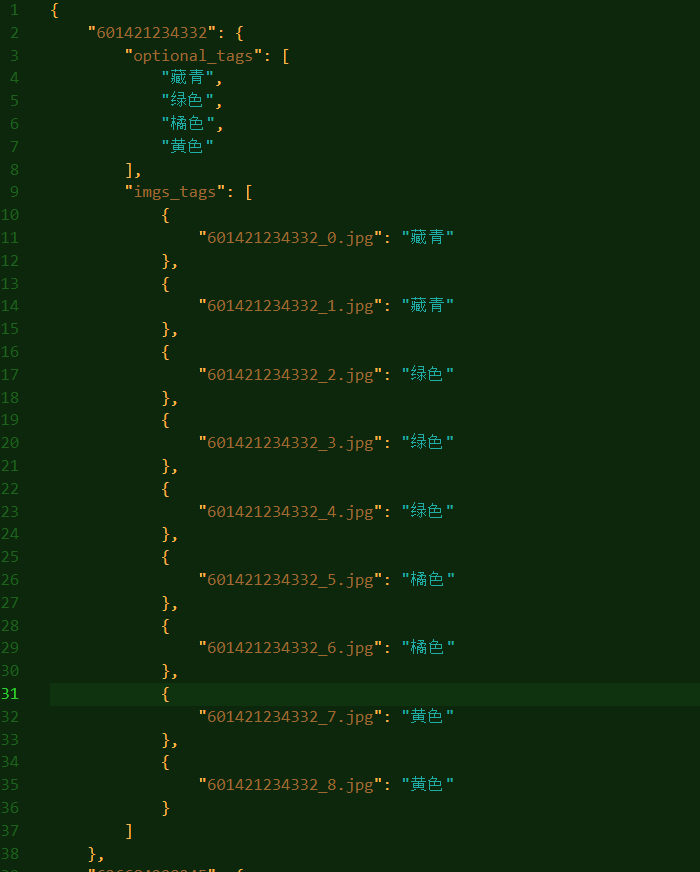
json파일 상태다.구글에 치면 json to csv변환기가 많은데 내 파일은 중첩이 되어있어 그런지 변환이 안됐다... 유감...그래서 이것저것 만져보긴 했는데 가장 쉬운 방법은 .to_csv 이용하기별...거... 아니었음그치만 하나의 optional_tags에 여
27.한 행 안의 여러개의 내용을 여러 행으로 분리하기

지난 글에 이어 한 행 안의 여러개의 내용을 여러 행으로 분리하는 방법을 알아보자.위 사진의 imgs_tags열에는 여러개의 중괄호로 정보가 담겨있고, ,를 기준으로 나뉘어있다.여기서 split함수를 사용하여 각각을 분리한 후, 하나로 합치기 위해 Series로 바꿔준
28..split()완전정복
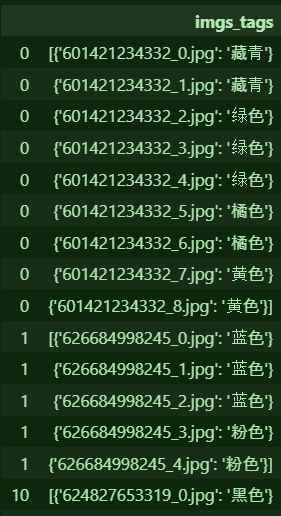
지난 글에 이어서 imgs_tags의 내용을 두 개의 셀로 분리해보자.위 imgs_tags안에는 이미지 이름과 색깔의 정보가 각각 저장되어 있는데, 두 개의 셀로 분리하고 싶다.각각 path와 color의 열을 만들어 분리해낸다.여기서 기준점이 되는것은 :이므로 :을
29..replace로 원하는 특수문자와 괄호 안의 내용 지우기
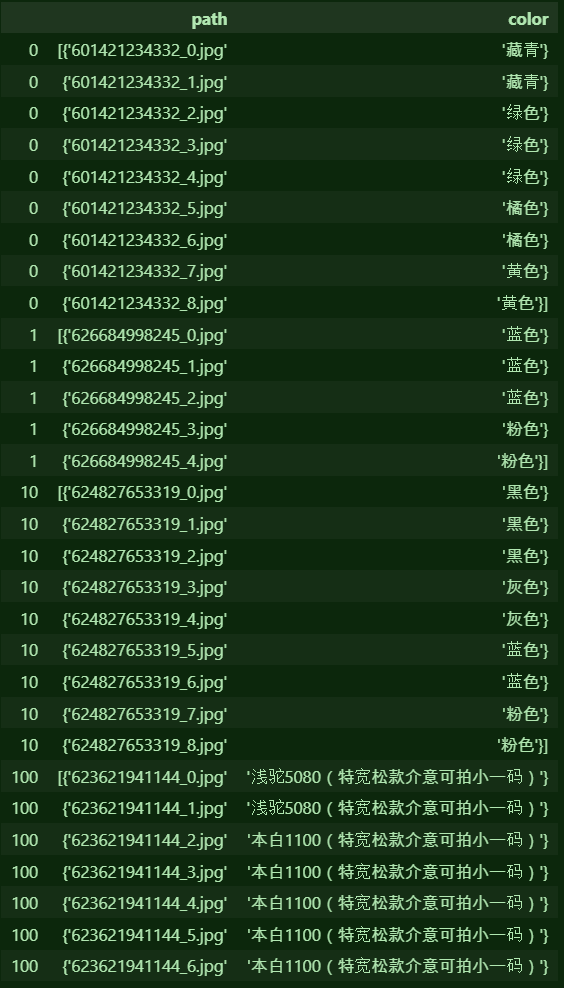
역시나 지난 글에서 사용했던 데이터를 사용한다.데이터 내용을 확인해보니 불필요한 특수문자와 특수문자 안의 내용을 지우고 싶은 생각이 들었다..replace를 사용하여 지워보자.평범한 기호들은 위 코드로 거의 다 지울 수 있다.pat = r'\[' 여기서 \[대신에 다른