colab link
artifical neural network
1. 패션 MNIST
딥러닝 라이브러리 중 하나인 텐서플로의 패션 MNIST 데이터셋을 사용해 10종류의 패션 아이템을 분류하는 문제
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()- MNIST 데이터셋
훈련데이터는 28x28 크기의 이미지 60,000개로 구성된 데이터
타깃은 60,000개의 원소가 있는 1차원 배열

(훈련데이터 샘플)target 10개 레이블
| 레이블 | 0 | 1 | 2 ... | 8 | 9 |
|---|---|---|---|---|---|
| 패션 아이템 | 티셔츠 | 바지 | 스웨터 ... | 가방 | 앵클 부츠 |
2. 로지스틱 회귀로 패션 아이템 분류하기
SGDClassifier(로지스틱 손실함수를 최소화하는 확률적 경사 하강법 모델)을 사용해 패션 아이템을 분류. SGDClassifier 모델은 패션 MNIST 데이터의 클래스를 가능한 잘 구분할 수 있도록 이 10개의 방정식에 대한 모델 파라미터(가중치와 절편)를 찾음
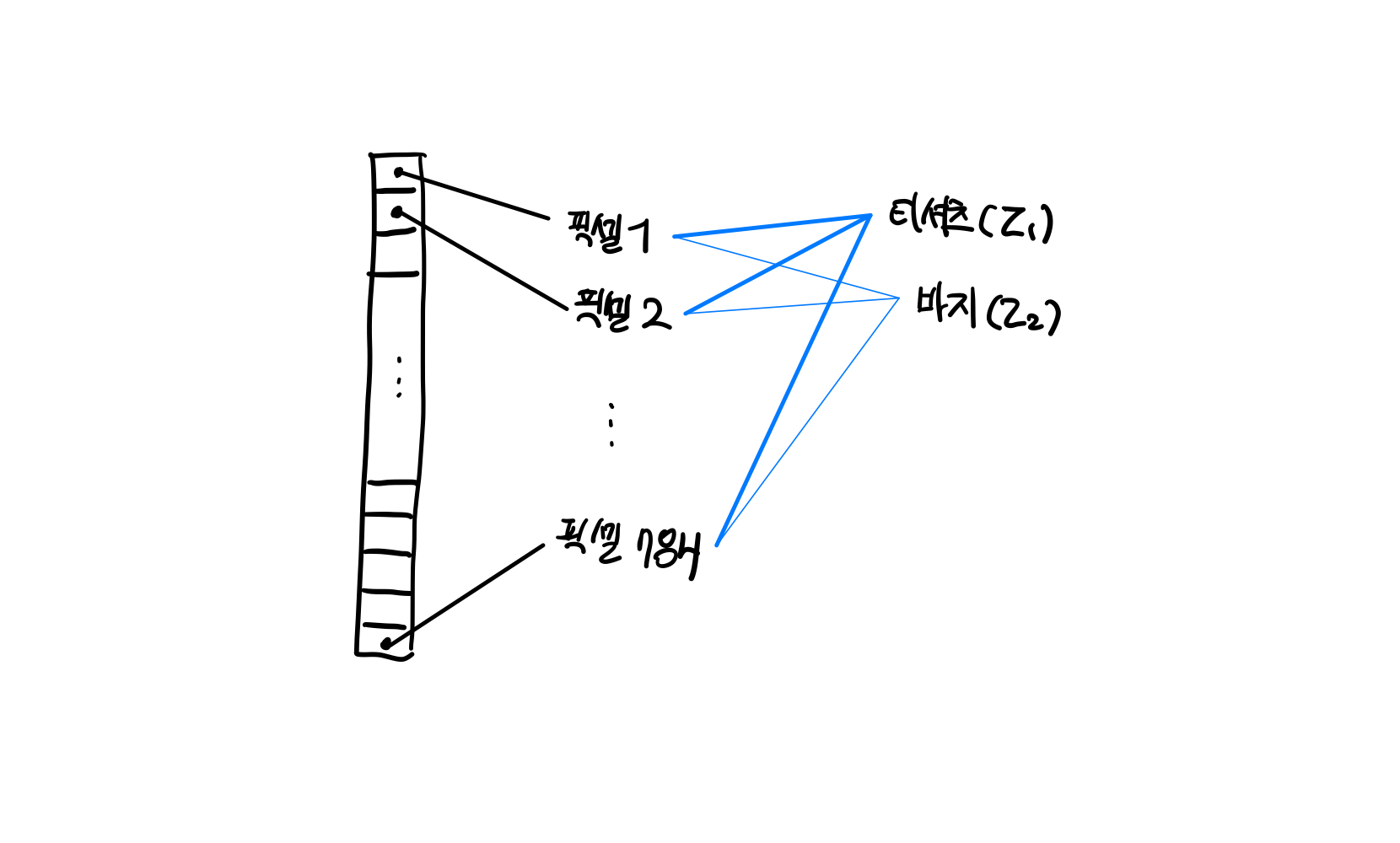
- SGDClassifier 입력을 위한 1차원 배열로의 변환
train_scaled = train_input / 255.0 #정규화
train_scaled = train_scaled.reshape(-1, 28*28) #1차원 배열로 축소- 교차검증으로 성능 확인
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log_loss', max_iter=5, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))3. 인공신경망
가장 기본적인 인공 신경망은 확률적 경사 하강법을 사용하는 로지스틱 회귀와 같다.
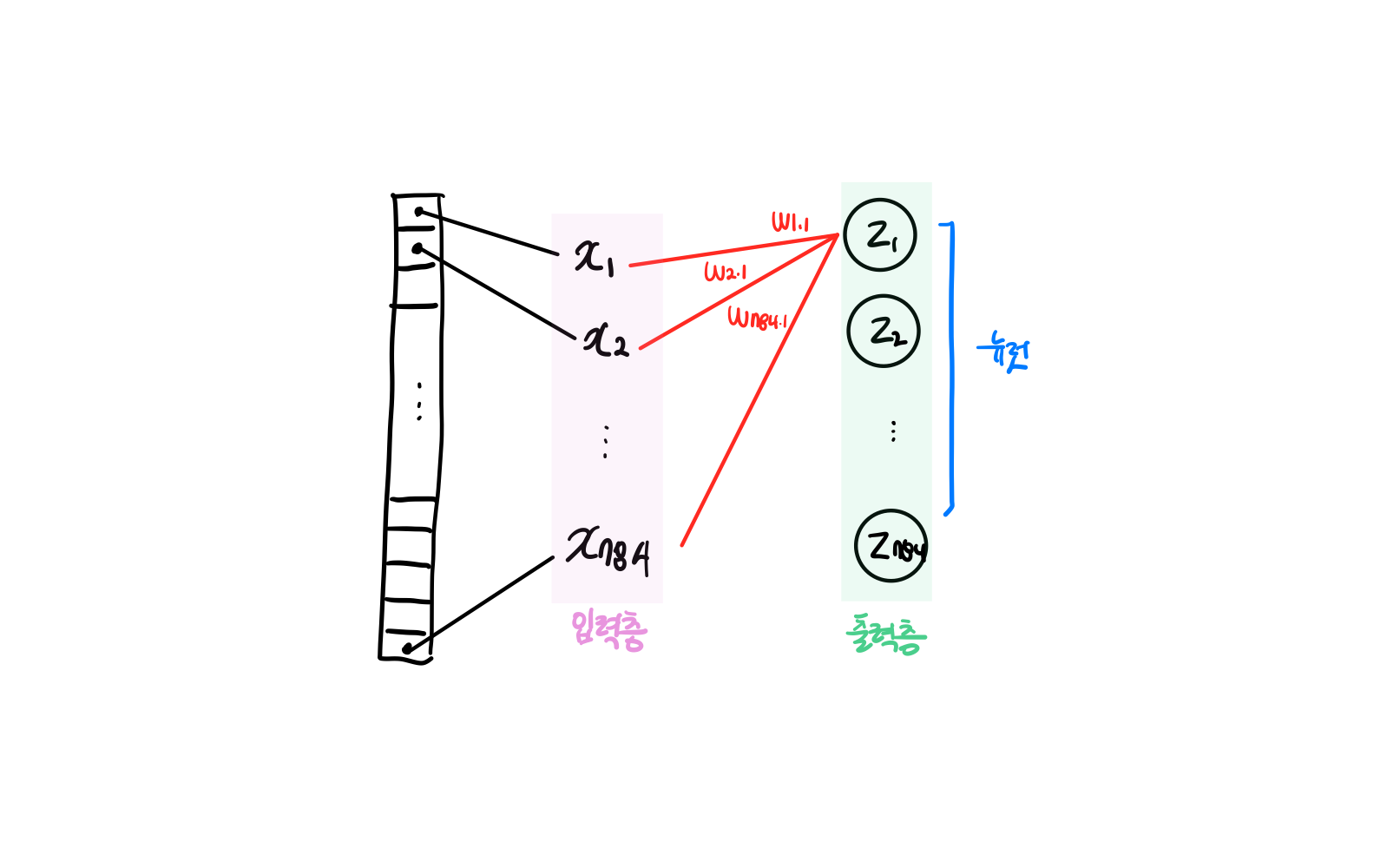
구성요소
출력층 (Output layer): 입력 데이터에 대한 예측 결과 생성. 문제 유형에 따라 구조 및 활성화 함수가 달라짐.
뉴런 (neuron 또는 unit): z 값을 계산하는 단위
입력층 (input layer) : 객체 취급하지만 따로 층으로 구별하지는 않음
pytorch와 tensorflow 이외의 딥러닝 라이브러리는 알 필요가 없음
(tensorflow와 케라스는 동일 취급)
4. 인공 신경망으로 모델 만들기
인공 신경망에서는 교차검증을 사용하지 않고(시간 비용이 많이 발생) 검증 세트를 별도로 덜어내어 사용함.
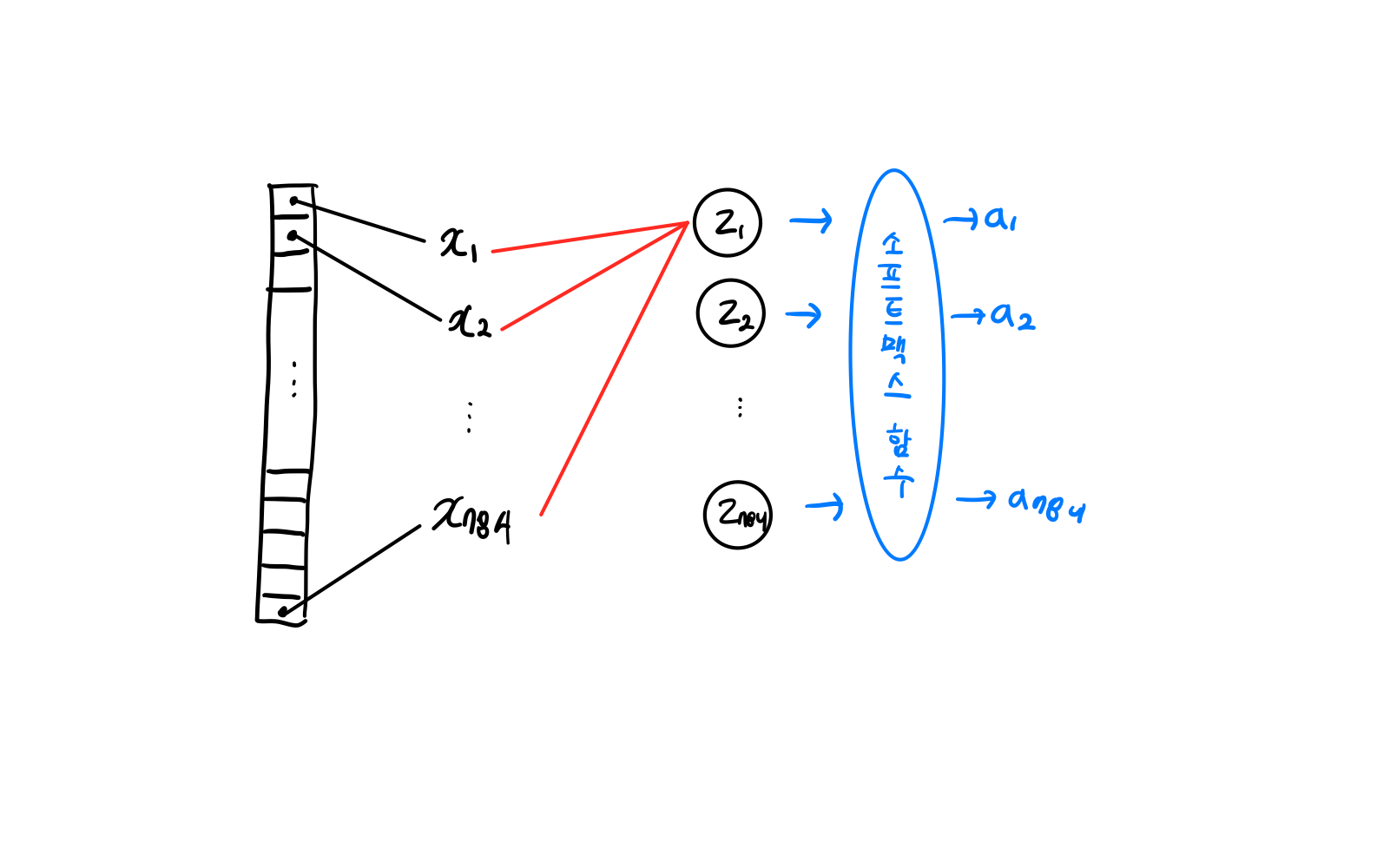
- 밀집층 (layer 정의 단계)
가장 기본이 되는 Layer
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))활성화 함수
뉴런에서 출력되는 값을 확률로 바꾸기 위해 activation에서 함수 설정 (만약 2개의 클래스를 분류하는 이진 분류라면 시그모이드 함수를 사용하기 위해 activation='sigmoid' 와 같이 설정)
- Sequential 클래스
위에서 정의한 밀집층을 가진 신경망 모델 생성
model=keras.Sequential(dense)5. 인공 신경망으로 패션 아이템 분류하기
- 모델 설정
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')(1) 손실 함수의 종류 설정
크로스 엔트로피 손실 함수
- 이진 분류:loss= 'binary_crossentropy'
- 다중 분류: loss= 'categorical_crossentropy'
이진분류에서는 출력층의 뉴런이 하나이다. 양성 클래스와 음성클래스에 대한 크로스 엔트로피를 계산하는데, 이진 분류의 출력 뉴런은 오직 양성클래스에 대한 확률(a)만 출력하기 때문에 음성 클래스에 대한 확률은 간단히 1-a로 구할 수 있다.
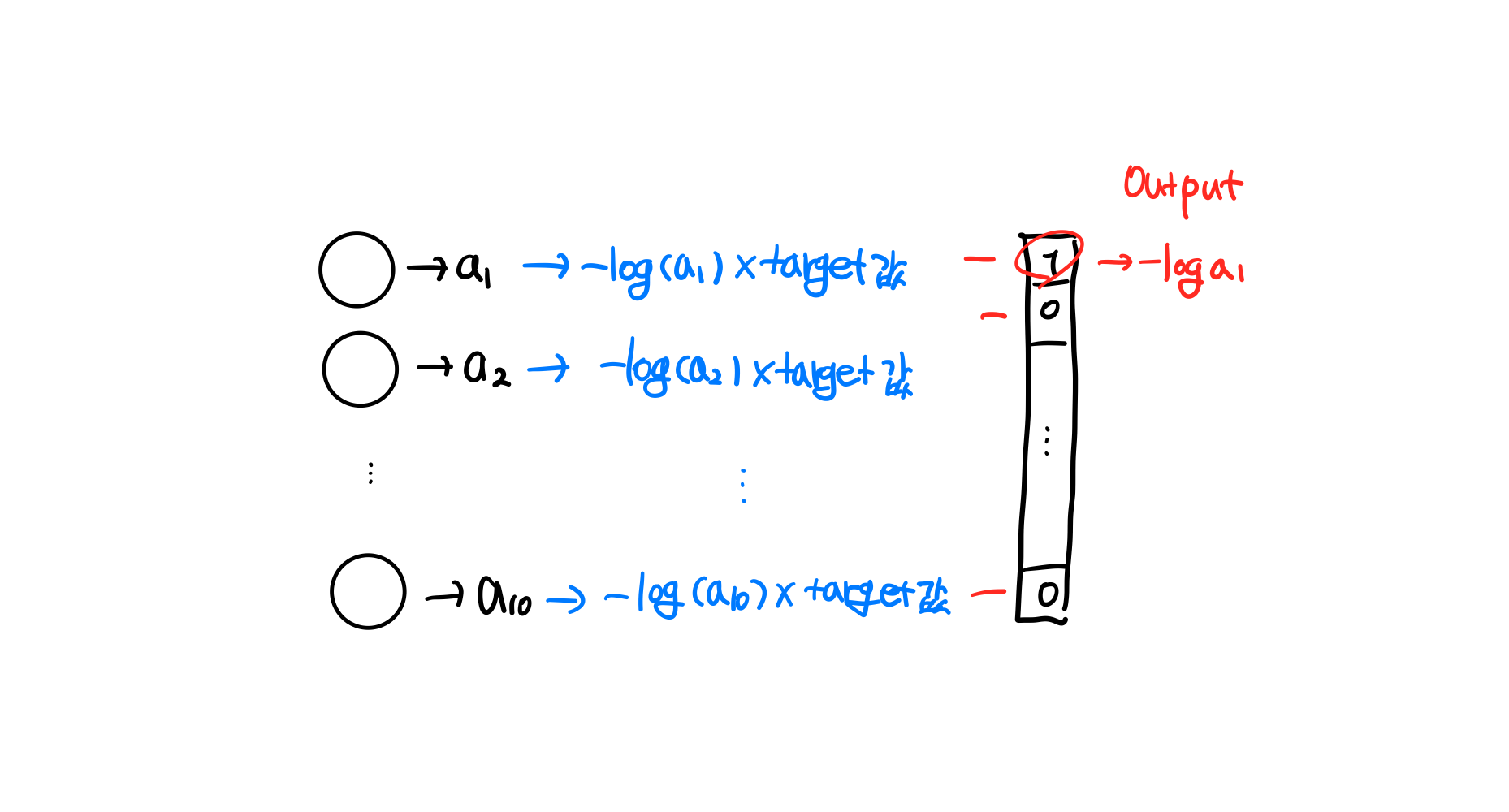
다중 분류일경우에는 타깃에 해당하는 확률만 남겨놓기 위해서 나머지 확률에는 모두 0을 곱한다. 따라서, 타깃값을 원-핫인코딩으로 변환한다.
sparse_categorical_crossentropy
텐서플로에서는 정수로 된 타깃값을 원-핫 인코딩으로 바꾸지 않고 사용하도록sparse_categorical_crossentropy지원
(2) metrics
사이킷런의 정확도와 유사한 기능으로 케라스는 모델이 훈련할 때 기본으로 에포크마다 손실값을 출력 해줌
*에포크 : 모델이 전체훈련 데이터셋 한번 모두 사용하여 학습을 완료한 주기
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')(3) fit - 모델 훈련
model.fit(train_scaled, train_target, epochs=5)[Output]
Epoch 1/5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.6075 - accuracy: 0.7930
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4744 - accuracy: 0.8395
Epoch 3/5
1500/1500 [==============================] - 6s 4ms/step - loss: 0.4488 - accuracy: 0.8485
Epoch 4/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.4360 - accuracy: 0.8525
Epoch 5/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.4286 - accuracy: 0.8553
<keras.src.callbacks.History at 0x7c5bc65c25c0>