colab link
Logistic Regression
1. 데이터 준비하기
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
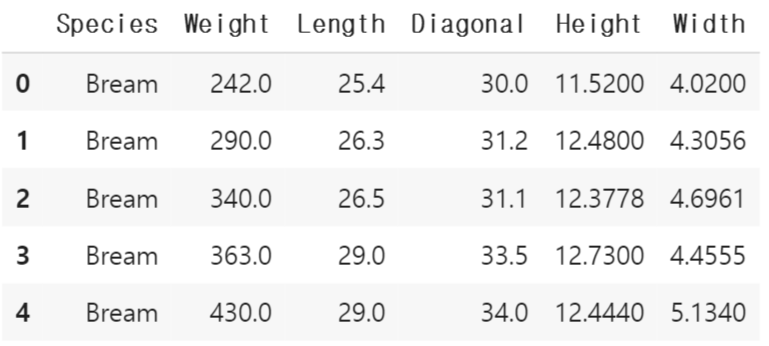
fish.head()fish_input = fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']].to_numpy()
#fish_input 리스트에 5개 특성에 대한 값을 numpy 배열로 저장
fish_target = fish['Species'].to_numpy()
#fish 데이터중 'Species'에 관한 데이터만 numpy 배열로 만들어 fish_target에 저장
# Bream, Bream ... Smelt, Smelt...- target 샘플과 test 샘플 준비
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target, random_state=42)
#랜덤 계수 42로 랜덤하게 fish_target(물고기 종)으로 fish_input 값을 train과 test로 나누기- 표준화 전처리
from sklearn.preprocessing import StandardScaler
#StandardScaler 클래스를 사용해 훈련세트&테스트 세트를 '표준화 전처리'
ss = StandardScaler()
ss.fit(train_input) #훈련세트의 통계값으로 훈련
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)2. k-최근접 이웃 분류기의 확률 예측
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=3) #이웃 3으로 k최근접이웃 훈련
kn.fit(train_scaled, train_target) #kn모델 훈련모델로 훈련
print(kn.score(train_scaled, train_target))
print(kn.score(test_scaled, test_target))- k-최근접 이웃 분류기 한계
3개의 최근접 이웃을 사용하기 때문에 가능한 확률은 4가지(0, 0.33, 0.66, 1). 다른 모델 필요
import numpy as np
proba = kn.predict_proba(test_scaled[:5]) #테스트 5개 샘플 예측 확률(각 클래스 별로)
print(np.round(proba, decimals=4)) #numpy의 함수를 이용해 소수점 네번째 자리까지 표기(decimals)
#['Bream' 확률, 'Parkki' 확률, 'Perch' 확률, 'Pike' 확률, 'Roach' 확률, 'Smelt' 확률, 'Whitefish' 확률]3. 로지스틱 회귀
- 로지스틱 회귀
회귀이지만 분류 모델. 시그모이드 함수로 확률 계산
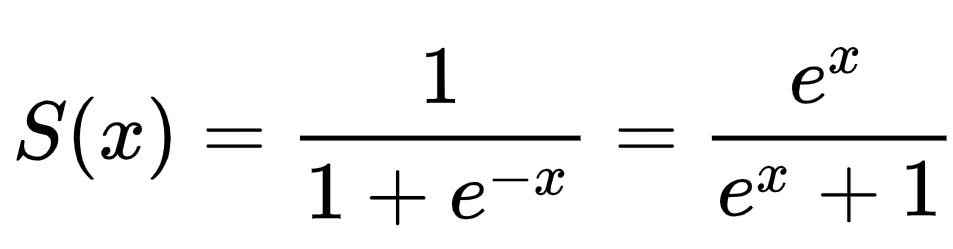
import numpy as np
import matplotlib.pyplot as plt
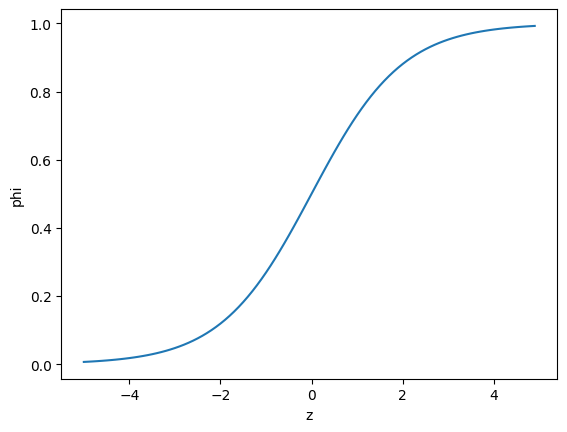
z = np.arange(-5, 5, 0.1)
phi = 1/(1+np.exp(-z)) #z에 대해 phi 정의(시그모이드 함수)
plt.plot(z, phi)
plt.xlabel('z')
plt.ylabel('phi')
plt.show()
#아래 그래프는 예시(지금 다중클래스 샘플과 관련 없음)1) 로지스틱 회귀로 이진 분류 수행하기
- 불리언 인덱싱으로 데이터 준비
bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
#Bream or Smelt일 경우 True로 인덱싱
train_bream_smelt = train_scaled[bream_smelt_indexes] #불리언 인덱싱으로 사용해 Bream과 Smelt만을 분류
target_bream_smelt = train_target[bream_smelt_indexes]
#각각 bream이랑 smelt만 있는 train이랑 target 샘플- lr 모델 훈련
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt) #bream이랑 Smelt만이 있는 train, test 샘플들로 훈련
print(lr.predict(train_bream_smelt[:5])) #5개 샘플의 샘플 종 예측(Bream. Smelt 중 하나)
print(lr.predict_proba(train_bream_smelt[:5])) #5개 샘플 예측 확률 출력- 시그모이드 함수를 이용한 확률 계산
decisions = lr.decision_function(train_bream_smelt[:5])
print(decisions) #lr모델의 z값 출력
from scipy.special import expit #expit = 시그모이드 함수
print(expit(decisions)) #시그모이드 함수에 대입하면 phi 계산가능
#출력된 phi값이 위에서 구한 predict_prob와 같다는 것을 알 수 있음2) 로지스틱 회귀로 다중 분류 수행하기
- lr 모델 훈련
lr = LogisticRegression(C=20, max_iter=1000)
lr.fit(train_scaled, train_target) #2개의 종만이 아닌 전체 클래스로 훈련
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
#훈련 score와 테스트 score 크게 차이 안남
proba = lr.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=3)) #5개 샘플 예측한 확률 출력하기 (소수점 3째자리까지)- softmax 함수를 이용한 확률 계산
decision = lr.decision_function(test_scaled[:5])
print(np.round(decision, decimals=2)) #5개 샘플의 z값 소수 2째자리 까지 출력
from scipy.special import softmax #다중분류는 시그모이드 함수가 아닌 소프트맥스 함수 이용
proba = softmax(decision, axis=1)
print(np.round(proba, decimals=3)) #softmax 함수에 z 대입해서 phi(확률) 출력
for well-being we need nectar and ambrosia
훌륭한 글 감사드립니다.