1. 단일 서버
- 모든 컴포넌트가 하나의 서버에서 실행되는 간단한 시스템 설계
- 웹, 앱, DB, 캐시 등이 전부 서버 한 대에서 실행됨
1-1. 사용자 요청이 처리되는 과정

2. DB
2-1. DB 분류와 선택 기준
(1) 관계형 DB와 비관계형 DB 비교
| 관계형(R-DBMS) | 비관계형(NoSQL) |
|---|---|
| MySQL, 오라클, postgreSQL | CouchDb, Cassandra, Amazon Dynamo DB |
| 자료를 테이블, 열, 칼럼으로 표현 | 조인 연산 지원 X |
(2) 비관계형 DB(No SQL)
No SQL의 분류
- 키-값 저장소(key-value store)
- 그래프 저장소(graph store)
- 칼럼 저장소(column store)
- 문서 저장소(document store)
No SQL이 바람직한 경우
- 아주 낮은 응답 지연 시간이 요구됨
- 다루는 데이터가 관계형 데이터가 아닌 비정형 데이터인 경우
- 데이터를 직렬화(
serialize)/역직렬화(deserialize) 할 수 있기만 하면 됨 - 대량의 데이터를 저장하는 경우
3. 규모 확장의 방향(수직적/수평적)
3-1. 수직적 규모 확장(스케일 업) VS 수평적 규모 확장(스케일 아웃)
| 스케일업(수직적 규모 확장) | 스케일 아웃(수평적 규모 확장) |
|---|---|
| 서버에 고사양 자원을 추가 | 더 많은 서버를 추가하여 성능 개선 |
| 서버로 유입되는 트래픽의 양이 적은 경우 | 대규모 앱에 적합 |
스케일 업의 단점
- 규모 확장에 한계 존재
- 장애에 대한 자동 복구(
failover) 방안이나 다중화(redundancy) 방안 제시 X- 즉, 서버에 장애 발생 시 웹/앱은 완전히 중단됨
3-2. 로드 밸런서
- 부하 분산 집합(
load balancing set)에 속한 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할
(1) 사용자 요청이 처리되는 과정
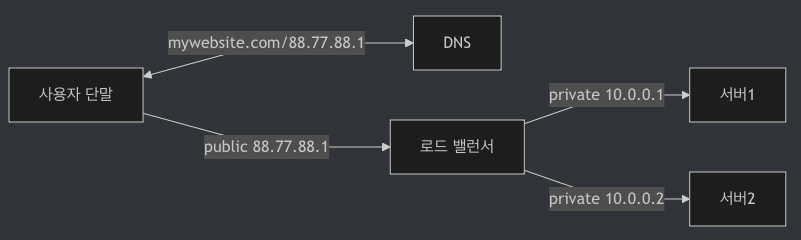
- 사용자는 로드밸런서의 공개 IP 주소로 접속
- 서버 간 통신에는 사설 IP 주소가 이용됨
(2) 웹 계층의 가용성 향상
- 서버 1 다운 시, 모든 트래픽은 서버 2로 전송
- 웹 사이트로 유입되는 트개픽 증가 시 웹 서버 계층에 더 많은 서버만 추가하면 로드 밸런서가 자동으로 트래픽 분산 시작
3-3. 데이터 다중화
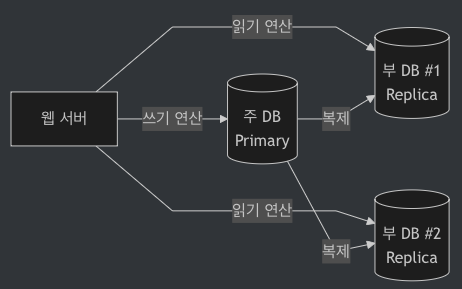
- 보통 서버 사이에 주(
master)-부(slave) 관계를 설정하고 데이터 원본은 주 서버, 사본은 부 서버에 저장하는 방식(Master-Slave 패턴)- 쓰기 연산은 마스터에서만 지원
- 부 DB는 마스터로부터 사본을 전달받으며, 읽기 연산만 지원
- 대부분의 앱에서는 읽기 연산 비중 > 쓰기 연산 비중 → 부 DB 수 > 주 DB 수
(1) 데이터 다중화의 이점
| 이점 | 설명 |
|---|---|
| 더 나은 성능 | 병렬로 처리될 수 있는 query 수 증가 > 성능이 좋아짐 |
안정성(reliability) | 서버 중 일부에 문제가 생겨도 데이터 보존됨 |
가용성(availability) | 서버 중 이룹에 문제가 생겨도, 다른 서버에 있는 데이터를 가져와서 계속 서비스 할 수 있음 |
(2) 데이터 다중화 아키텍처 패턴
- Master–Slave: 단일 쓰기 지점, 읽기 분산 (구현 단순, 장애 시 Failover 필요)
- Multi-Master: 모든 리전 쓰기 가능 (충돌 해결 필요, 고난도)
- Hybrid: 읽기는 로컬, 쓰기는 중앙 집중 (지연 최소화, 복잡도 증가)
(3) 데이터 복제 방식
- 동기(Sync): 모든 리전에 쓰기 반영 후 확정 → 일관성↑, 지연↑
- 비동기(Async): 로컬만 확정, 다른 리전은 나중에 반영 → 성능↑, 최종 일관성
- 반동기(Semi-sync/Quorum): 일부 리전만 확인 후 확정 → 절충안
3-4. 최종 설계
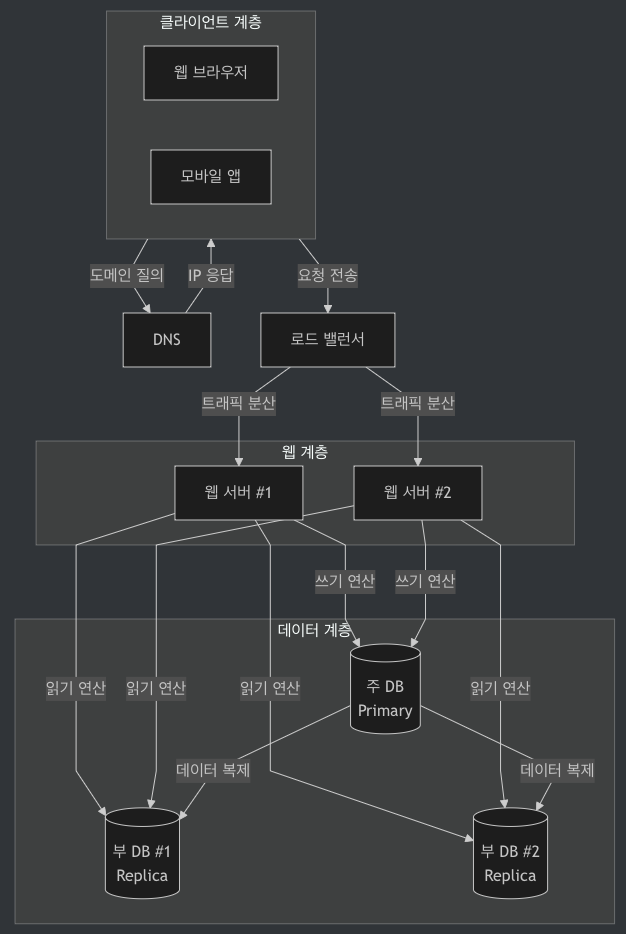
- 사용자는 DNS로부터 로드밸런서의 공개 IP를 응답 받음
- 사용자는 IP 주소를 사용해 로드밸런서 접속
- HTTP 요청이 서버 1 또는 서버 1로 전달됨
- 웹 서버는 사용자 데이터를 부 DB 서버로부터 읽음
- 웹 서버는 데이터 변경 연산은 주 DB로 전달
4. 캐시(응답시간 개선)
4-1. 캐시의 정의
- 자주 접근되거나 비용이 큰 데이터를 더 빠른 저장소에 일시적으로 보관해 두어 성능을 높이고 원본 자원(DB, API 등)의 부하를 줄이는 계층
4-2. 캐시의 목적
- 성능 개선
- DB 부하 감소
- 비용 절감
- 확장성 확보
4-3. 캐시의 핵심 속성
(1) 임시 저장소 (Temporary Storage)
- 캐시는 데이터의 사본을 보관할 뿐, 원본 저장소(DB, 파일, API)가 따로 존재
- 따라서 캐시 데이터는 언제든 무효화(invalidate)되거나 손실될 수 있음
(2) 빠른 접근 (Low Latency)
- 목표: 원본보다 빠른 접근
- 예: 메모리(RAM)에 데이터를 두어 디스크 I/O를 피함, 가까운 지역(에지)에 두어 네트워크 왕복을 줄임
(3) 투명성 (Transparency)
- 이상적으로는 애플리케이션이 캐시 유무를 의식하지 않고도 동작할 수 있어야 함
- 다만 Cache-Aside 패턴처럼 앱에서 직접 제어하는 경우도 많음
(4) 일관성 문제 (Consistency Trade-off)
- 캐시가 원본 DB와 항상 동일하다고 보장되지는 않음
- TTL(Time-to-Live), 무효화 정책, 쓰기 전략(Write-through, Write-back 등)을 통해 균형을 맞추어야 함
4-4. 캐시 전략
| 전략 | 동작 방식 | 장점 | 단점 | 사용 예시 |
|---|---|---|---|---|
| Cache-Aside (Lazy Loading) | 앱이 먼저 캐시 확인 → 없으면 DB 조회 후 캐시에 저장 | 구현 간단, 캐시 효율적 사용 | 첫 요청은 항상 DB 조회(캐시 미스) 쓰기 직후 캐시 불일치 발생 | 일반적인 웹 서비스 (뉴스, 게시판, 상품 조회) |
| Read-Through | 캐시가 DB와 직접 연동해 미스 시 자동 적재 | 앱이 단순해짐, 일관성 ↑ | 캐시 구현 복잡 캐시가 DB 클라이언트 역할까지 담당해야 함 캐시에 부하 집중 | CDN, 전용 캐시 계층 |
| Write-Through | 쓰기 시 캐시에 먼저 기록 → 캐시가 DB에 반영 | 항상 최신 데이터 읽기 일관성 보장 | 쓰기 지연, 불필요한 캐시 적재 가능 | 사용자 세션, 장바구니 |
| Write-Back (Write-Behind) | 쓰기 시 캐시에만 기록 → 일정 주기/조건에 따라 DB에 비동기 반영 | 쓰기 성능 극대화, DB 부하 감소 | 캐시 장애 시 데이터 유실 위험 → 내구성 확보(예: AOF, RDB 스냅샷) 필요 구현 복잡 | 로그 수집, 이벤트 처리 |
| Write-Around | 쓰기 시 DB에만 기록, 읽을 때 캐시 적재 | 캐시에 자주 쓰이지 않는 데이터 최소화 | 방금 쓴 데이터는 캐시에 없음(읽기 미스) | 잘 안 읽히는 데이터 많은 경우 |
| TTL 기반 캐싱 | 캐시 항목마다 만료 시간 지정 | 데이터 신선도 보장, 자동 갱신 | TTL 지나기 전까지는 구버전 가능, 적절한 TTL 설정 난이도 | 날씨, 주식 시세, API 응답 캐싱 |
4-5. 읽기 주도형 캐시전략(read-through caching strategy)
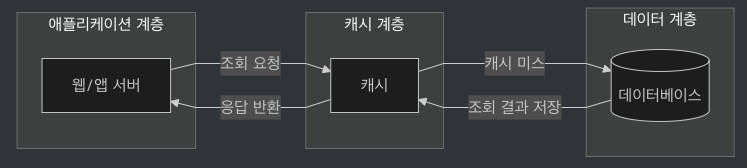
4-6. 캐시 사용 시 고려할 점
(1) 캐싱 적합성
-
캐시하기 적합한 데이터
- 자주 조회되는 데이터(Hot Data) → 반복 접근으로 히트율↑
- 조회 비용이 큰 데이터 → DB I/O, CPU 사용량 절감 효과 큼
(예: 복잡한 조인, 대규모 집계, 외부 API 호출 결과)
캐싱이 부적합한 데이터
- 항상 최신 상태가 보장되어야 하는 데이터 (예: 은행 잔액, 실시간 재고)
→ 캐시 지연으로 인한 불일치 허용 불가 - 영구적으로 보관해야 하는 데이터
→ 캐시는 본질적으로 임시 저장소이므로 적합하지 않음
(2) 만료/무효화 정책
- TTL(Time-To-Live) 설정
- 짧은 TTL: 데이터 신선도 보장 ↑, 하지만 캐시 미스율↑ → DB 부하 증가
- 긴 TTL: 히트율↑, DB 부하 ↓, 하지만 오래된(stale) 데이터 제공 가능성↑
- 핵심: 데이터 신선도 vs 효율성의 트레이드오프
(3) 일관성 유지
-
일관성 모델
- 최종 일관성(Eventual Consistency): 대부분 서비스에서 허용 가능
- 강한 일관성(Strong Consistency): 일부 요청은 반드시 DB에서 조회 필요
불일치 가능성
- DB와 캐시 갱신이 단일 트랜잭션에 묶이지 않으면 불일치 발생 가능
- 해결책:
- TTL 기반 자연 갱신
- 쓰기 시 무효화
- 이벤트 기반 캐시 업데이트
(4) 장애 내성
- SPOF(Single Point Of Failure)
- 캐시 서버가 단일 노드라면 장애 시 전체 서비스 영향
- 분산 배치(멀티 노드, 멀티 AZ/리전) 필요
- 캐시 장애 시 대응 전략
- 캐시 장애 → 모든 요청이 DB로 몰릴 때, DB가 감당 가능한지 고려
- Graceful Degradation: 캐시를 건너뛰고 DB fallback
- TTL 무시, 일시적 stale 데이터 허용 등으로 완충 가능
(5) 메모리 할당 용량
-
Underprovision (메모리 부족)
- 캐시 항목이 자주 퇴출(eviction)됨
- 캐시 히트율 저하 → 캐시 효과 상실
Overprovision (메모리 과다 할당)
- 데이터 오래 유지 가능 → 히트율↑, 트래픽 급증 대응 가능
- 단점: 비용/자원 낭비
- 일부 이론적 관점에서는 캐시의 “완충(buffer)” 역할을 중시하여 의도적 오버프로비저닝 권장
용량 산정
(평균 객체 크기 × 예상 동시 보존 수) + 여유분- 실제 필요량보다 20~50% 여유를 두는 방식도 존재
(6) 퇴출 정책(Eviction Policy)
- LRU (Least Recently Used): 가장 오래 참조되지 않은 항목 제거 → 일반적, 균형적
- LFU (Least Frequently Used): 참조 횟수 기반 제거 → 반복적 Hot Data에 최적
- TTL 우선: 만료 시간이 지난 데이터부터 제거 → 최신성 보장에 유리
- Random: 임의 항목 제거 → 단순 구현, 하지만 효율성 낮음
5. 콘텐츠 전송 네트워크(CDN)
5-1. CDN의 정의
- 지리적으로 분산된 여러 노드(에지 서버, PoP: Point of Presence)에 원본 콘텐츠의 사본을 저장하고,
- 사용자가 요청할 때 가장 가까운 노드에서 콘텐츠를 전달하는 분산 네트워크 인프라
5-2. CDN의 목적
- 지연(latency) 감소: 사용자와 가까운 에지 서버에서 응답해 네트워크 왕복 시간 단축
- 원본 서버 부하 감소: 반복 요청을 CDN이 대신 처리 → DB/애플리케이션/스토리지 보호
- 트래픽 분산: 대규모 트래픽(예: 이벤트, 스트리밍)을 전 세계 노드로 분산
- 가용성 및 안정성 향상: 일부 노드 장애 시 다른 노드로 우회 가능
- 보안 강화: TLS, 인증, DDoS 방어, WAF와 통합해 전송 계층 보안 확보
참고: 에지 서버(Edge Server)
- 위치: 사용자와 물리적으로 가까운 네트워크 경계(Edge)에 위치한 서버
- 역할: 원본 서버(Origin)에서 제공하는 콘텐츠 사본을 저장(캐시)하고, 사용자 요청 시 가장 가까운 위치에서 응답
- 특징:
- 전 세계에 분산된 CDN PoP(Point of Presence) 안에 배치됨
- 정적 리소스(이미지, JS, CSS, 동영상 등)를 캐시하여 응답 속도를 단축
- 일부 CDN은 동적 콘텐츠 처리, TLS 종료, 보안 기능(WAF, DDoS 방어)도 수행
5-3. CDN의 작동 원리
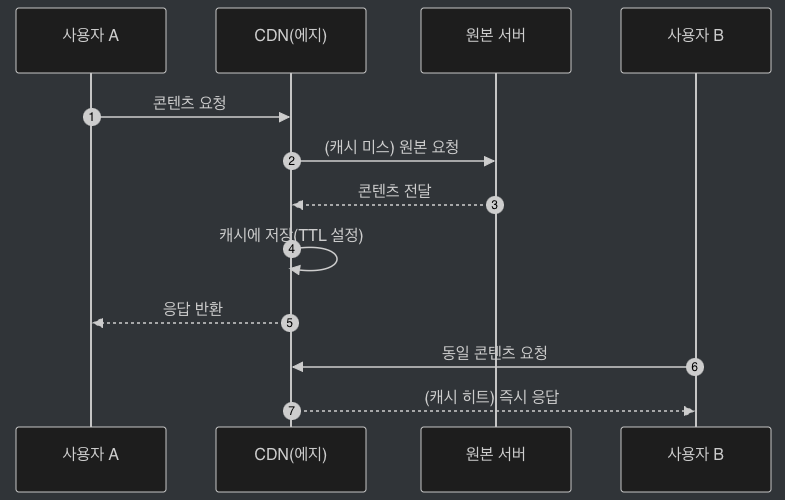
(1) 사용자 요청
- 사용자가
cdn.example.com/image.png요청
(2) 에지 서버 확인
- 요청한 콘텐츠가 캐시에 있으면 즉시 반환 (캐시 히트)
- 없으면 원본 서버(Origin)에서 가져와 캐시에 저장한 뒤 반환 (캐시 미스)
(3) 이후 요청
- 동일 지역의 다른 사용자도 같은 CDN 노드에서 캐시된 콘텐츠를 받음
- TTL/정책에 따라 캐시가 만료되면 다시 원본 서버에서 갱신
5-4. CDN 사용 시 고려할 점
- 캐시 가능 여부: 정적/동적 콘텐츠 중 어떤 것을 캐싱할지
- TTL 및 무효화 정책: 콘텐츠 신선도와 성능 균형
- 지리적 분포: 사용자 위치와 CDN PoP 분포 일치 여부
- 비용: CDN 트래픽/요청량 기반 과금 구조 확인
- 장애/Failover: 특정 노드나 CDN 전체 장애 시 대체 경로 확보 가능성
