[2023 ICLR] SeaFormer: Squeeze-Enhanced Axial Transformer for Mobile Semantic Segmentation
Paper Review
Tancent PCG, Fudan University에서 ICLR 2023에 발표할 예정인 mobile device target의 semantic segmentation architecture, SeaFormer를 알아보자
1. Introduction
ViT의 등장, Swin이 Transformer의 CV generic backbone으로써 우수함 (global context modeling의 capability)을 입증했음. 허나, computational cost, memory 차지 등의 문제가 남아있어 mobile device에 부적합하다. 특히, 고해상도 이미지 입력에 대해서 부적합하다.
그리하여, local/window-based attention, Axial attention, dynamic graph message passing, 여러 lightweight attention mechanism들이 소개되었었음
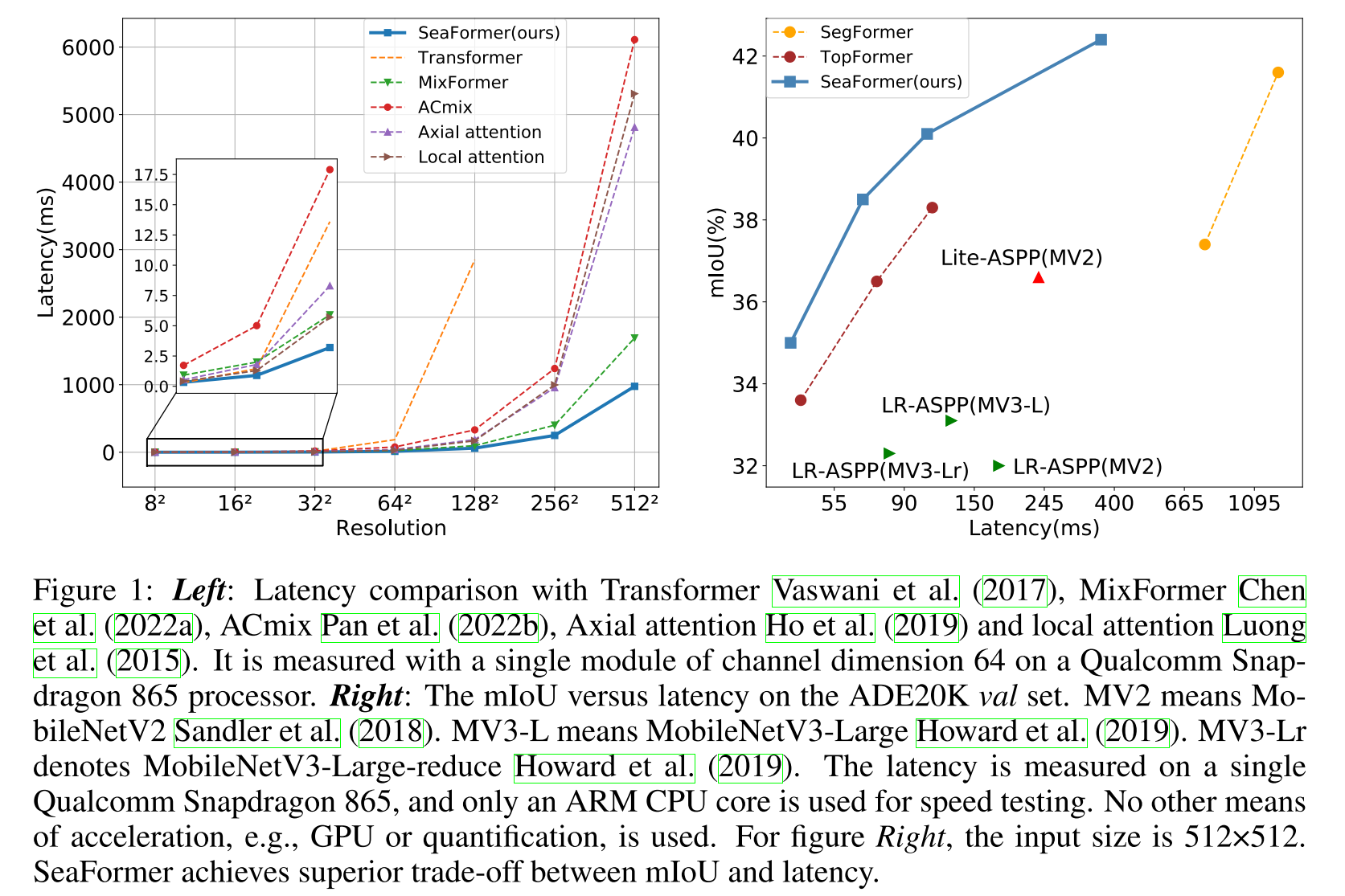
그러나 여전히 고해상도에서 high latency로 인해 mobile deivce에서 설계 요구 사항을 만족시키기엔 불충분하다. 고해상도에서 computational cost를 줄이기 위해 TopFormer (CVPR 2022)는 원래 입력의 1/64 scale에서 global attention을 적용했는데, 이는 분명히 segmentation performance를 저하시킨다.
그런 문제를 해결하기 위해 우리는 squeeze-enhanced Axial Transformer (SeaFormer)를 소개하려고 하는데, 이는 O((H+W)HW)를 O(HW)로 줄이면서 accuracy-efficiency trade-off를 향상시키며 mobile 친화적인 Transformer의 빈자리를 채운다.
core building block인 squeeze-enhanced Axial attention (SEA attention)는 input feature map을 compact한 column/row로 horizontal/vertical 축에 따라 squeeze해서 self-attention을 수행하고 squeeze하는 동안 희생된 detail information을 보상하기 위해 query, keys, values를 concat하고 local detail을 강화하기 위해 depth-wise convolution layer에 이를 feed한다.
Figure 2에서 보이는 light segmentation head와 coupled되어 small-scale feature에서 제안하는 SeaFormer의 설계는 high resolution에서 low latency로 semantic segmentation할 수 있도록 해준다. Figure 1에서 보는 것처럼, SeaFormer는 여러 efficient neural network를 앞섰는데, 특히, SeaFormer-Base는 lightweight CNN인 MobileNetV3를 크게 앞서면서도 ARM-based mobile device에서 낮은 latency를 보여주었다.
2. Related Work
Combination of Transformers and convolution
convolution은 efficient하나 long-range dependencies를 capture하는데에 부적합하고 ViT는 global recpetive field를 통해 강력한 capability를 가지나 self-attention의 computation 때문에 efficiency가 부족하다. 두 가지의 장점들을 모두 사용하기 위해 Mobile ViT, TopFormer, LVT, Mobile-Former, EdgeViTs, MobileViTv2, EdgeFormer, EfficientFormer 등 (all 2022) Transformer에 convolution을 결합하여 efficient ViTs를 만들었다.
MobileViT, Mobile-Former, TopFormer, EfficientFormer는 Transformer block에 제한을 두어 efficiency-performance trade off를 가지고 있고, LVT, MobileViTv2, EdgeViTs는 high latency를 의미하는 상대적으로 높은 computation에서 model size를 작게 가져갔다
Axial attention and variants
Axial attention (2019~2020)은 original global self-attention의 computational complexity를 줄이기 위해 설계되었는데, 한 번에 한 축을 self-attention하고 global receptive field를 얻기 위해 horizontal/vertical attention module을 stack한다.
Strip pooling (2020), Coordinate attention (2021)는 band 모양의 pooling window를 사용해 horizontal 혹은 vertical 차원에 따라 pool하여 long-rage context를 모으는 방식이고 Kronecker Attention Networks (2020)은 horizontal과 lateral의 평균 matrix들의 juxtaposition을 사용해 input matrix들을 average하고 attention operation을 수행한다. 이런 비슷한 방법들은 Axial attention과 비교하여 low computational cost로 performance gain을 가져온다. 허나, 이러한 방법들은 pooling/average operation을 통해 local detail이 부족해진다는 걸 무시한다.
Mobile semantic segmentation
efficient segmentation method의 mainstrea은 lightweight CNN에 기반한다.
DFANet (2019)는 computation cost를 줄이기 위해 lightweight backbone을 사용하고 high-level and low-level feature를 refine하는 feature aggregation module을 더해줬다. ICNet (2018)은 image cascade network를 설계해 알고리즘을 빠르게 하는 반면에 BiSeNet (2018; 2021)은 low-level detail과 high-level context information에 대해 각각 볼 수 있도록 two-stream paths를 제안했다. Fast-SCNN (2019)는 run-time이 빠른 segmentation CNN을 달성하기 위해 multi-branch network의 computational cost를 share한다.
TopFormer (2022)는 CNN과 ViT의 결합한 새로운 architecture를 선보였는데, mobile semantic segmentation에서 accuracy-computational cost 사에 좋은 trade-off를 달성하였다. 하지만, 여전히 global self-attention의 무거운 computation load에 제한을 받는다.
3. Method
3.1. Overall Architecture
저자들은 two-branch architecture들에 영감을 받아 squeeze-enhanced Axial Transformer (SeaFormer) framework를 설계했다.
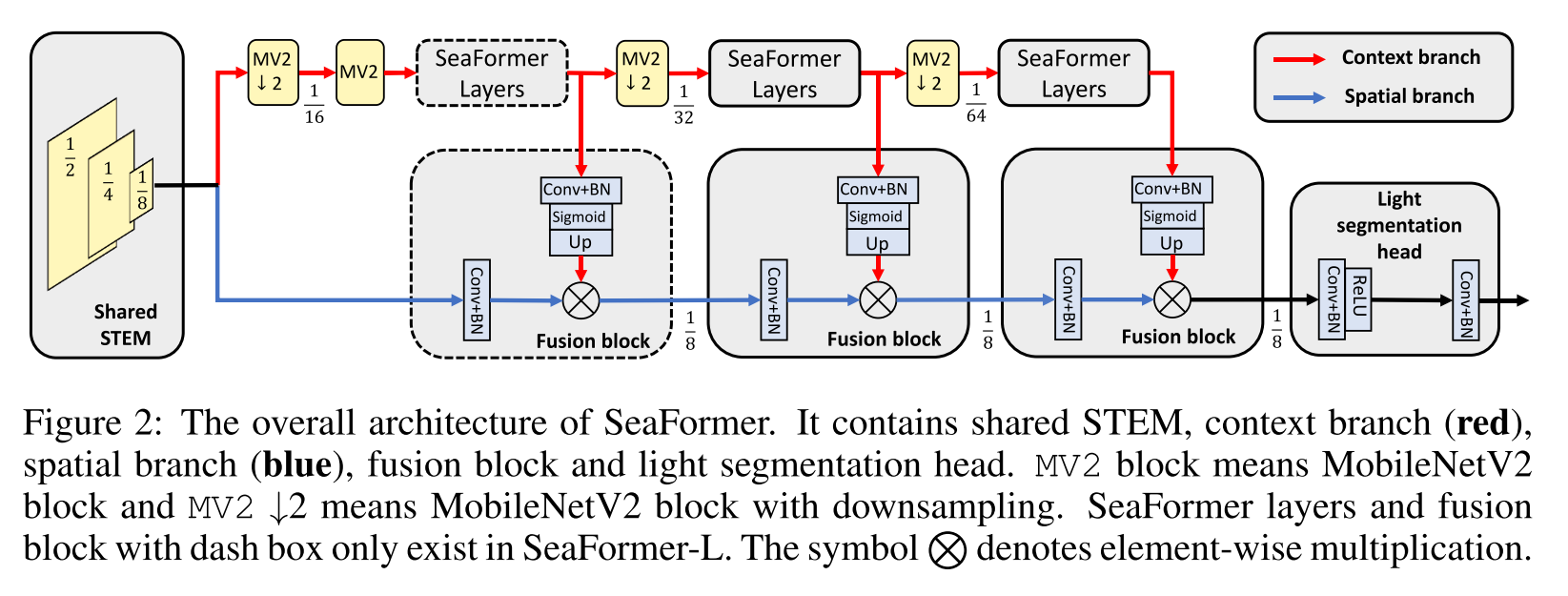
SeaFormer는 다음과 같은 part들로 구성됨
- shared STEM
- context branch
- spatial branch
- fusion block
- light segmentation head
공평한 비교를 위해 TopFormer를 따라 STEM을 design하는데, stride 2의 conv layer에 첫 번째와 세번째의 stride가 2인 4개의 MobileNet Block으로 구성된다.
context branch와 spatial branch는 만들어진 feature map을 공유하며 빠른 semantic segmentation model을 build할 수 있도록 한다.
Context branch
Figure 2에서 context-rich information을 capture하는 빨간 색 방향의 branch를 context branch라고 하며 MV2 (MobileNetV2) block -> SeaFormer Layers를 stage로 반복함. SeaFormer-Large 빼고는 마지막 2 stage에 대해서만 SeaFormer layer가 적용됨.. 점선 block은 SeaFormer-Large에만 있음
Spatial branch
high resolution의 spatial information을 얻기 위해 설계된 spatial branch. 그러나 high-level semantic information이 부족하기 때문에 context branch의 feature들과 결합하는 fusion block이 설계됨
Fusion block
high resolution feature은 spatial branch로부터 1x1 conv와 BN layer를 거치고 context branch로부터 온 context feature은 1x1 conv, BN layer, Sigmoid, upsampling (bilinear interpolation) 을 통해 high resolution feature에 semantic weights을 제공한다. 둘은 element-wisely multiplication한다.
Fusion block은 low-level spatial feature가 high-level semantic information을 얻을 수 있게 한다.
Light segmentation head
마지막 fusion block이후엔는 제안하는 light segmentation head에 직접 feature를 feed함. 빠른 inference 목적으로, segmentation head는 conv + bn을 두 번으로 구성되는데, 첫 번째 conv + bn 이후엔 activation layer를 거침.
3.2. Squeeze-enhanced Axial attention
global attention은 다음과 같고 q, k ,v는 x의 linear projection으로 각각 W를 가지는 식이고 time complexity는 가 된다. resolution에 quadratic complexity를 가지게 됨
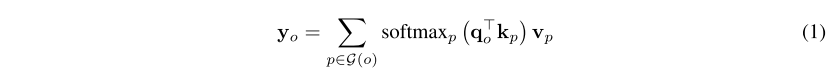
식 (2)는 local attention으로 time complexity를 = 로 줄였는데, global receptiveness를 줄였다. 식 (3)은 Axial attention으로 = 로 줄였다.
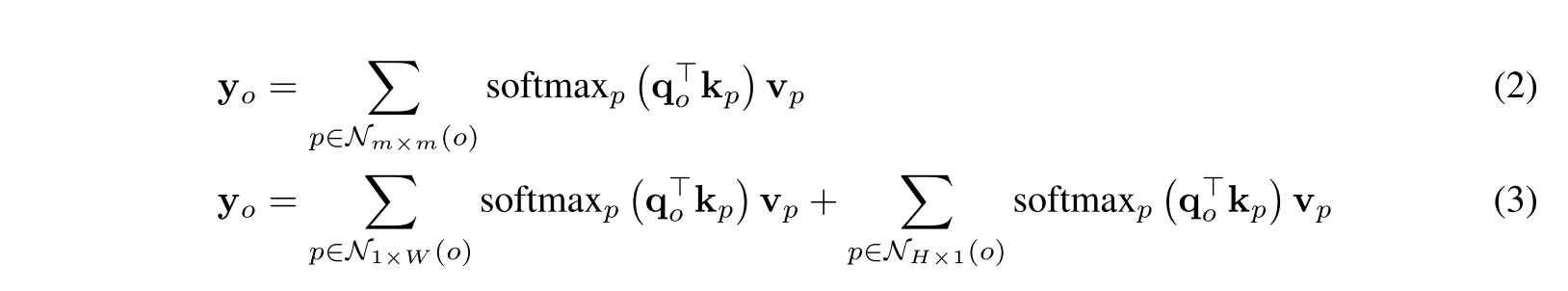
Squeeze Axial attention
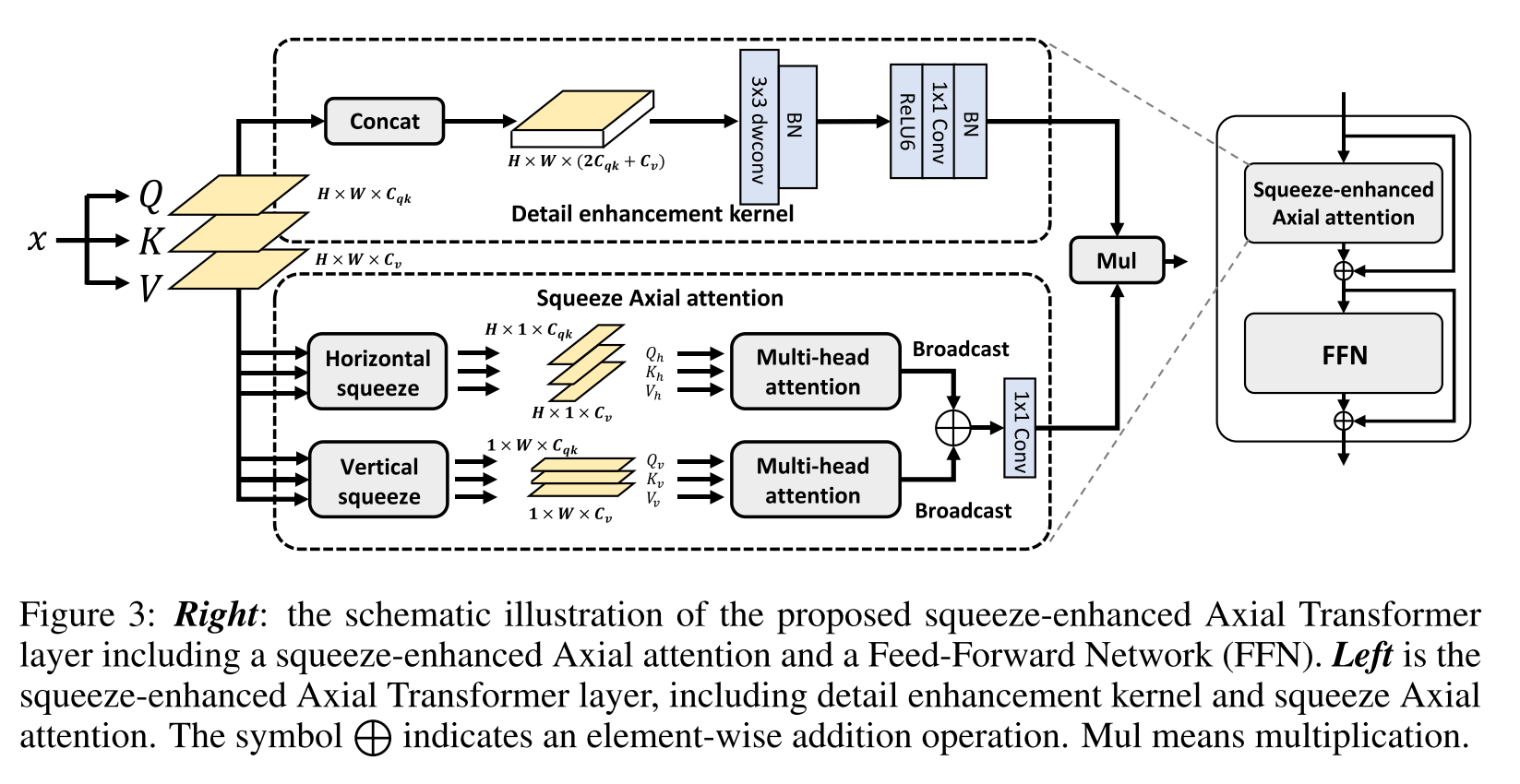
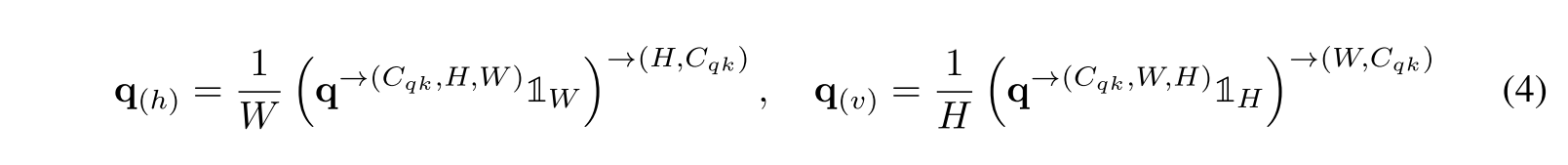
식 (4)는 원래 q를 horizontal/vertical 축에 따라 average하여 얻어지는 각 축에 대한 query를 표현한 것, -> 표시는 dimension을 그 순서대로 permutation한다는 뜻 Figure 3에서 horizontal squeeze, vertical squeeze를 의미한다고 보면 됨. 이는 q, k, v에 반복되고
horizontal 방향으로 squeeze한 q, k, v는 의 dimension을 따르고 vertical 방향으로 squeeze한 q, k, v는 의 dimension을 따름. 각 squeeze operation은 single axis에 대한 global information을 가져오고 식 (5)에서 보여주듯 global semantic extraction을 크게 완화한다.
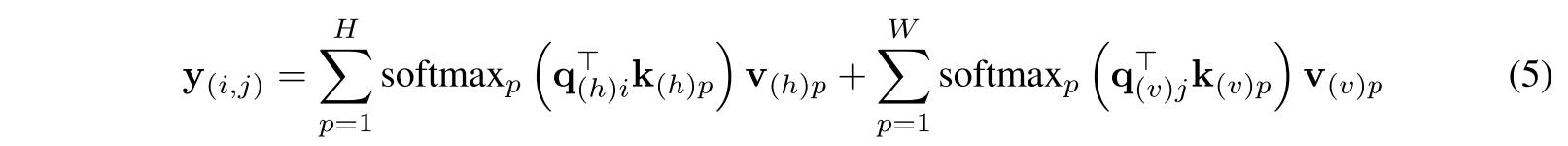
q, k, v를 각 축으로 squeeze한 다음에 self-attention하는 것이 key.. Axial attention은 squeeze하지 않고 HxW가 유지된 상태에서 계산하면서 summation만 각 축에 대해서 해준 모양
sqeeuzing에 대한 time complexity는 이고 attention operation은 이므로 squeeze Axial attention은 time complexity를 로 성공적으로 줄였다.
Squeeze Axial position embedding
식 (4)에서 feature map의 positional information이 포함되지 않았다. Squeeze Axial position embedding을 소개함.
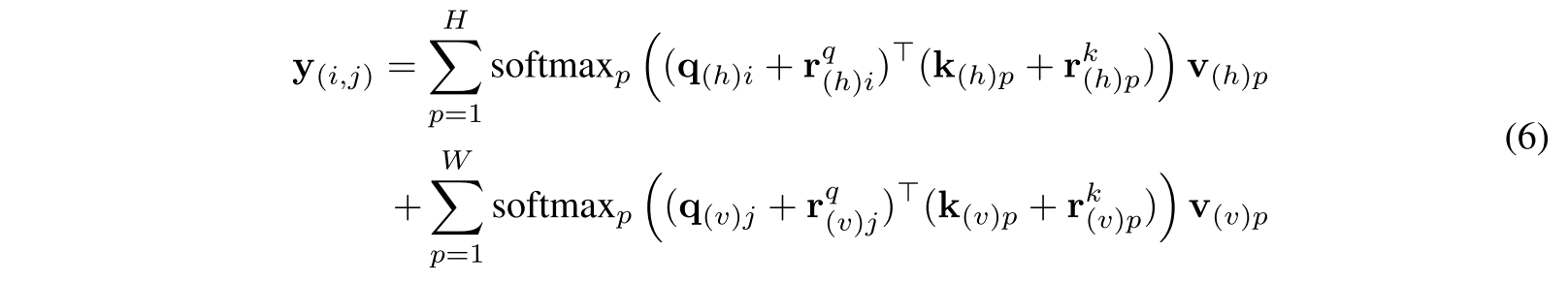
Detail enhancement kernel
squeeze operation은 global semantic information을 efficient하게 추출하는 대신 local detail을 희생한다. 그리하여 spatial detail을 강화하기 위해 auxiliary convolution-based kernel을 적용함. q, k, v를 channel 방향으로 concat하고 3x3 depth-wise conv 하고 batch norm을 통과시키는데, 3x3 conv를 통해 q, k, v로부터 local detail이 결합되어질 수 있음. 그 다음 ReLU6 - 1x1 conv - BN으로 to 로 linear projection을 하며 detail enhancement weight을 만들어냄.
3x3 depth-wise conv엔 , 1x1 conv엔 이 들었음
4. Experiments
ImageNet-1K pretrained network를 backbone으로 썼고 standard BN을 synchronized BN으로 대체했음
Training
mmsegmentation에 구현되었고 공평한 비교를 위해 TopFormer의 batch size, training iteration scheduler, data aug 전략을 따랐고, learning rate 0.0005, weight decay 0.01, "poly" learning rate scheduled with factor 1.0,
4.2. Comparison with State of the Art
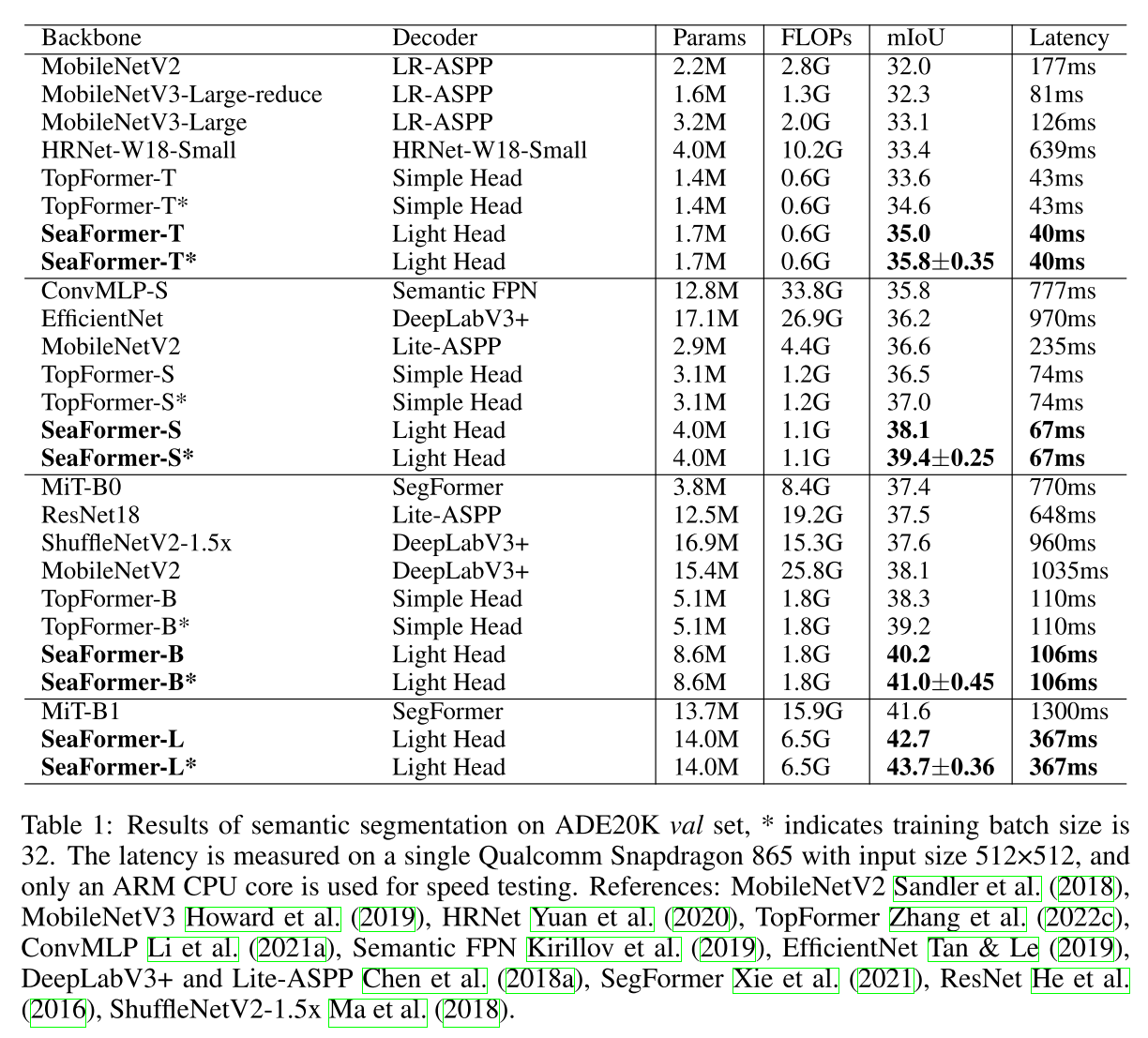
ADE20K val set
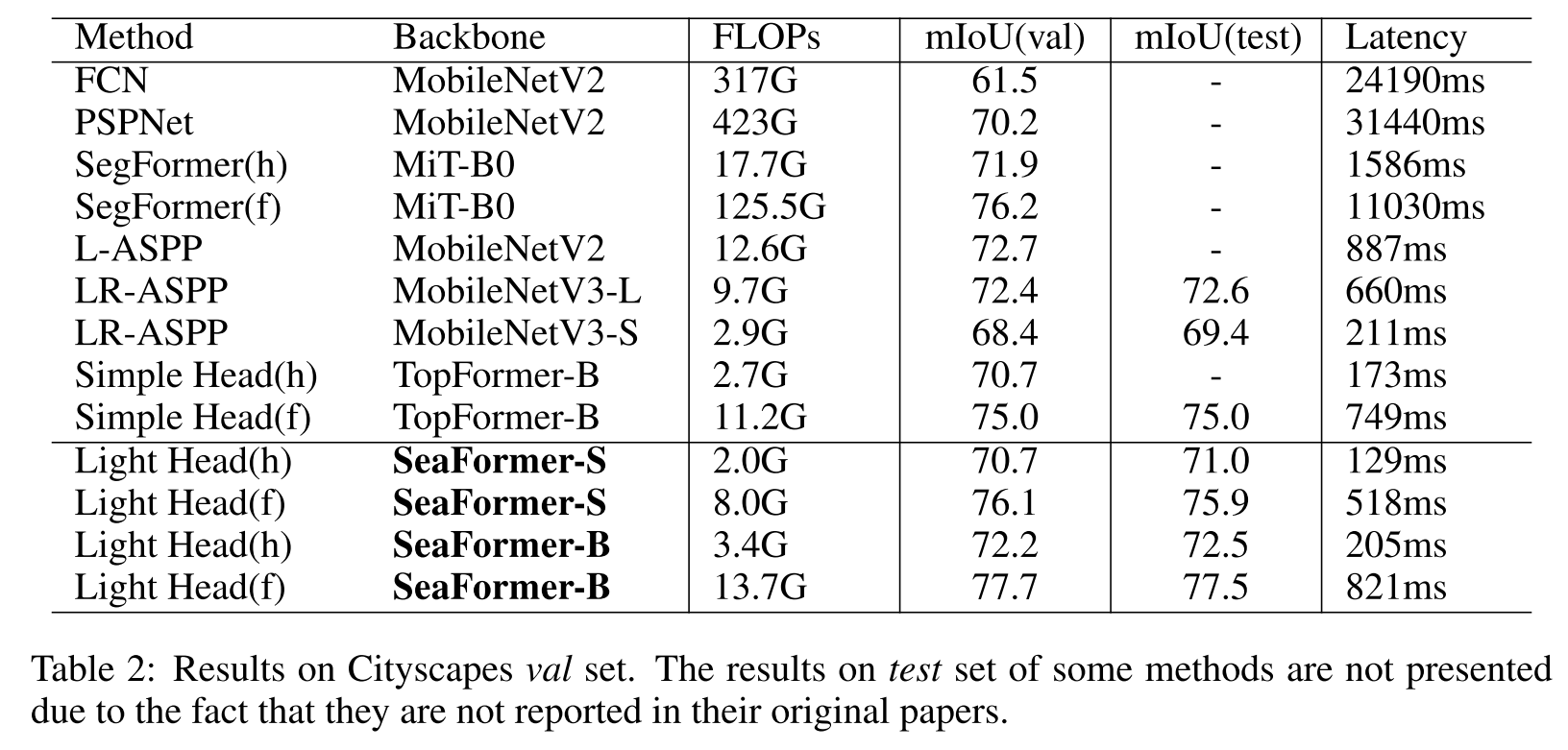
Cityscapes val set
4.3. Ablation Study
The influence of components in SEA attention
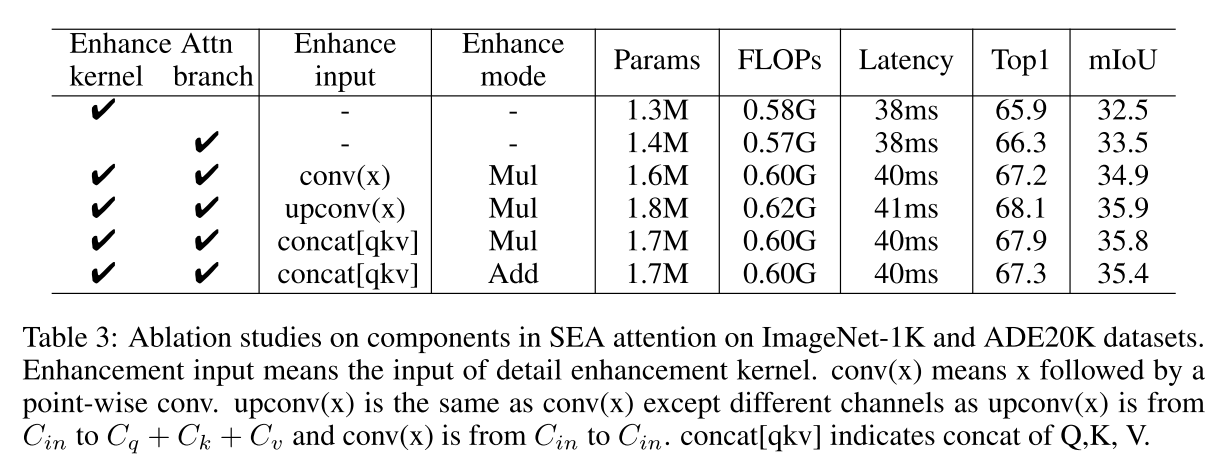
conv(x)와 upconv(x)는 point-wise conv인데, x의 channel을 그대로 가져가느냐 아니면 더 키우느냐인데 channel수를 키우는 것이 performance를 키우는 것에 도움이 된다는 게 확인이 된 것이고, concat[qkv]와 upconv(x)의 비교는 detail enhancement kernel과 squeeze Axial attention 사의 weight sharing을 유무 차이로 성능 loss가 거의 없는 상태로 weight sharing이 efficiency를 높여줌을 입증하여 concat[qkv]로 선택하고 Params/FLOPs 차이 없이 Mul이 Add보다 성능 개선이 커서 이로 결정하게 됨.
Comparison with different self-attention modules
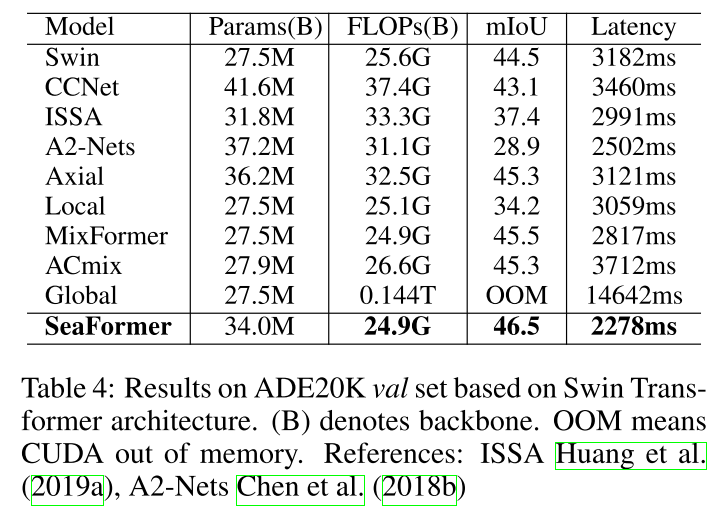
Swin Transformer architecture에서 attention block을 바꿔가면서 실험을 수행하였음. 공평한 비교를 위해 Swin에서 설정한 훈련 protocol을 따랐음
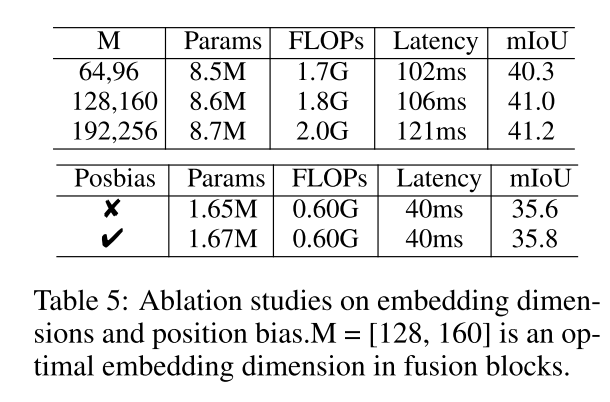
The influence of the width in fusion block
4.4. Image Classification
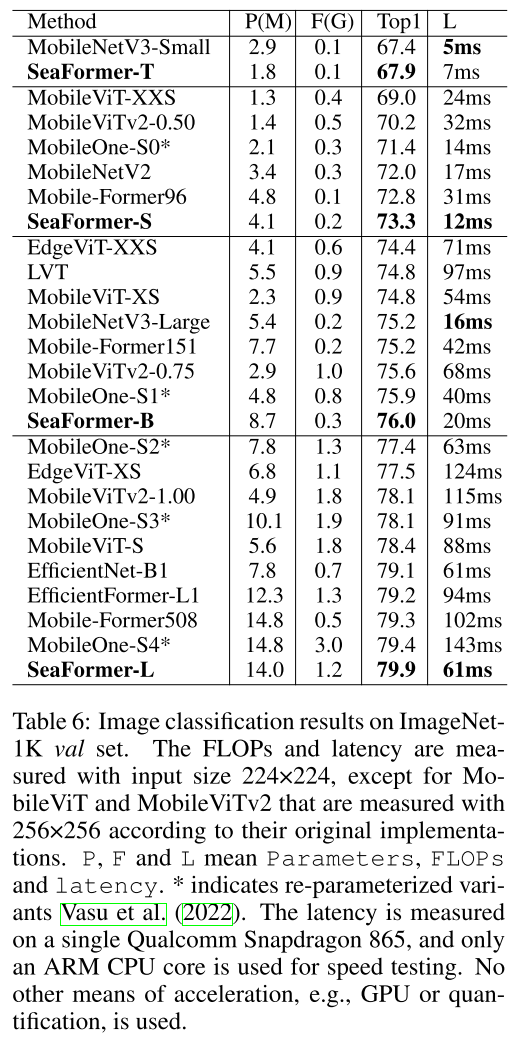
Mobile Former가 파라미터수 대비 FLOPs으로 가장 연산량을 줄여놓긴 했는데, Latency를 보면 그게 꼭 빠르지만은 않음.
4.5. Latency statistics
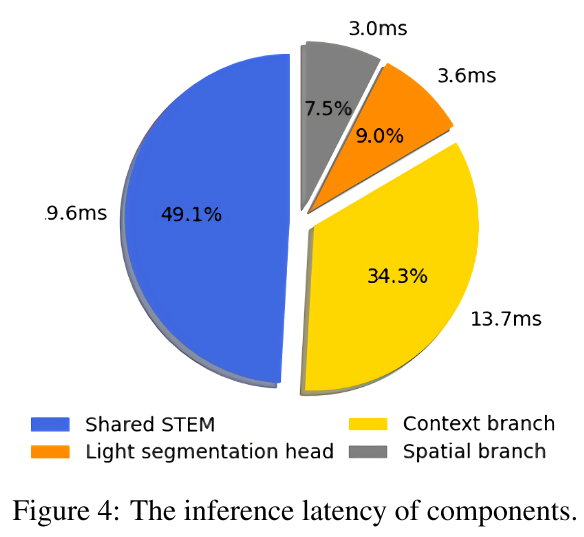
SeaFormer Tiny 기준.. 그림에 시간이랑 퍼센트가 매칭이 잘 안되어있는데, 시간이 잘못 써있는 듯..?
6. Appendix
architectures
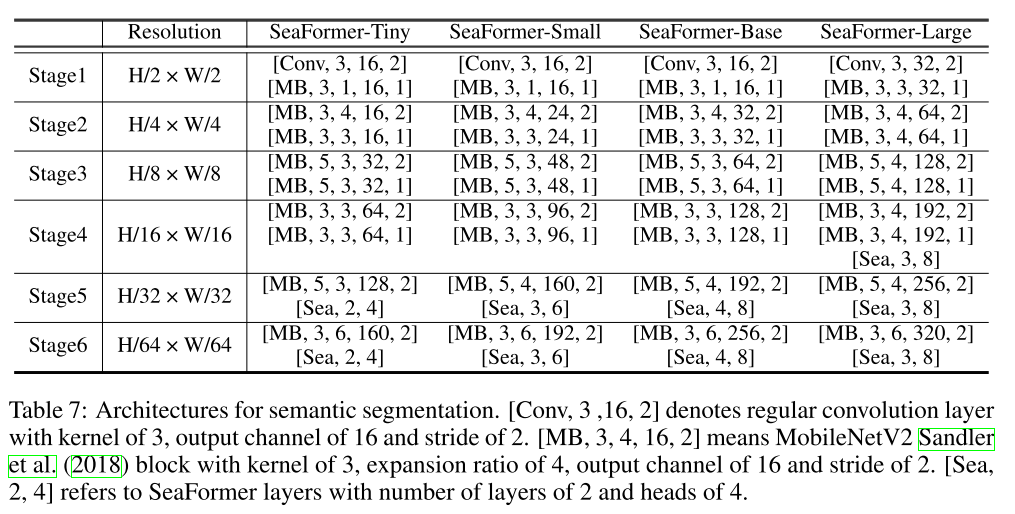
total time complexity
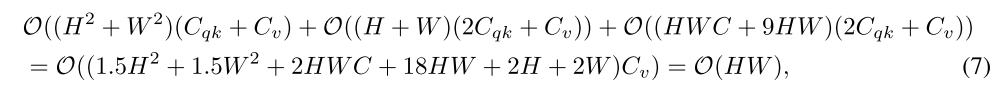
Pascal Context val set
COCO-Stuff test set

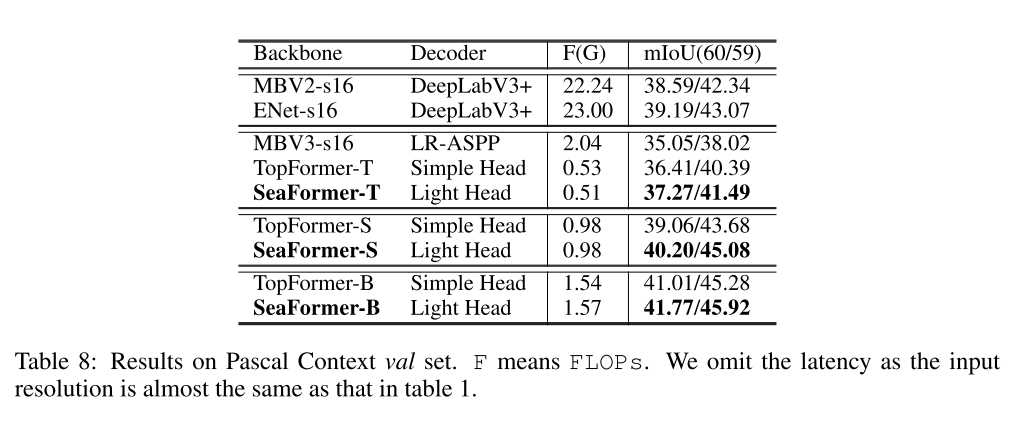
COCO object detection
fusion method

attention weight 곱해주듯 sigmoid multiply가 제일 낫더라
effectiveness and efficiency of SEA attention
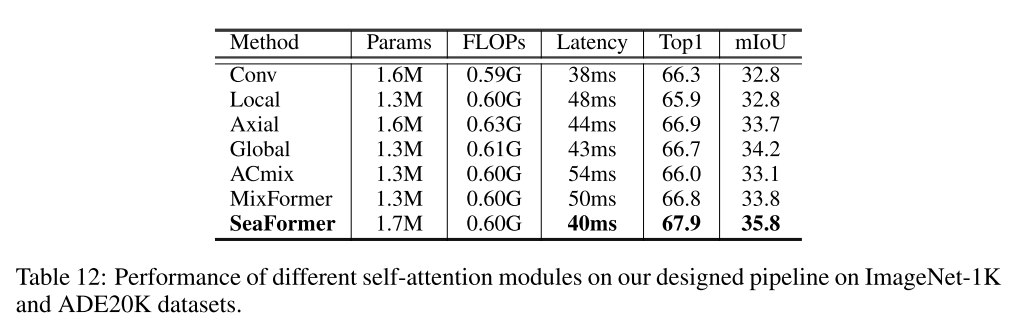
논문에서 설계한 pipeline에서 FLOPs를 비슷하게 parameter를 셋팅해서 다른 attention block들과 비교했을 때에도 SEA attention이 가장 효과적이더라
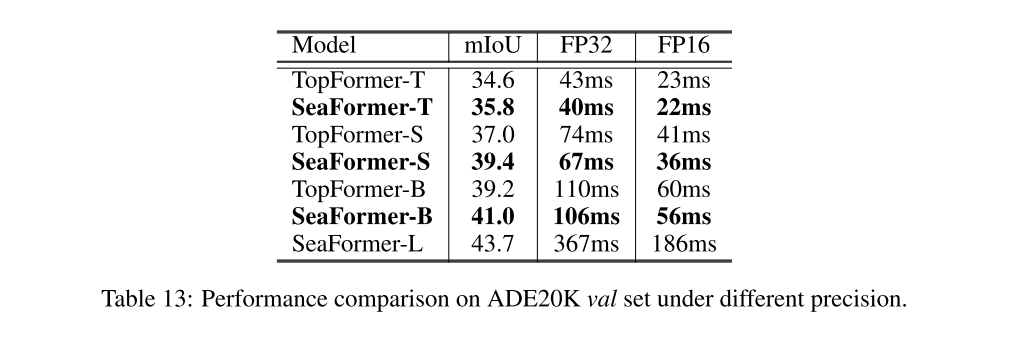
different precision
attention heatmap

마지막 attention block에서 나온 feature를 channel 방향으로 average한 후 0, 255로 normalize하고 image size로 upsample한 heatmap.
detail enhancement이 있어야 local한 region을 배운 것으로 보임
prediction results


Comments
기존의 Axial attention/local attention을 예로 들어가며 horizontal/vertical 각 방향으로 squeeze한 다음에 각각 attention해서 합쳐주고 잃어버린 local detail을 따로 보상하는 kernel을 둠으로써 efficient한 axial attention mechanism을 소개하며 전체적인 architecture 뿐만 아니라 Swin에서도 소개하는 SeaFormer pipeline에서도 다른 attention block들과 비교 실험으로도 그 우수성을 입증했으므로 기여도가 높아보임.
TopFormer와 비교하여 parameter수는 약간 증가하나 같은 FLOP 대비 성능이 개선되는 것을 보임. 실제로 실험으로 비교했을 때에도 그러한 결과가 보임.. bye TopFormer
Stem layer로부터 온 feature를 context branch로 통과시키고 나온 1/2 작은 resolution의 high-level semantic feature를 upsample해서 semantic weight을 만들줘서 곱해주는 방식으로 spatial branch와 segmentation head가 decoder에 해당한다고 보면 될 것 같다.
SEA attention이 detail enhancement가 있긴 하나, detail을 더 보상해줄 필요가 있어 spatial branch로부터 low-level의 feature로부터 1/8를 유지하면서 context 정보를 fusion하여 segmentation head에 넘겨주는 느낌
