Research by Oregon State Univ., Apple Inc.

Abstract
기존 CNN의 grid downsampling strategy는 모든 영역을 동일하게 취급하기 때문에, 적은 영역에 있는 작은 object들은 segmentation 성능이 떨어진다.
중요한 픽셀을 배우는 adaptive downsampling을 수행하는 local-attention transformer, AutoFocusFormer (AFF)를 제안한다. 고전 grid 구조를 벗어나, a balanced clustering 모듈과 learnable neighborhood merging 모듈로 이루어진 point-based local attention block을 사용한다.
Introduction
Main Issue로 잡고 있는 게 segmentation에서 작은 object들은 이미지 내에 차지하는 pixel 수가 작고 기존의 regular grid 방식의 attention mechanism으로는 한계가 있다고 지적하고 있음. 이를 해결하기 위해 해상도를 높이거나 decoder 단에서 불규칙적으로 point를 sampling하는 방법들이 있었으나 결국엔 convolution과 같은 grid 방식에 기대고 있다고 함. global attention을 사용해 non-uniform/adaptive downsampling를 시도한 방식도 있었으나 ImageNet 해상도 보다 고해상도에서 수행되는 segmentation tasks에 scalable하지 않다. 이 연구는 그러한 문제점들을 해결하기 위해 AutoFocusFormer (AFF)를 제안하는데, 이는 저자들이 아는 한 최초의 end-to-end segmentation network with successive adaptive downsampling stages다.
Contribution 요약
- adapative downsampling과 flexible downsampling rate를 사용한 첫 end-to-end segmentation network
- 불규칙적으로 위치한 토큰들에서 local attention을 하기 위해 토클들을 이웃에 group하는 balanced clustering 알고리즘과 adapative downsampling의 end-to-end learning이 가능하게 하는 neighborhood merging 모듈을 제안
- deformable DETR, Mask2Former, HCFormer 와 같은 SOTA 디코더들을 토큰들이 불규칙적으로 배열 상에서 동작하도록 적용함
- image classification 및 segmentation 둘 다 더 적은 FLOPs로 SOTA를 달성하고 instance segmentation task에서 small object를 인식하는 것에서 유의미하게 개선함.
3. Method
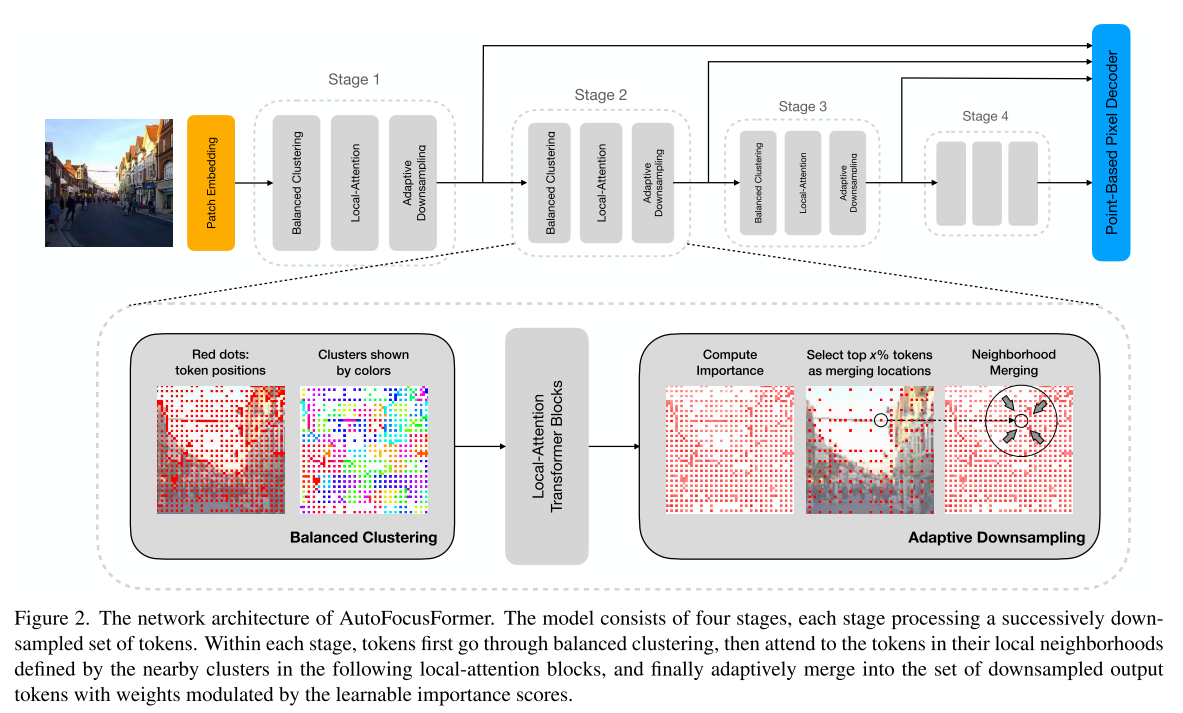
3.1. Clusters and Neighborhoods
2D에서는 사각 윈도우 단위로 local neighborhood를 정의하는데, 정렬되지 않는 point set에서는 point간의 거리를 계산하는 k-nearest-neighbors (kNN)과 같은 알고리즘에 의존해 3D point cloud에서의 neighbors를 식별한다.
k-NN은 quadratic complexity를 가지는데, 이웃에 대한 search space를 줄이기 위해 given points를 사용한다. 이에 영감을 받아, local neighborhoods를 정의하는 것에 clusters를 사용한다.
K-means나 locality sensitive hasing과 같은 방법은 hasing을 여러 번 해야해서 신경망의 forward pass에 비해 느리다. 여기서는 2D point를 clustering하고 싶은 것이니, 그를 위한 방법을 따로 만들었다.
3.1.1. Balanced Clustering
2D location을 1D array로 arrange하고 동일 크기로 그룹으로 array를 나눈다.
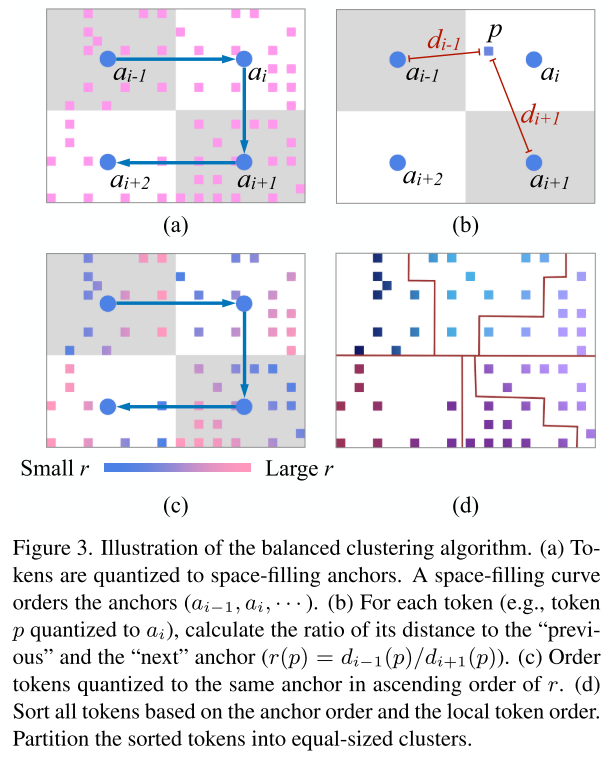
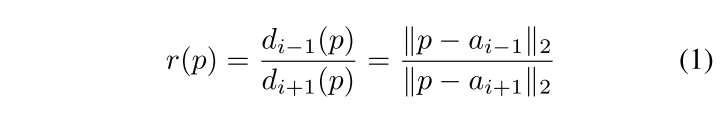
anchor에 에 속한 a token , 이전 anchor와 다음 anchor의 거리의 비 ratio, 을 다음의 식으로 모든 token 에 대해서 계산하면 각 square patch에 대해 r의 ascending order로 token들을 order할 수 있게 되고, 그 전 anchor랑 가까울수록 앞쪽에 있게 된다.
그림 (c)를 보면 각 anchor 안에 있지만, r을 계산해 1D array로 표현가능하고 anchor 순서도 포함한 기준으로 1D array에 정렬시키고 같은 size로 clustering하면 그림 (d)와 같이 grouping이 가능해진다는 것이다. 정렬이 되있으니 quantile 처럼 partioning하면 되는 것 같다.
좌표를 간단히 quantizing하여 각 token마다 해당 space-filling anchor를 수행하는 데에 이내 라는 것을 알아냈고, 이는 local patch들에서 모든 token location을 한 번 정렬 (sort)해주는 것이어서 feature channel은 관여하지 않으니 전체 network time complexity에 비하면 무시가능한 (negligible) 수준이다. 알아둬야할 건, 이 clustering은 각 stage 시작에 한 번만 하면 된다는 것이다.
이전 prior balanced clustering 연구들과 비교해 not iterative, 완벽하게 balanced cluster를 만들 수 있다.
3.1.2 Neighborhoods from clusters
전체 이미지를 걸쳐서 정보의 흐름을 encourage하기 위해서 attention 같은 cluster에 있는 위치에만 제한되지 않는 것이 중요하다.
Swin Transformer에서는 consecutive layer들간의 shifting window를 사용해 서로 다른 layer에서 서로 다른 negihbor들을 attend할 수 있겠 했는데, 여기에서는 모든 layer에서 re-clustering하는 건 원치 않는 연산량을 늘리게 된다. 그래서 좀 더 작은 cluster들을 사용해서 각 token들을 R 근처 cluster로부터 온 token들과 attend할 수 있도록 한다. 이웃이 overlapping되어있어 cluster간의 정보 교환을 보장하니 이득이 있다고 말한다.
3.2. Transformer Attention Blocks
각 token을 이웃한 모든 다른 token와 attend하도록 계산하는 상대적 위치 임베딩 정보를 가진 하나의 single head의 local attention A은 아래와 같이 계산됨
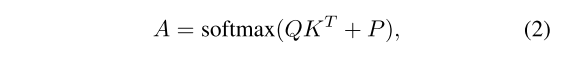
P는 A와 같은 dimension의 position embedding으로 다음과 같이 표현되는데, pi, pj는 서로 이웃한 두 토큰의 x, y 좌표들이다.
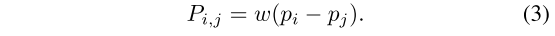
고정된 크기의 이웃을 가진 경우엔 relative position embedding이 matrix으로 저장될 수 있고 필요할 때 읽어들일 수 있어야하는데, 여기서 제안하는 모델의 경우, 이웃의 위치를 그전에 모르므로 position embedding에 대한 좌표들의 차이를 learnable한 function을 통해 project해야한다. 여기서 저자들은 w를 하나의 fully connected layer로 구현했다.
3.3 Adaptive downsampling
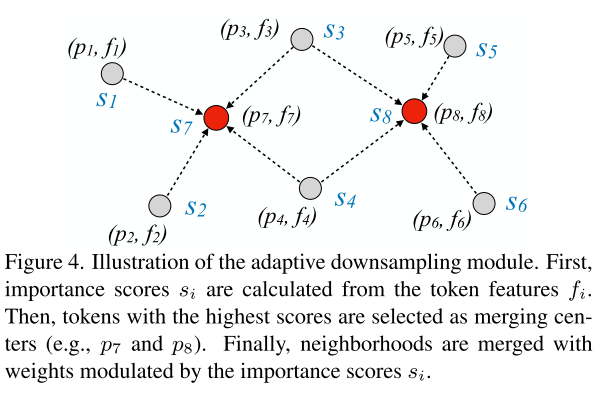
각 스테이지의 끝에 downsampling 모듈을 쓰는데, 가장 중요한 token을 고르는 learnable scoring과 선택된 token들을 둘러쌓은 이웃들을 merge하는 the neighborhood merging 단계로 구성된다.
3.3.1 Learnable Importance Score
task loss에서 -th token의 중요성을 나타내는 scalar score 을 예측하도록 하는데, downsampling이 선택된 token의 갯수를 제한하므로 학습이 어렵다. 만약 task loss가 선택된 토큰들에 대해 only backpropagated되면 선택되지 않은 토큰들은 아무런 gradient를 받지 못한다. 모든 token으로 gradients를 backpropagate하기 위해 neighborhood merging process에서 conjunction 하며 각 토큰의 importance score를 배우는 것을 제안한다..
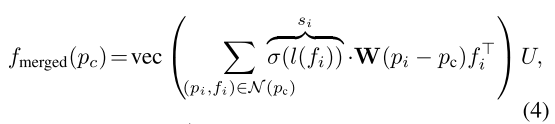
이 식은 PointConv에서 하나의 continuous convolution layer와 유사한데, 여기서 저자는 를 더해 모델이 다음 스테이지에 사용될 feature는 가져가면서 이웃 결합 (neighborhood merging)하면서 중요하지 않은 token들은 "turn off"하도록 했다. score 는 모델이 토큰을 얼마나 중요하다고 생각하는 지를 의미하는 indicator로 볼 수 있다.
이러한 수식은 이전 연구의 policy gradient와 같이 비용이 큰 기술에 의존할 필요 없이 task loss로부터 직접 score 를 배울 수 있게 해준다.
3.3.2 Grid priors and Selection of Tokens to Sample
최종 스코어는 하이퍼파라미터 와 함께 스코어 와 grid prior 사이의 가중합 (weighted sum)인 , merging center로 토큰을 선택하는 데에 사용된다.
여기서 grid prior를 또 adaptive하게 만든다. (이미 불규칙적으로 놓여진 token에게 regular grid prior는 더 이상 의미가 없음)
adaptive prior 는 샘플된 토큰들의 local stride를 기반으로 local grid level를 정하게 되는데, 여기서 각 토큰에 그 토큰과 가장 인접한 이웃 사이의 거리가 되는 "stride" t_i = 를 할당한다. (반올림)
예로, 가장 가까운 이웃과 3 pixels 떨어져있으면 반올림해서 stride 는 4가 되고 , 가 로 나눠지는 모든 곳에 가 1로 할당한다.. (나머지는 0)
가 1이면 alternating pixels (2픽셀 간격, 픽셀을 번갈아가면서)에서 이고 가 2면 4 pixels 마다 이 되는 것..
게다가, j번째 stage에서는 , 가 로 나눠지는 모든 곳으로 무한대로 grid prior로 설정한다.
이런 token들을 'reserved (예약된) '로 부르며, forward pass 동안 image 내에서 remote regions 사이에 connectivity를 보장하도록 corase-grid tokens를 reserve (예약) 한다.
adaptive downsampling을 요약하면
1. 각 토큰의 importance score 를 얻는다
2. 각 토큰의 grid prior 를 계산한다.
3. 가장 큰 의 top-x%를 고른다.
4. 위의 식으로 neighborhood merging을 하여 다음 스테이지를 위한 결합된 토큰을 얻는다.
4. Implementation Details
4.2. Scale and Rotation Invariance
adapative downsampling mechanism이 small object와 large object에게 같은 수의 feature를 사용할 수 있도록 해주는데, 이게 그냥 position embedding하면 scale invariance를 달성하려면 어려움이 있어서 단순 x, y 좌표 차이인 relative position vector를 다음과 같이 확장했다고 한다.
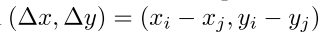
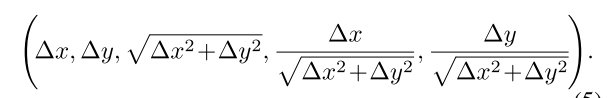
뒤에 세 개는 거리, cosine, sine인데, 거리는 rotation에 invariant하게 하고, angle은 scale에 invariant하도록 해서 scale-invariant하고 rotational-invariant한 임베딩을 할 수 있도록 해준다.
4.3. Blank Tokens
ImageNet에서 실험하면서 Swin과 AFF 모두에서 object랑 먼 texture가 적은 코너에 있는 토큰들에 큰 feature 정규화가 abnormally하게 나타났었다. strong gradient softmax가 가까이 있는 동일한 feature를 분리할 수 없어 생기는 문제라고 의심하고 이런 artifact를 제거하기 위해 i-th stage에 j-th transformer block의 모든 neighborhood (이웃)에 공유되는 학습가능한 blank token을 을 제안했다. 그러므로, 이웃에서 유용한 content가 없으면 softmax operator가 blank token에 attend하게 학습하게 해 texture가 별로 없는 영역에서 attention이 쪼개지는 시도를 피할 수 있다.
5. Experiments

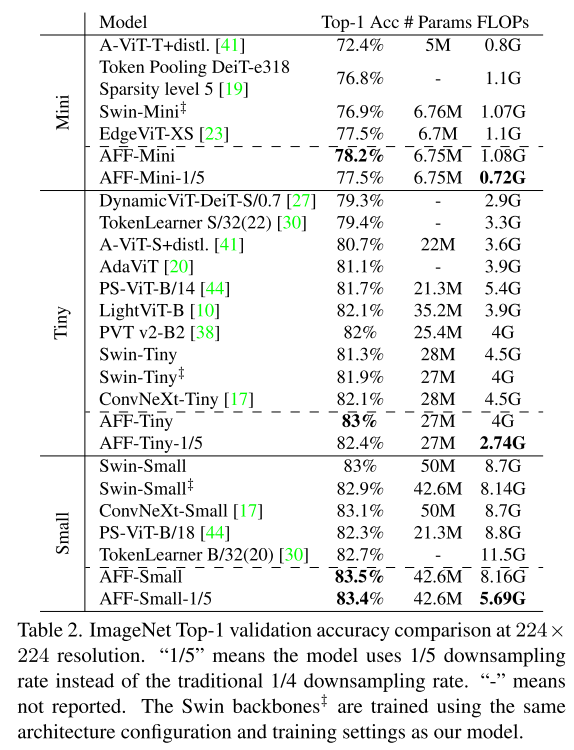
5.1. Image Classification on ImageNet-1K
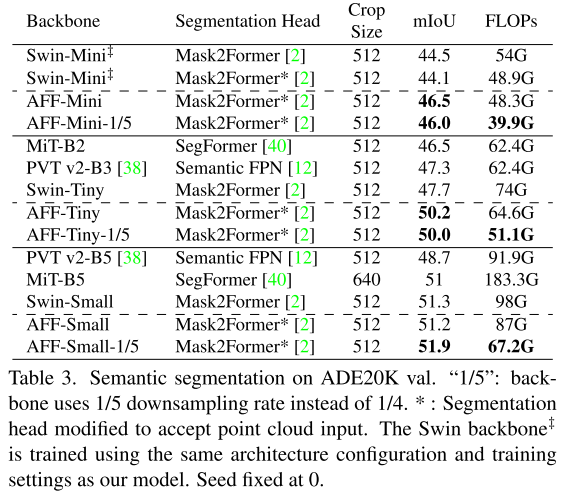
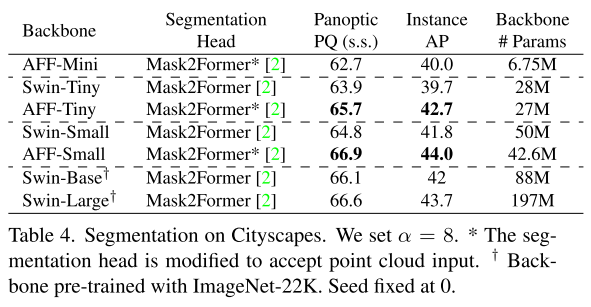
5.2. Segmentation
5.3. Ablations
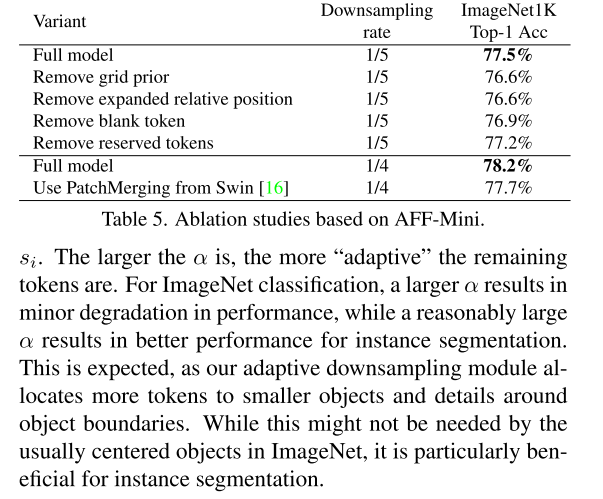
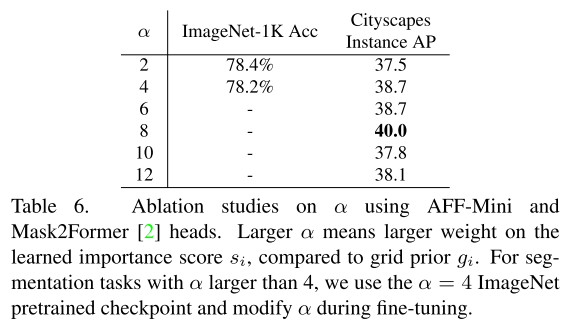
Comments
regular grid token을 모두 벗어난 end-to-end 방식을 만들기 위해 neighborhood, importance score를 정의해 학습 가능한 방법으로 network를 설계한 부분이 novel하다. 직관적으로는 이해했지만, 요소 요소가 복잡해서 engineering 적으로 수준높은 architecture라고 할 수 있을 것 같다.
ImageNet 같은 경우, image class가 large object에 대한 것일텐데, small object에 대해서도 잘 배울 수 있게 focus해가는 것이 더 성능이 좋아졌다는 것이 놀랍다.
engineering 적으로 수준 높게 설계된 것으로 보이고 정량적인 평가로 방법론의 우수함을 입증했지만, 질적인 평가가 별로 없어서 아쉽다.
논점이 전체 이미지 내에서 작은 픽셀수를 차지하는 small objects를 잘 인식할 수 있는 off-grid 방법을 제안한 것인데, 적어도 small objects에서 성능이 올랐는지는 보여줘야하는 것 아닌가 싶다..
아아 github repo (https://github.com/apple/ml-autofocusformer) 엔 이런 결과가 있긴 하다.. 좀 더 예시를 달라. 방법 요소요소 하나가 복잡해서 읽는데 오래 걸렸는데..

이전에 adaptive sampling을 ViT의 attention mechanism에 적용한 방법들 AdaViT, DynamicViT, A-ViT는 Swin보다도 성능이 안 좋은데, object 관련 points를 샘플링하는 게 비슷하게 deformable convolution이 있고 이걸 ConvNeXt에 적용하면 성능이 오르는 거 아닌가 싶다.

