[2023 CVPR] Revisiting Weak-to-Strong Consistency in Semi-Supervised Semantic Segmentation
Paper Review
Nanjing University, Southeast University, SenseTime Research에서 2022년 arXiv에 올린 연구로 2023년 4월 10일자까지도 Semi-Supervised Semantic Segmentation의 많은 벤치마크에서 SOTA를 달성하고 있는 UniMatch라는 방법을 리뷰하려고 함.
2023 CVPR accept 논문
https://github.com/LiheYoung/UniMatch
Abstract
semi-supervised classification에서 FixMatch로 대중화된 weak-to-strong consistency framework (약하게 perturbed image의 prediction으로 강하게 perturbed image로 supervised하는 방법) 를 revisit
이 논문은 supplement로써 auxiliary feature perturbation stream과 공통의 weak view로부터 두 개의 strong view를 동시에 guide하는 dual-stream perturbation technique를 제안함. 이걸 통합한 Unified Dual-Stream Perturbations approach를 줄여 UniMatch라고 명명하여 제안하고자 함.
FixMatch를 발전시킨 형태의 Semi-supervised Semantic Segmentation Framework
Introduction
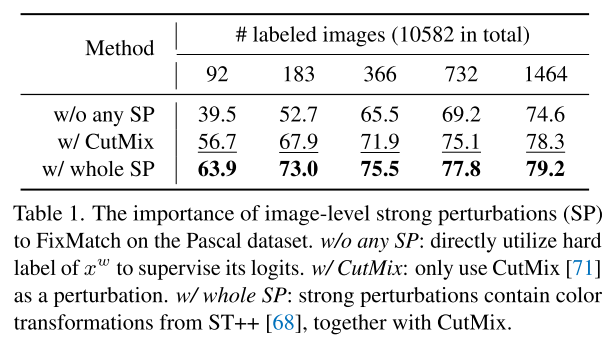
FixMatch에서 image-level strong perturbation의 중요성
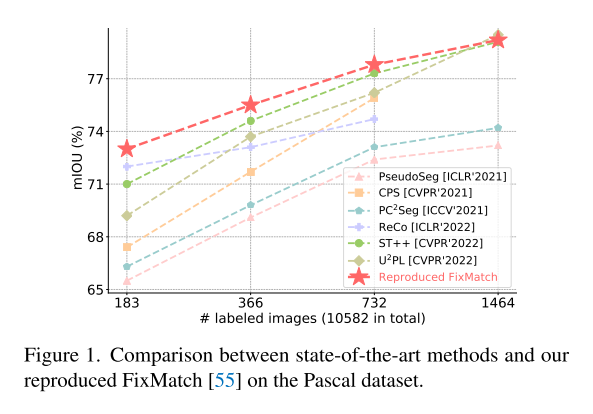
FixMatch에서 augmentation 방법만 갈아끼워줬는데, 최신 semi-supervised segmentation 방법들을 앞선다.
하지만 image-level perturbation만 하면 다양한 level에서 perturbation space를 학습하지 못한다. 이 연구는 FixMatch의 weak-to-strong consistency한 전략에 따라 feature-level과 image-level 둘 다에서 perturbation하여 최신 semi-supervised segmentation framework를 소개한다.
Method
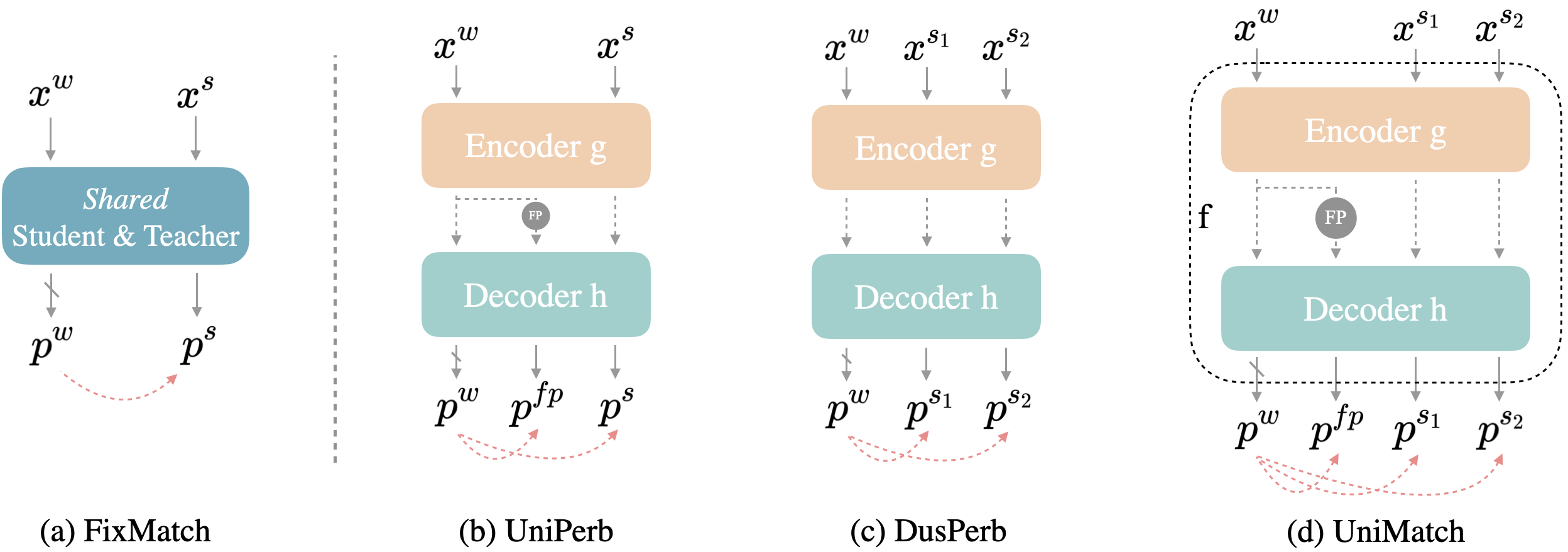
(a) FixMatch - student와 teacher가 shared된 network에서 stronly perturbation된 (aug) 를 weakly perturbed image 로부터 나온 와 비교하여 image level에서 student network가 weak-to-strong consitency를 지키도록 함
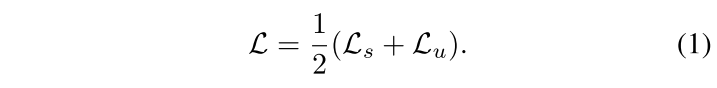
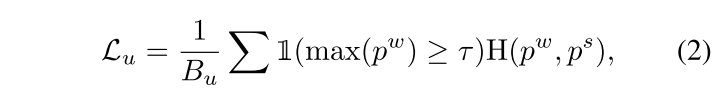
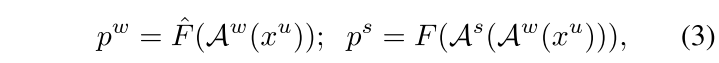
: weak augmentation like cropping, : strong augmentation like Color transformation
(b) UniPerb - feature level에서 perturbation하여 나온 , image level에서 를 strong augmentation 로부터 나온 를 weakly perturbed image 의 와 비교하여 image level, feature level 둘 다에서 weak-to-strong consitency를 지키도록 함
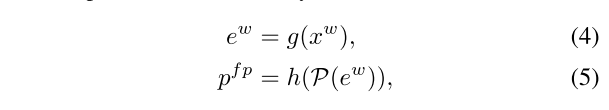
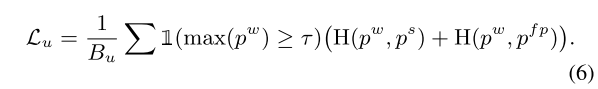
(c) DusPerb - image level에서 weakly perturbed image 에서 다른 random seed로 strong perturbation한 , 의 예측 , 를 의 결과인 와 비교하는 scheme
image-level에서 strong perturbation하는 것은 굉장히 큰 이득을 가져왔었음. unlabeled data를 입력으로 multiple view를 구성하는 것이 perturbation을 더 leverage할 수 있다는 최근 self-supervised learning과 semi-supervised classification에서 최근 진보가 인상이 깊었다고 함.
SwAV에서 다양한 크기의 view들의 bag 안에서 local-to-global consistency를 강제하는 multi-crop을 제안했고 ReMixMatch는 모델이 배울 수 있는 multiple strongly augmentation version을 만들었냈었다.
Semi-supervised semantic segmentation에서도 이런 게 통할까 싶어 2개의 strongly perturbation된 image를 사용하는 dual-stream perturbations을 사용해봤고 FixMatch로부터 이런 사소한 수정만으로도 큰 성능 향상이 있었고 SOTA를 달성했다고 함.
더 직관적으로 에 의해 예측하는 class의 classifier weight을 라고 하고 (, )의 feature를 (, )라고 했을때, 적용한 Cross Entropy Loss는 와 을 최대화하는 것이고 , 간의 similarity를 최대화하는 것으로 볼 수 있으므로 InfoNCE loss를 만족한다고 볼 수 있다고..
이와 같이 dual-stream perturbation은 contrastive learning의 spirit을 공유한다고 함

(d) UniMatch - UniPerb, DusPerb를 합친 꼴로 , , 를 와 비교하는 scheme
feature level에서 perturbation으로 consistency를 지키는 동시에 dual-stream perturbation으로 두 개의 다른 strong view를 weakly perturbed view랑 consistent하게 만드는 효과
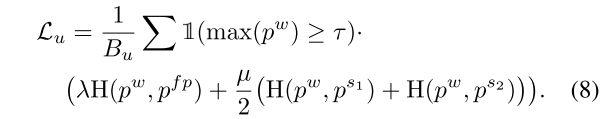
와 는 0.5, confidence threshold 는 0.95 (Cityscapes만 0)

Experiments
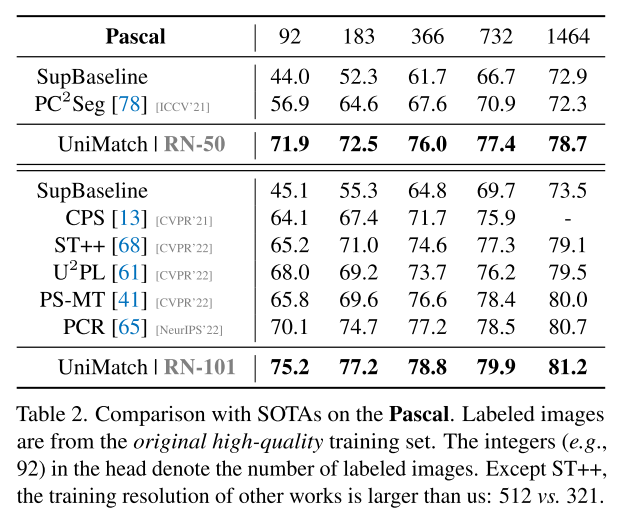
Pascal, labeled images are from the original high quality training set

Pascal, labeled images are from the blended training set
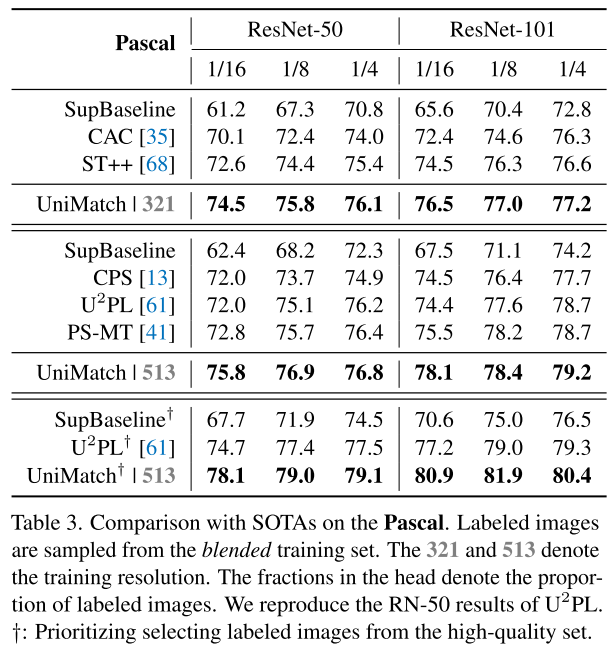
Pascal 데이터셋은 high-quality label 1464과 이후에 추가된 coarse한 label 10582이 있는데, high-quality set으로부터 label image를 선별하는 것을 우선시하도록 하는 방법을 쓴다고도 함.. high quality가 역시 좋구낭
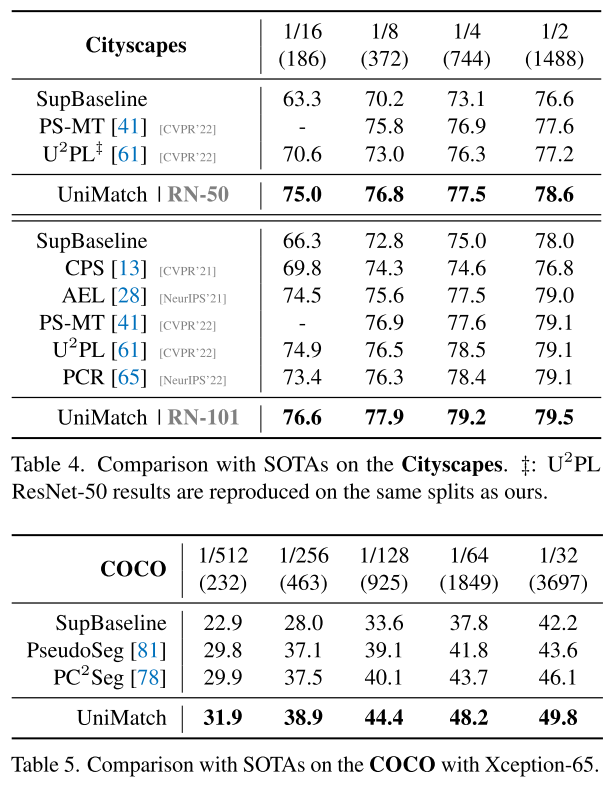
COCO는 81개 class로 저 중에서 가장 어려운 benchmark고 semi-supervised segmentation에서 잘 안 다뤘었는데, 거기서도 SOTA를 달성하였음을 보여줌
Ablation Study
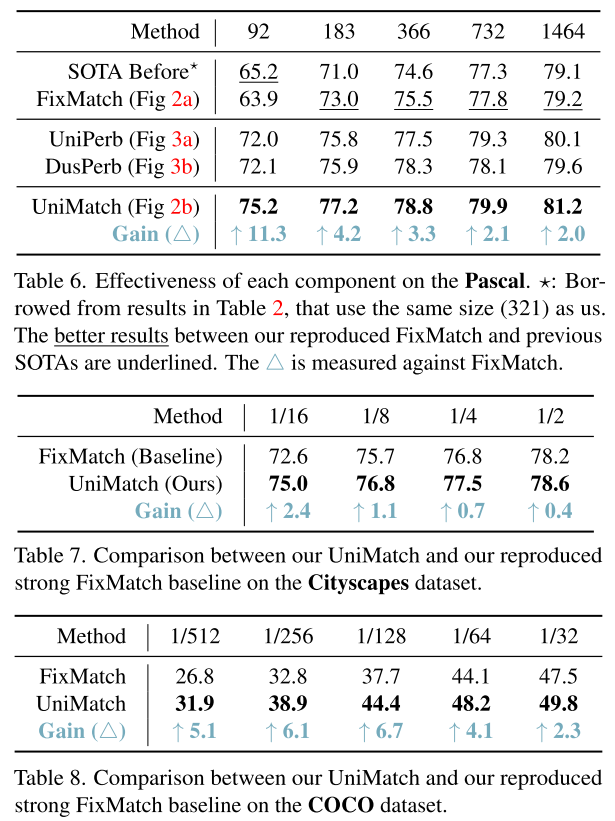
UniPerb (feature perturbation 추가한 것도), DusPerb (strong view 하나 더 추가한 것) 둘 다 label이 더 적을 때 성능이 빠르게 확보하는데, 효과적으로 representation을 배울 수 있게 한다고 추정
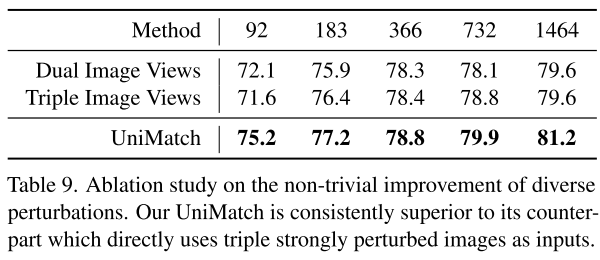
Dual Image Views = DusPerb, 세 개의 image를 perturbation하는 게 나을 수도 있어보이지만, non-trivial하다고 보기 힘듬
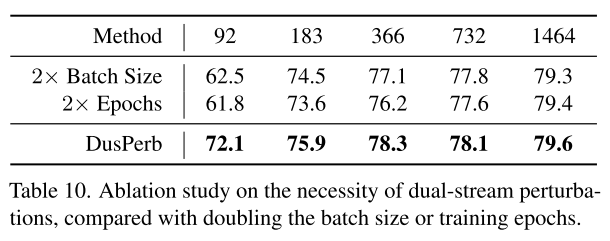
DusPerb이 batch size가 커졌으니 성능이 오른 게 아니냐고 말할 수 있어서 FixMatch에서 unlabeled image에서 batch 크기를 2배하면 DusPerb의 strongly perturbation하는 이미지 사이즈와 동일한데, 그렇게 했을 때에 dual-stream으로 한 게 DusPerb가 훨씬 나은 성능을 보이더라
DusPerb는 동일 sample을 서로 다른 strong perturbation한 두 개를 사용하는 거고, batch 수를 키우는 건 sample 수가 많아지는 거라 한 샘플의 strong한 variation을 dual하게 비교하는 것이 infoNCE loss로 비유했듯이 효과가 확실히 있는 듯.
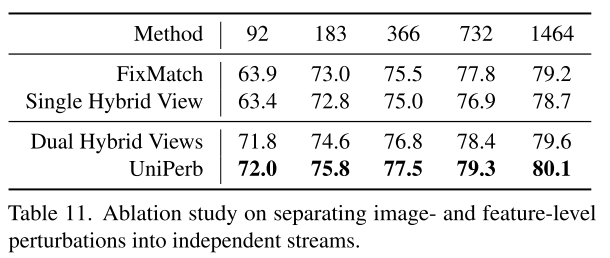
imag-level perturbation과 feature-level perturbation을 안 나누고 image-level에서 흔들고 feature-level에서 또 흔드는 hybrids는 성능이 오히려 하락함. 서로 다른 성질을 가진 perturbation은 independent stream으로 분리해야 모델이 target한 invariance를 좀 더 직접적으로 달성하게 할 수 있다고 말하고 있음
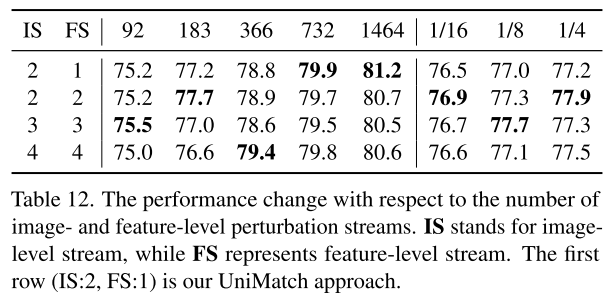
더 많은 perturbation stream을 실험해봤는데, 어느 정도 이상으로 많아지는 건 더 높은 성능을 못 내고 IS-2 FS-1인 UniMatch가 충분하다고 보았음
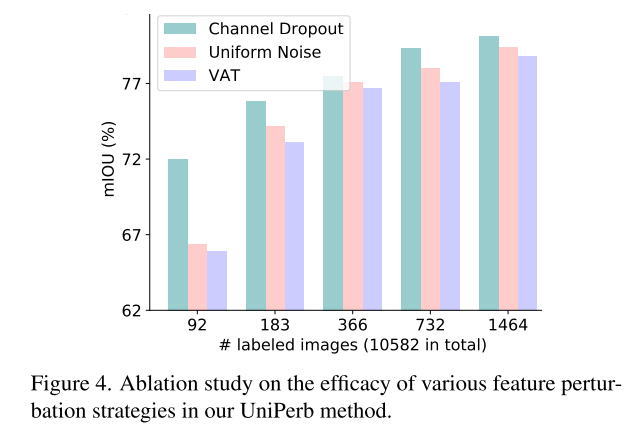
virtual adversarial training (VAT)
feature perturbation 방법 몇 개를 비교해봤는데, 간단한 Dropout이 가장 효과가 좋더라
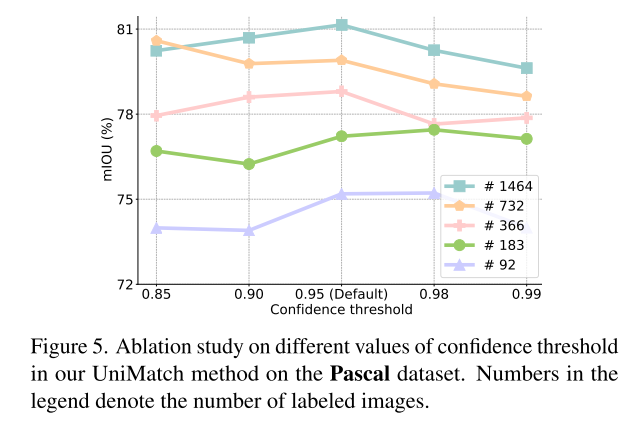
Pascal에서 해봤을때, 0.95가 best더라.. 이건 데이터셋따라 다를 수 있음

feature perturbation 위치를 encoder와 decoder 사이로 했는데, final classifier의 input을 사용한 perturbation도 있어서 비교해봤는데, 자기네께 낫더라
Application to More Segmentation Scenarios
Remote Sensing Dataset (chagnge detection task)
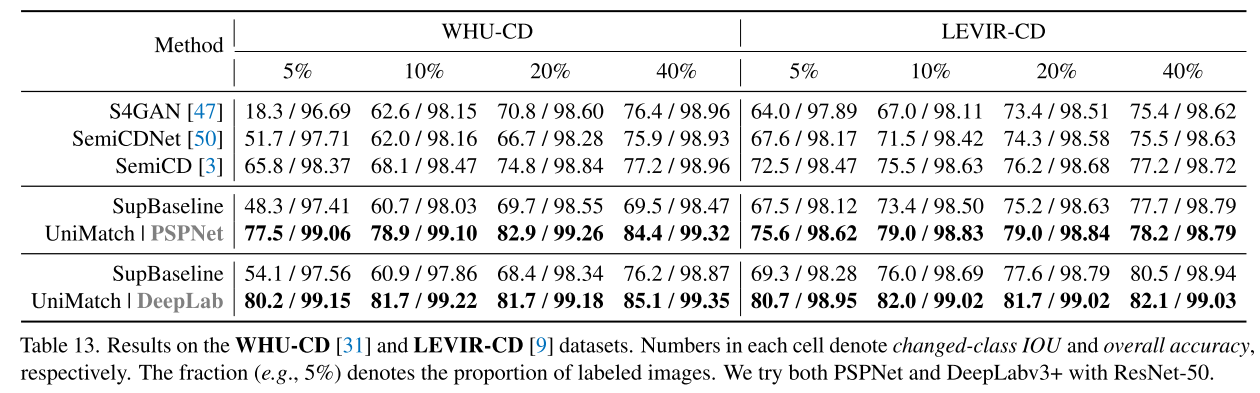
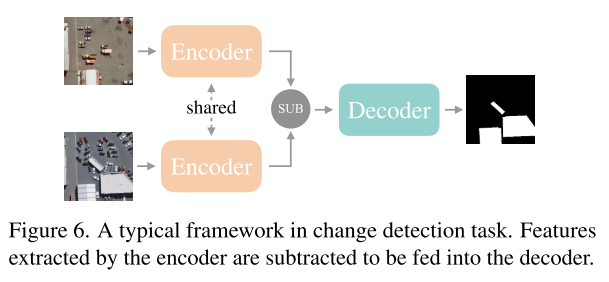
서로 다른 시간에 찍힌 같은 위치의 image 쌍인 bi-temporal images로 바뀐 영역을 highlight하는 task. 이 task의 유명한 benchmark, WHO-CD, LEVIR-CD에서 다른 semi-supervised segmentation 방법들과 비교해보았음
거기 최신 Semi-supervised segmentation 프레임인 SemiCD도 이김. 인상적
Medical Image Analysis
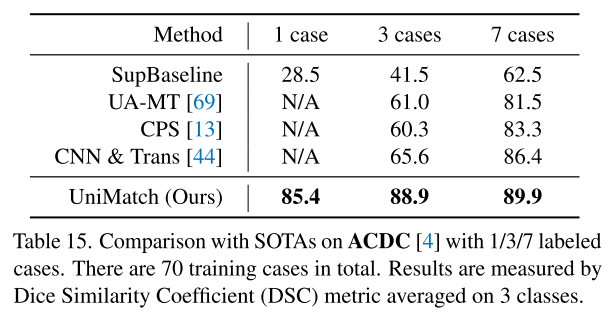
ACDC (Automated Cardiac Diagnosis Challenge, MRI 사진으로 심장 진단)에서 해봤는데, 놀랍게도 1 case때부터 엄청나게 성능을 잘 확보하더라
Conclusion
Semi-supervised semantic segmentation에서 FixMatch의 중요한 역할을 조사했다. 적절한 image-level perturbation만으로도 vanilla FixMatch가 SOTA를 충분히 이길수 있었고, 좀 더 diverse한 perturbation space를 형성하기 위해 image- and feature-level perturbations을 결합하는 방법인 UniMatch를 제안해 의미있게 성능을 끌어올릴 수 있었다. natural 뿐만 아니라 medical, remote sensing scenario에서 뚜렷하게 결과를 개선했다.
Comments
UniMatch.. concept이 어렵지 않아서 충분히 도입해서 적용해볼만하다.
CutMix가 pathology image에서도 효과적일까 싶긴 한데, 여기저기 잘 된다는 거 보니 적절하게 적용할 수 있도록 해봐야겠다
코드를 확인해보니 젤 윗단의 feature (texture한 정보) 과 아랫단 feature (semantic 정보) 둘 다 Dropout을 시키더라.. 확인해봐서 적용해봐야겠다