colab link
cross validation & GridSearch
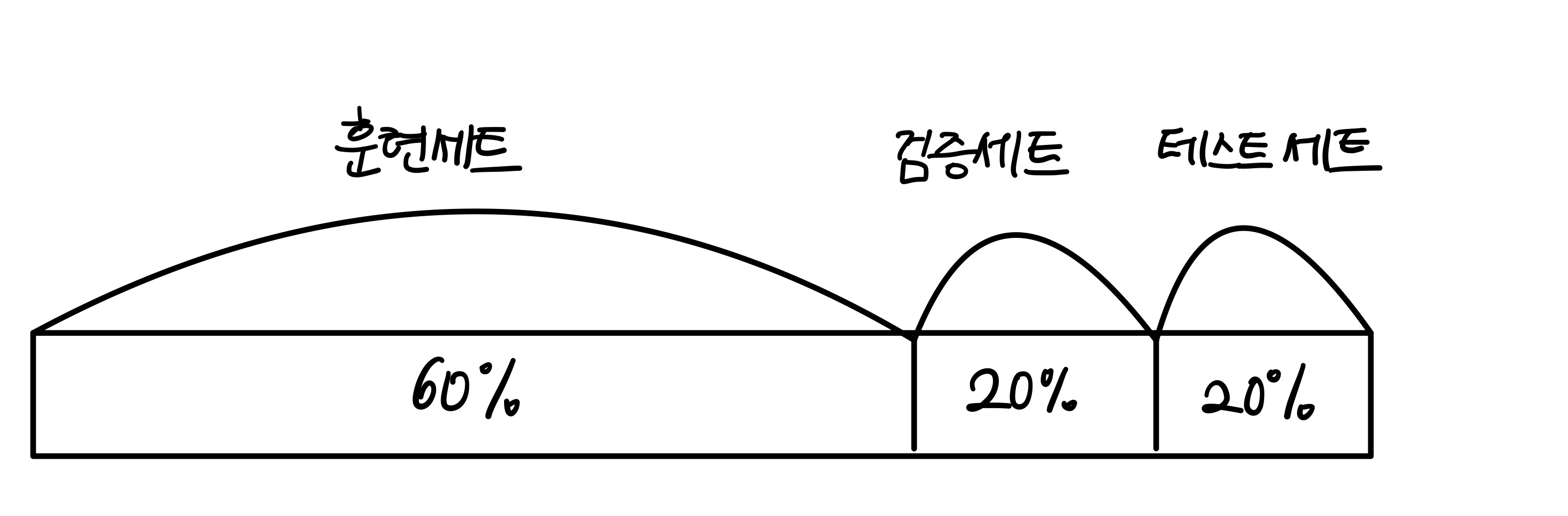
1. 검증 세트
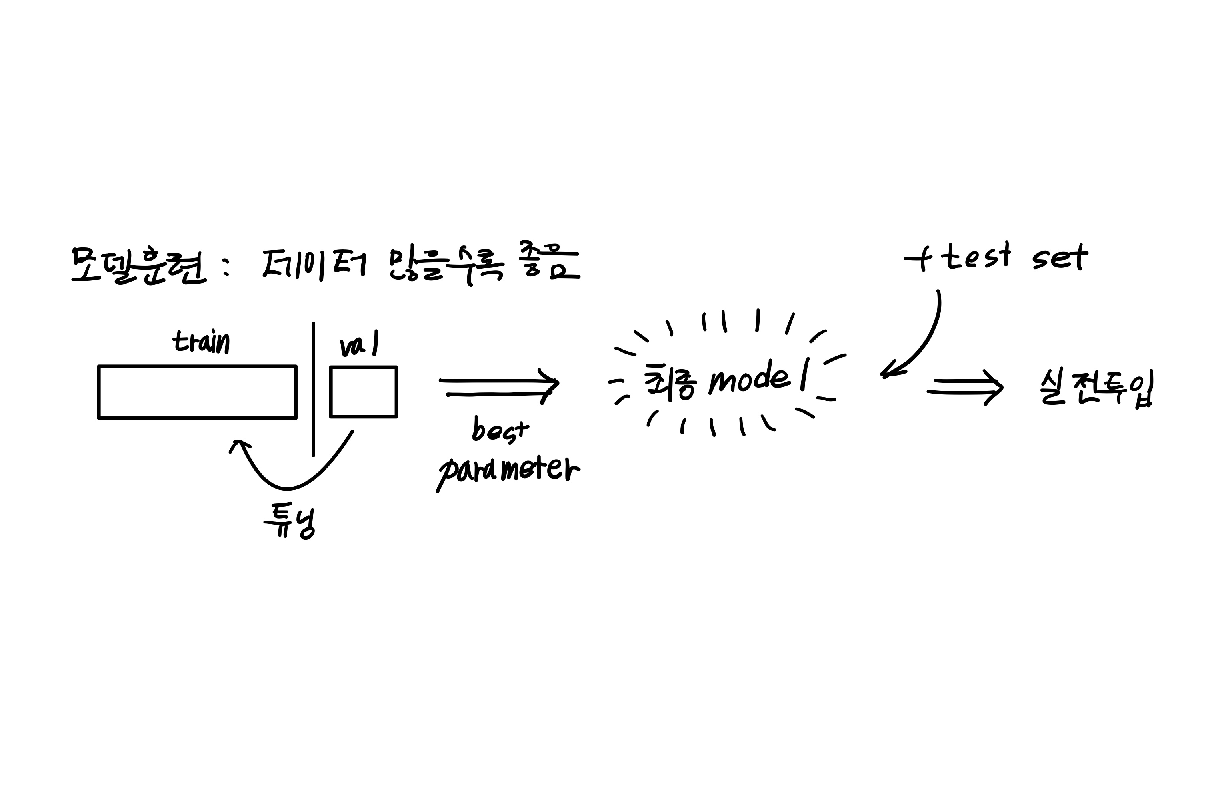
테스트 세트로 일반화 성능을 올바르게 예측하려면 가능한 한 테스트 세트를 사용하지 말아야 한다.
훈련세트를 나눠 검증세트를 만든다. 훈련세트를 통해 모델을 만들고 검증세트를 통해 확인하며 테스트 세트는 실전투입 전 마지막에 사용한다
- 검증 세트 만들기
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
sub_input, val_input, sub_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42)train_input과 train_target을 다시 함수에 넣어 훈련 세트 sub와 검증 세트 val을 만든다. (즉 훈련세트로부터 또 검증 세트와 훈련 세트로 나누는 것)
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(sub_input, sub_target)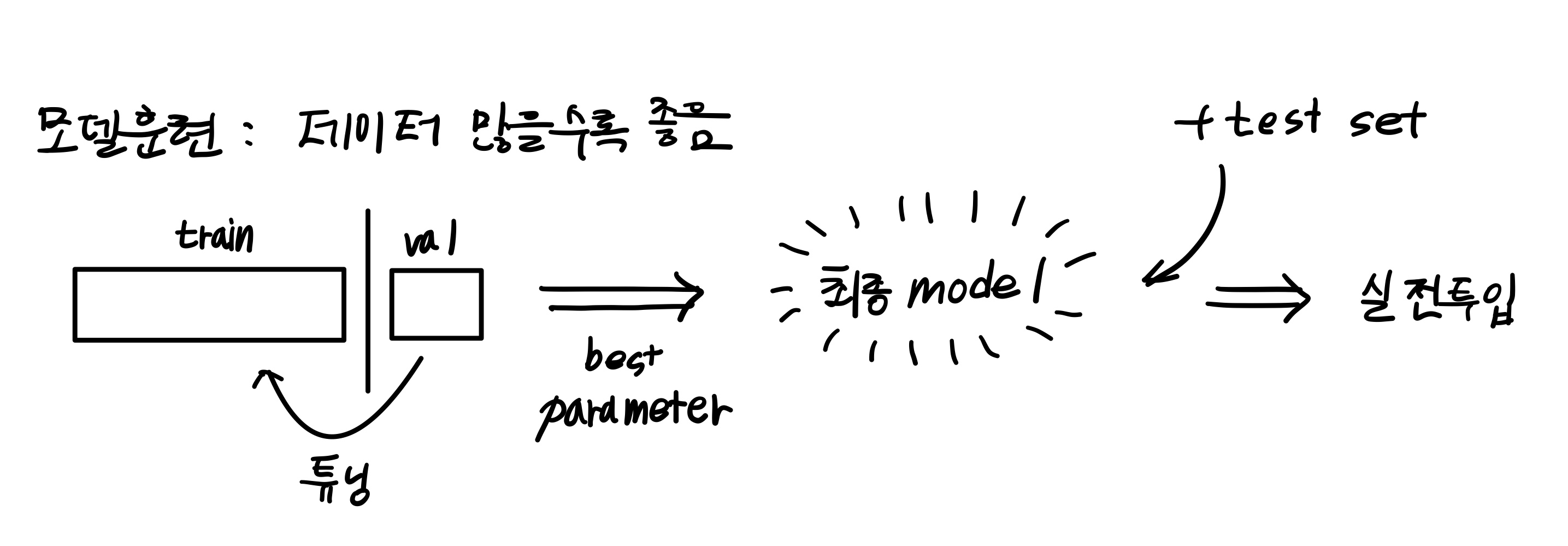
2. 교차 검증
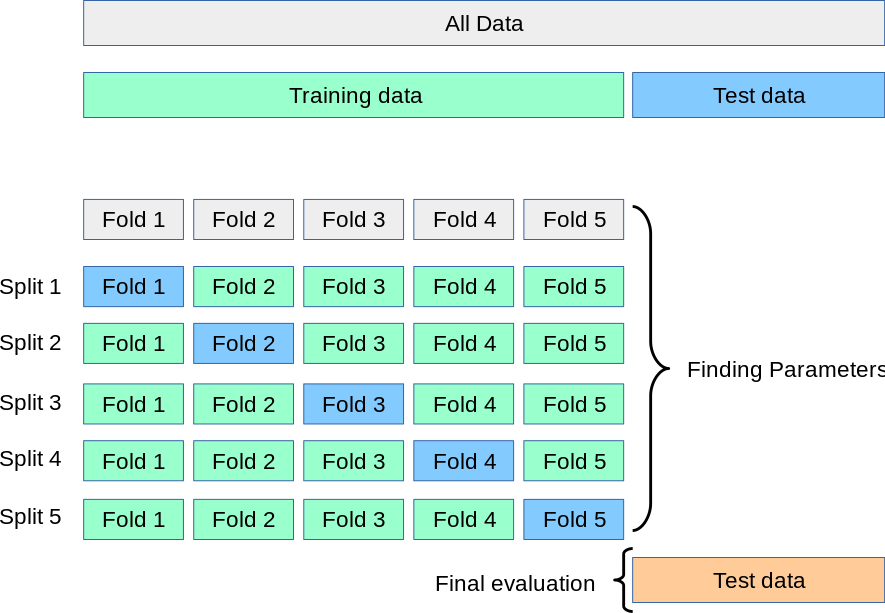
검증 세트를 조금씩 훈련세트에서 떼어 놓고 훈련할 경우 검증 점수가 들쭉 날쭉하고 불안정할 것. 이럴 때 교차 검증을 사용해 안정적인 검증 점수를 얻는다.
교차 검증은 검증 세트를 떼어 내어 평가하는 과정을 여러번 반복한다. 이때 각 훈련 시행을 폴드라 지칭한다.
cross_validate()
cross_validate() 교차 검증 함수는 직접 검증 세트를 떼어내지 않고 훈련 세트 전체를 cross_validate()함수에 전달한다.
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)cross_validate()는 훈련 세트를 섞어 폴드를 나누지 않는다. 훈련세트를 섞으려면 분할기를 지정해야 한다.
StratifiedKFold
타깃 클래스를 골고루 나누기 위해StratifiedKFold를 사용한다.
from sklearn.model_selection import StratifiedKFold
scores = cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
print(np.mean(scores['test_score']))3. 하이퍼파라미터 튜닝
사용자가 지정해야 하는 파라미터를 하이퍼 파라미터라고 한다
- 하이퍼 파라미터를 튜닝하는 작업
max_depth를 찾고 min_samples_split을 찾는 순차적인 과정으로 최적값을 찾을 수 없다. (서로 상호관계를 가지기 때문이다.) 두 매개변수를 동시에 바꿔가며 최적의 값을 찾아야 한다.
- 그리드 서치
GridSearchCV 클래스는 하이퍼파라미터 탐색과 교차검증을 한번에 수행한다
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease':[0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}min_impurity_decrease는 정보이득 차이값으로 불순도가 클수록 좋음을 의미한다. 이때 정보이득 차이가 0.0001이 안되면 나누지 않는다.
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target) #앞서 검증세트를 나눌때 test 세트 떨군 train 세트그리드 서치 객체는 결정트리모델의 min_impurity_decrease값을 바꿔가며 총 5번 수행하고 각각 5-폴드 교차검증을 수행하므로(매개변수 기본값) 총 25개의 모델을 수행한다.
교차 검증에서 최적의 하이퍼파라미터를 찾으면 전체 훈련 세트로 모델을 다시만들어야 하지만 그리드 서치는 25개의 모델 중 검증 점수가 가장 높은 모델의 매개변수 조합으로 전체 훈련 세트에서 자동으로 다시 모델을 훈련한다
이 모델은 gs 객체의 best_estimator_속성에 저장되어 있다.
📕 과정 정리
1. 먼저 탐색할 매개변수를 지정
2. 훈련세트에서 그리드 서치를 수행해 최상의 평균 검증 점수가 나오는 매개변수 조합을 찾는다. 이 조합은 그리드 서치 객체에 저장된다.
3. 그리드 서치는 최상의 매개변수에서 (교차 검증에서 사용한 훈련세트가 아닌) 전체 훈련세트를 사용해 최종 모델을 훈련한다.
- 복잡한 매개변수 조합 설정하기
params = {'min_impurity_decrease':np.arange(0.0001, 0.001, 0.0001),
'max_depth': range(5, 20, 1),
'min_samples_split':range(2, 100, 10)
}하지만 이렇게 간격을 둔 것에 특별한 근거가 없고 더 좁거나 넓은 간격으로 시도해야될 필요도 있다. 따라서 랜덤 서치가 필요하다.
4. 랜덤 서치
랜덤 서치에는 매개변수를 샘플링할 수 있는 확률 분포 객체를 전달한다.
np.unique(rgen.rvs(1000), return_counts = True) #0~10까지 1000개의 샘플링샘플링 횟수는 n_iter매개변수에 지정한다.
params = {'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25),
}
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params, n_iter=100, n_jobs=-1, random_state=42)
gs.fit(train_input, train_target)즉 총 100번을 샘플링하여 교차검증을 수행하고 최적의 매개변수 조합을 찾는다.
다시 한번 말하지만 최적의 모델은 이미 전체 훈련 세트(train-input, train-target)로 훈련되어 best_estimator_ 속성에 저장되어 있다.
