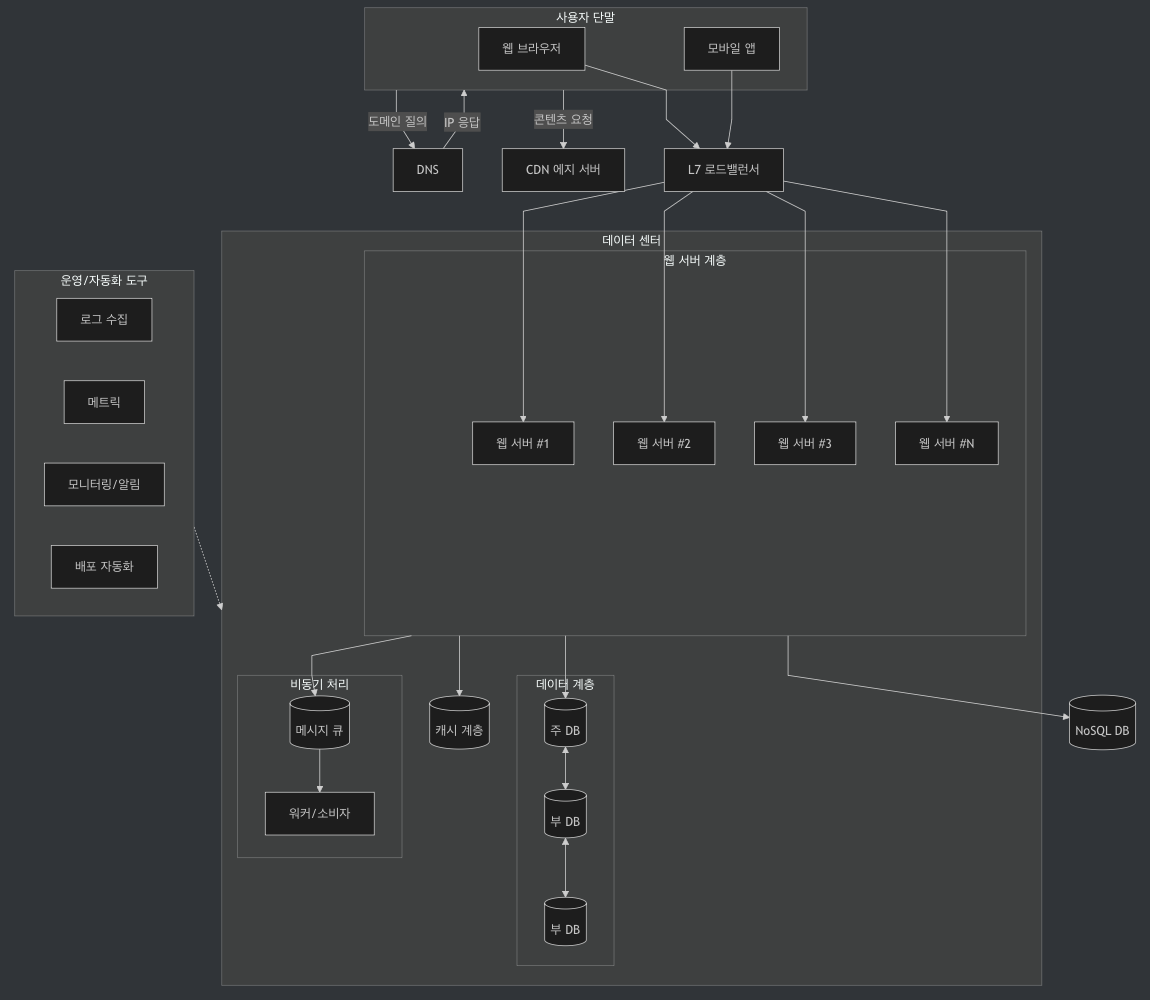
6. 무상태(statetless) 웹 계층
| 구분 | 상태 의존적 아키텍처 (Stateful Web Architecture) | 무상태 아키텍처 (Stateless) |
|---|---|---|
| 개념 | 웹 서버 인스턴스가 사용자 세션/상태 정보를 자체 메모리나 로컬 스토리지에 보관하는 방식 | 웹 서버는 상태를 저장하지 않고, 세션/상태는 외부 저장소(세션 스토어, 캐시, DB, JWT 등)에 위임 |
| 요청 처리 | 같은 사용자가 항상 같은 서버에 연결되어야 함 → 흔히 스티키 세션(Sticky Session) 로드밸런싱과 함께 사용됨 | 모든 요청이 독립적 → 어떤 서버가 처리해도 동일 결과 반환 |
| 특징 | 각 서버가 사용자 세션을 직접 관리 → 사용자별 상태 의존성 존재 특정 서버 장애 시, 해당 서버의 세션 정보는 유실될 수 있음 서버 수평 확장 시 세션 불균형 또는 마이그레이션 문제 발생 | Share-nothing 원칙: 서버 인스턴스 간 상태 공유 필요 없음 로드밸런서가 자유롭게 요청을 분산 가능 서버 확장/축소 용이 |
| 장점 | 구현 단순, 빠른 개발 추가 인프라 불필요 | 확장성 우수: 인스턴스를 자유롭게 증감 가능 가용성 높음: 특정 서버 장애에도 서비스 지속 배포 용이: 롤링/블루-그린/카나리 배포 유리 |
| 단점 | 확장성 제한: 특정 서버에 세션 집중 시 부하 불균형 가용성 낮음: 서버 장애 시 세션 유실 배포 어려움: 롤링 업데이트 시 세션 마이그레이션 필요 | 초기 구현 시 외부 세션 스토어/토큰 관리 등 아키텍처 복잡성 증가 네트워크 I/O 부하 (매 요청마다 외부 스토어 접근 시) |
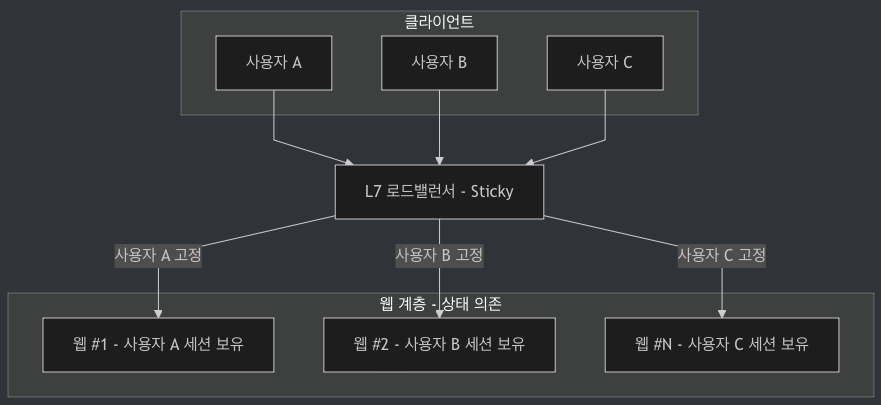
6-1. 상태 의존적 웹 아키텍처
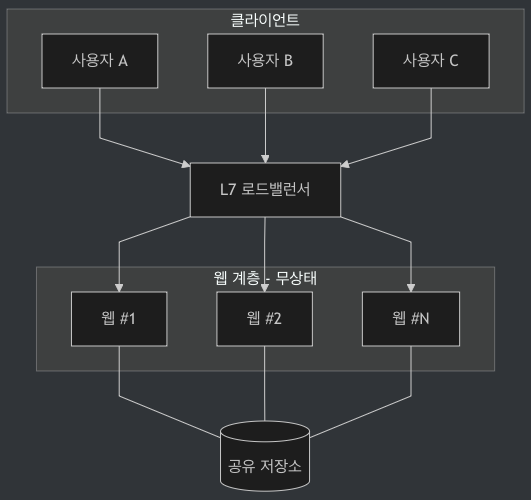
6-2. 무상태 웹 아키텍처
참고 - 배포방식
| 항목 | 카나리 | 롤링 | 블루-그린 |
|---|---|---|---|
| 전환 방식 | 일부 트래픽(예: 1~10%)만 새 버전으로 보내서 위험을 낮추는 점진 배포 | 같은 풀의 인스턴스를 조금씩 교체해 전체를 새 버전으로 전환 | 두 개의 완전한 환경(Blue=현재, Green=새 버전)을 준비해 두고 스위치(트래픽 전환)로 교체 |
| 장점 | 실사용자 트래픽으로 조기 검증 문제 시 빠른 롤백 | 무중단에 가깝고 인프라 비용 추가 적음 | 즉시 전환과 즉시 롤백 용이 배포 위험 최소화 |
| 단점 | 트래픽 라우팅 모니터링 복잡도 증가 | 상태 의존 구조에선 드레이닝/세션 처리 필요 전체 전환 시간 길 수 있음 | 두 환경 동시 유지 비용↑ 데이터/상태 동기화 고려 필요 |
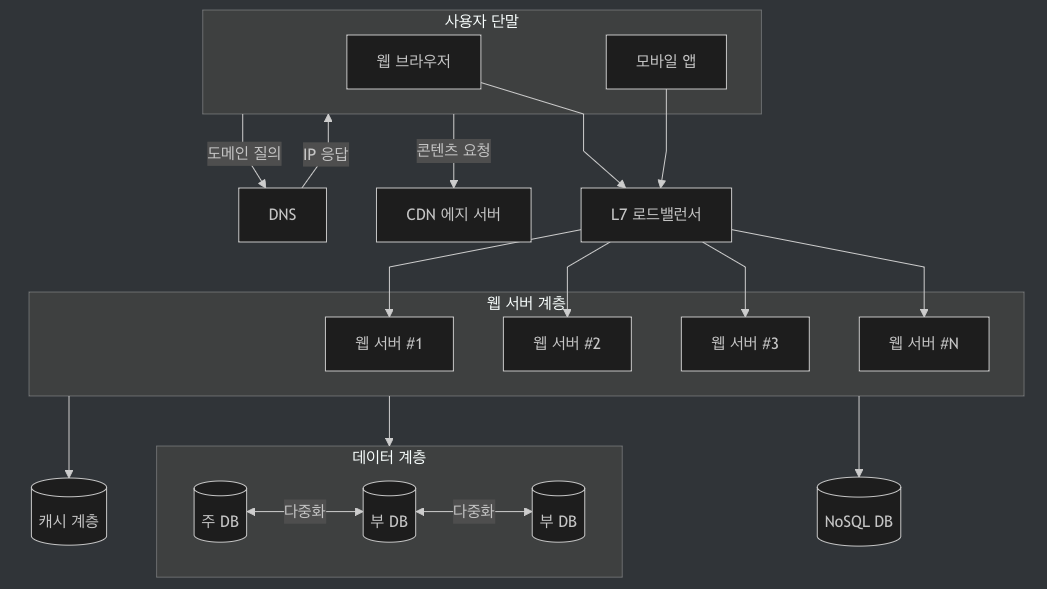
6-3. 최종 설계
7. 데이터 센터
7-1. 데이터 센터 (DC; Data Center)
(1) 정의
- 서버, 스토리지, 네트워크 장비, 전력/냉각 인프라를 집약해 대규모 IT 서비스를 운영하는 시설
(2) 역할
- 대규모 서비스의 안정성·확장성·보안 확보
- 클라우드(IaaS/PaaS/SaaS) 기반 물리적 토대
(3) 특징
- 이중화(전력, 네트워크, 스토리지 등)
- 보안성(물리/네트워크/운영)
- 확장성(랙 단위/리전 단위 확장)
(4) 실제 예시
- 구글 클라우드 리전 (미국·유럽·아시아) → YouTube, Gmail 서비스 기반
- AWS 서울 리전(ap-northeast-2) → 쿠팡, 네이버 일부 서비스 운영
- 네이버 데이터 센터 ‘각’ (춘천) → 친환경 냉각 활용
- 카카오 데이터 센터 ‘안산’ → 카카오톡, 카카오뱅크 인프라 운영
7-2. 지리적 라우팅 (Geo Routing / Geo DNS Routing)
(1) Geo Routing 정의
- 사용자의 지리적 위치(IP, DNS 질의 위치)에 따라 가장 가까운 데이터 센터 또는 CDN PoP로 트래픽을 분산시키는 기법.
(2) Geo Routing 방식
- GeoDNS: DNS 레벨에서 질의 위치 기반으로 IP 응답
- Anycast: 동일 IP를 여러 지역에서 광고 → 라우팅 프로토콜(BGP)이 가장 가까운 경로 선택
(3) Geo Routing 목적
- 지연(latency) 최소화
- 지역별 트래픽 부하 분산
- 특정 리전 장애 시 자동 우회 (Failover)
(4) 실제 예시
- Cloudflare Anycast 네트워크 → 전 세계 어디서든 동일 IP로 접속 시 가까운 POP 응답
- AWS Route 53 → 서울 사용자 요청은 서울 리전, 미국 사용자는 버지니아 리전으로 라우팅
7-3. 다중 데이터 센터 아키텍처 (Multi-Data Center Architecture)
(1) Active-Passive
- 하나의 센터만 Active, 다른 하나는 대기 상태
- 장애 시 Failover
- 예시: 금융권 DR 센터(재해복구 전용 데이터 센터)
(2) Active-Active
- 여러 데이터 센터가 동시에 트래픽 처리
- 지리적 라우팅으로 사용자 근처 센터에 연결
- 예시: Netflix → AWS 다중 리전에서 동시에 스트리밍 서비스 제공
(3) Hybrid
- 읽기 요청은 지역별 센터에서 처리, 쓰기 요청은 특정 리전으로 집중
- 예시: 글로벌 전자상거래 서비스(상품 조회는 현지 리전, 결제는 중앙 리전)
7-3. 고려사항 & 기술적 난제
(1) 트래픽 우회 (Traffic Routing & Failover)
고려할 점
-
사용자를 어떤 데이터센터(리전)으로 라우팅할 것인가?
장애 발생 시, 다른 센터로 신속하게 우회(Failover) 가능한가?
정상 복구(Failback) 시 데이터 일관성을 어떻게 맞출 것인가?
기술적 난제
-
DNS 기반 라우팅: TTL 캐싱으로 인해 우회 반영 지연
GeoDNS: 단순히 지리적 위치만 고려 → 실제 부하/장애 반영 한계
Anycast: 가장 가까운 경로 선택은 가능하나, 세밀한 트래픽 제어 불가
실시간 헬스체크 + 글로벌 로드밸런서 필요 → 구현 복잡
(2) 데이터 동기화 (Data Synchronization)
고려할 점
-
여러 데이터센터에 걸친 DB·캐시·세션을 어떻게 동기화할 것인가?
강한 일관성을 보장할지, 최종 일관성을 허용할지?
충돌(conflict) 발생 시 해결 방법은 무엇으로 할지?
기술적 난제
- 관계형 DB: 글로벌 트랜잭션 동기화 시 지연(latency) 증가, 성능 저하
- NoSQL / 분산 DB: 최종 일관성(Eventual Consistency) 허용 시 충돌 발생 가능
- 세션/캐시: 리전 분리 시 단순하지만, 글로벌 공유는 복잡도↑
- Conflict Resolution 필요 → Last Writer Wins, CRDT, Vector Clock 등
(3) 테스트 & 배포 (Testing & Deployment)
고려할 점
- 새 버전 배포 시, 모든 리전에 동시에 적용해야 할까?
- 일부 리전에만 배포해 안전성을 검증할 수 있을까? (카나리 방식)
- 다중 리전 배포 실패 시 롤백 전략은 무엇인가?
기술적 난제
- 배포 동기화: 모든 리전에 동일 버전·설정을 유지하는 것 자체가 어려움
- 카나리 배포: 특정 리전(일부 사용자 그룹)에만 새 버전 적용 → 글로벌 환경에서 트래픽 분리 어려움
- 블루-그린: 리전 단위 환경 전환은 가능하나, 비용·운영 부담 큼
- 데이터 스키마 변경: 순차 적용 과정에서 리전 간 불일치 발생 가능
8. 메세지 큐
8-1. 개념
- 메세지의 무손실(durability)을 보장하는, 프로세스나 서비스 간의 비동기 통신(
Asynchronous Communication)을 지원하는 소프트웨어 컴포넌트 - 생산자(Producer)가 메시지를 큐에 넣고, 소비자(Consumer)가 이를 꺼내 처리하는 구조
8-2. 역할
| 역할 | 설명 |
|---|---|
| 비동기 처리 지원 | 요청을 즉시 처리하지 않고 큐에 적재 → 나중에 처리 가능 생산자/소비자 간 실행 속도 차이를 완화 |
| 시스템 간 결합도 감소 (Decoupling) | Producer와 Consumer가 직접 연결되지 않고 큐를 매개로 통신 → 서비스 간 의존성 완화, 독립성 향상 |
| 버퍼링 (Buffering) | 갑작스러운 요청 폭주 시 큐가 완충 역할 → 소비자는 처리 가능한 속도에 맞춰 꺼내 처리 |
| 확장성 (Scalability) | 소비자 인스턴스를 수평 확장하면 큐의 메시지를 병렬 처리 가능 |
| 내결함성 (Fault Tolerance) | 소비자가 일시적으로 죽어도 메시지는 큐에 남아 손실되지 않음 → 장애 복구 후 다시 처리 가능 |
8-3. 작동 방식 (흐름)

- 생산자(Producer)
- 처리할 작업/데이터를 메시지 형태로 큐에 전송(Publish/Send)
- 메세지 큐 (Broker)
- 메시지를 안전하게 저장
- 메시지 전달 보장 방식 적용 (At-most-once, At-least-once, Exactly-once)
- 메시지를 Consumer에게 전달
- 소비자(Consumer)
- 큐에서 메시지를 가져와 처리(Subscribe/Consume)
- 처리 완료 후 ACK(확인 응답)를 보내면 큐에서 메시지 삭제
9. 로그, 메트릭 그리고 자동화
9-1. 사업 규모 확장 시 투자해야 할 도구들
| 구분 | 사업 규모가 커질 때 | 이유 |
|---|---|---|
| 로그 (사건 기록) | 서버 수십·수백 대 → 개별 확인 불가 중앙화·구조화 필요 (JSON 로그, ELK, Loki) 운영자/개발자가 공통 포맷으로 조회 | 단일 관찰점(Single Pane of Glass) 확보 필수 오류 분석, 보안 감사, SLA 추적 근거 |
| 메트릭 (상태 지표) | 호스트 단위 메트릭: 리소스 사용률(여전히 필요) 종합 메트릭: 응답 지연(p95/p99), 오류율, 트래픽, 포화도(Saturation) 핵심 비즈니스 메트릭: 주문 성공률, 결제 실패율, DAU/MAU, 전환율 등 SLO 기반 알림 체계 도입 | 로그는 “사후 분석”, 메트릭은 “사전 감지/예방”에 유리 대규모 환경에서는 서비스 지표+비즈니스 지표가 시스템 신뢰성과 직접 연결 |
| 자동화 (운영 지속가능성) | 자동화된 배포 전략 필요 (카나리, 롤링, 블루-그린) 메트릭 기반 알람 → 런북 자동 실행 (스케일아웃, 재시도, 롤백) IaC(Infrastructure as Code) 도입으로 환경 일관성 확보 | 운영자가 병목이 되지 않도록 시스템이 스스로 회복(Self-Healing)·확장(Auto-Scaling)해야 지속가능 |
9-2. 메세지 큐, 로그, 메트릭, 자동화 등을 반영하여 수정한 최종 설계