이미지 처리를 할 때면 파일의 경로를 만들어 줘야 하는 경우가 생긴다.
여기서는 Tensorflow-Help Protect the Great Barrier Reef대회로 예시를 들어보겠다.

이런 경로 주소를
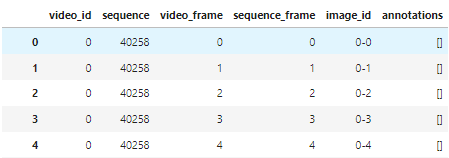
위 train.csv파일의 맨 오른쪽에 새로운 셀로 추가해보자.
train['path'] = 'video_' + train['video_id'].astype(str) + '/' + train['video_frame'].astype(str) + '.jpg'경로중에서 /kaggle/input/tensorflow-great-barrier-reef/train_images/여기까지는 똑같으니까 생략해준다.
그 이후에 각각의 비디오에 대해 라벨링이 되어 있는데, 이건 train에서 video_id를 따른다.
따라서 video_뒤에 train['video_id']를 넣어주고, 숫자로 인식하는 걸 피하기 위해 str로 형식을 바꿔준다.
이어지는 숫자또한 video_frame칼럼을 따르므로 같은 방법으로 뒤에 추가해주면 된다.
마지막으로 확장자명을 붙여주면 새로운 train이 수정됐다.
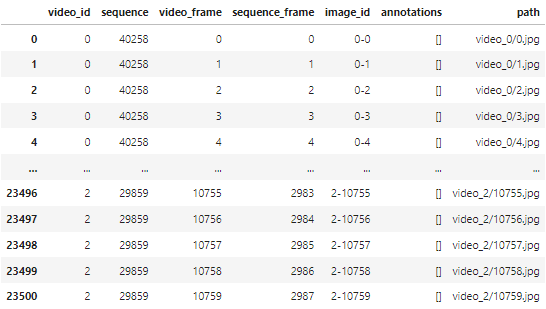
이처럼 사진들의 원래 주소를 확인하고 어디서 정보를 가져올 지 확인하면 새롭게 train set을 갱신할 수 있다.

뜬금없지만 세계여행이 꿈입니다.