colab link
1. 최근접 이웃의 한계
# 50cm 농어의 이웃을 구합니다
distances, indexes = knr.kneighbors([[50]])
# 훈련 세트의 산전도를 그립니다
plt.scatter(train_input, train_target)
# 훈련 세트 중에서 이웃 샘플만 다시 그립니다
plt.scatter(train_input[indexes], train_target[indexes], marker ='D')
# 50 cm 농어 데이터
plt.scatter(50, 1033, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()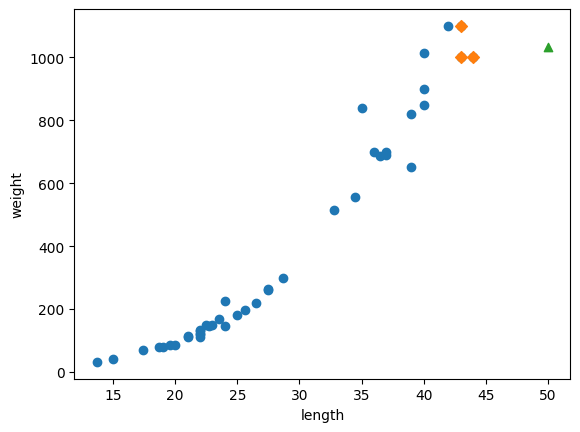
최댓값이 제한되는 단점이 있다.(샘플 범위 밖의 값을 예측하기 어렵다) k-nn은 가장 가까운 샘플을 찾아 타깃을 평균한다. 따라서 새로운 샘플이 훈련세트 범위를 벗어나면 잘못된 값을 예측한다.
# 100cm 농어의 이웃 구합니다
distances, indexes = knr.kneighbors([[100]])
# 훈련 세트의 산점도를 그립니다
plt.scatter(train_input, train_target)
# 훈련 세트 중에서 이웃 샘플만 다시 그립니다
plt.scatter(train_input[indexes], train_target[indexes], marker ='D')
# 100cm 농어 데이터
plt.scatter(100, 1033, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()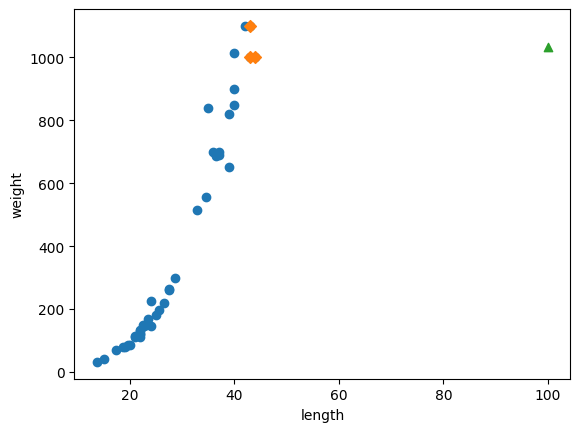
2. 선형 회귀
특성이 하나인 경우 직선을 학습하는 알고리즘이다. 데이터 패턴을 따르는 직선(방정식)을 찾는게 머신러닝 선형회귀 알고리즘이다.
LinearRegression 클래스에서는 선형회귀 방정식을 찾아 lr 객체의 coef_(계수)와 intercept_(절편) 속성에 저장한다.
lr = LinearRegression()
# 선형 회귀 모델을 훈련합니다
lr.fit(train_input, train_target)
print(lr.coef_, lr.intercept_) # 찾아낸 선형 방정식의 기울기와 y절편- 선형 회귀 알고리즘이 찾은 최적 직선
# 훈련 세트의 산점도를 그립니다
plt.scatter(train_input, train_target)
# 15에서 50까지 1차 방정식 그래프를 그립니다
plt.plot([15, 50], [15*lr.coef_ + lr.intercept_, 50*lr.coef_ + lr.intercept_]) # [x좌표] [y좌표]
# 50cm 농어 데이터
plt.scatter(50, 1241.8, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()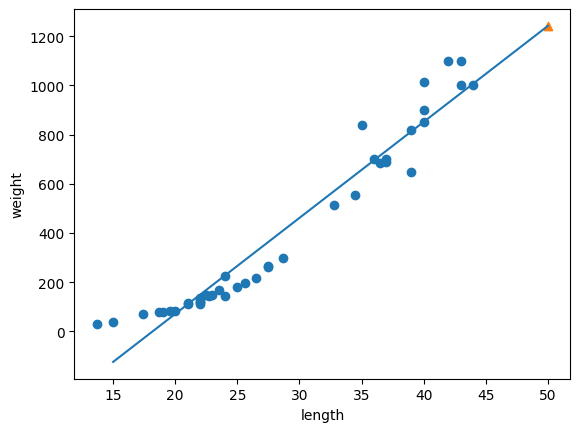
다만, 전체적으로 과소적합되었다는 문제점이 발생
3. 다항 회귀
일직선 모델을 적용하기엔 오류가 많음. 1차원 이상의 항을 가진 모델 필요 (최적의 곡선 필요)
다항식을 사용한 선형회귀를 다항회귀라 한다.
2차 방정식 그래프를 위해 훈련 세트 제곱
타깃값은 그대로 사용 함을 주의
train_poly = np.column_stack((train_input**2, train_input))
test_poly = np.column_stack((test_input**2, test_input))lr = LinearRegression()
lr.fit(train_poly, train_target)
# 구간별 직선을 그리기 위해 15에서 49까지 정수 배열을 만듭니다
point = np.arange(15, 50)
# 훈련 세트의 산점도를 그립니다
plt.scatter(train_input, train_target)
# 15에서 49까지 2차 방정식 그래프를 그립니다
plt.plot(point, 1.01*point**2 - 21.6*point + 116.05) #각 x값 정수배열마다의 y값
# 50cm 농어 데이터
plt.scatter([50], [1574], marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()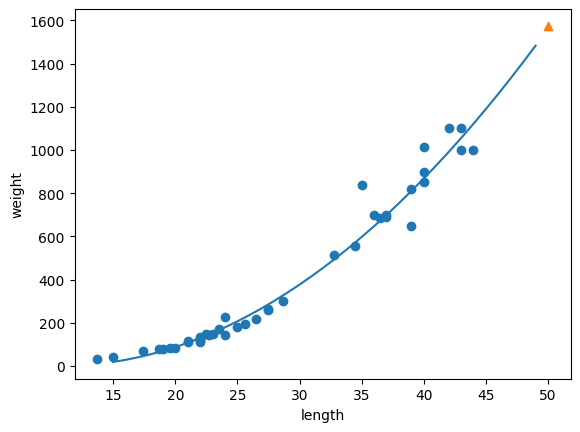

for well-being we need nectar and ambrosia