colab link
Image Classification Using Convolutional Neural Networks.ipynb
1. 패션 MNIST 데이터 불러오기
- 합성곱 신경망은 2차원 이미지를 그대로 사용(1차원으로 펼칠 필요 없음)
- 깊이 차원이 존재해야 함 (채널 차원 추가
train_scaled = train_input.reshape(-1, 28, 28, 1) / 255.02. 합성곱 신경망 만들기
(1번째 합성곱 신경망층)
model = keras.Sequential()
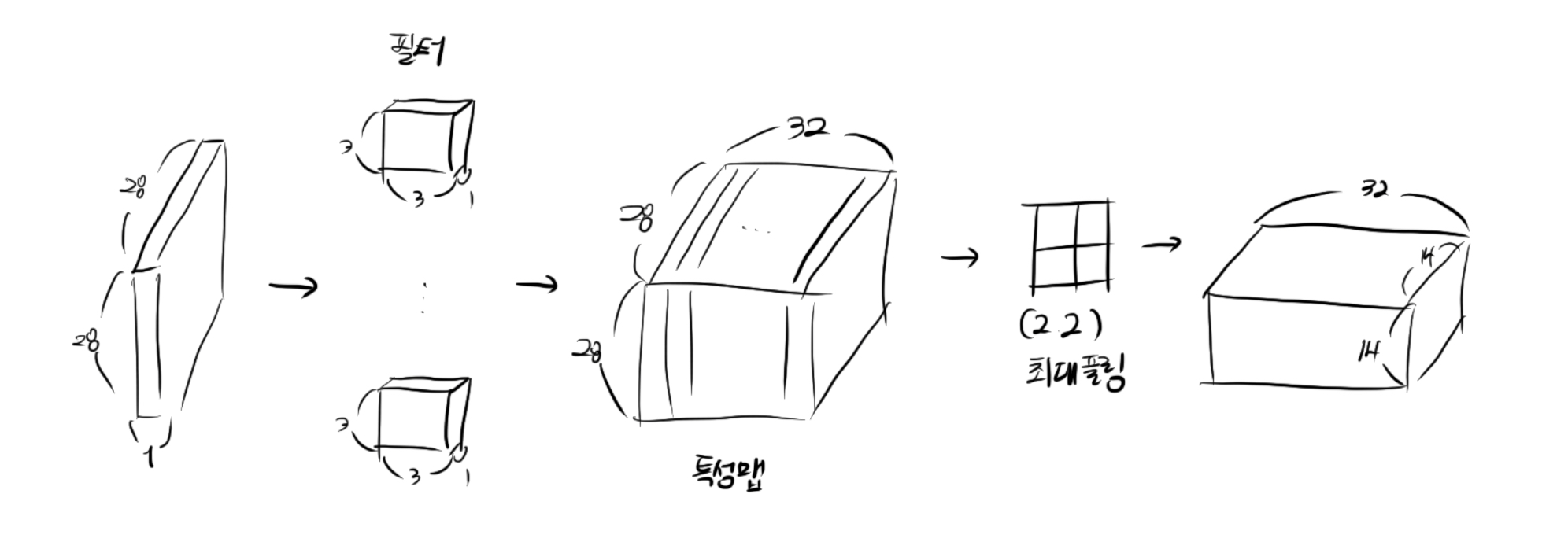
model.add(keras.layers.Conv2D(32, kernel_size=3, activation='relu', padding='same', input_shape = (28,28,1)))- 32개의 필터를 사용
- 커널의 크기는 (3,3)
- 렐루 활성화 함수와 세임 패딩을 사용(입력층과 크기 동일)
model.add(keras.layers.MaxPooling2D(2))- (2,2) 풀링을 적용하므로 특성맵의 크기는 절반으로 감소
2번째 합성곱층 & 완전 연결층
1번째 합성곱층과 마찬가지로 세임페딩을 사용하고, 풀링 층에서 이 크기를 절반으로 줄일 것임
따라서, 최종 특성 맵의 크기는 (7, 7, 64)
model.add(keras.layers.Conv2D(64, kernel_size=3, activation = 'relu', padding='same'))
model.add(keras.layers.MaxPooling2D(2))완전 연결층
3차원 특성 맵을 일렬로 펼쳐야됨(마지막 10개의 뉴런(출력층)이 확률을 계산하도록)
- 과대적합 방지를 위한 드롭아웃
- 은닉층의 활성화 함수는 렐루함수를 사용, 출력층의 활성화 함수는 소프트 맥스를 사용
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(10, activation='softmax'))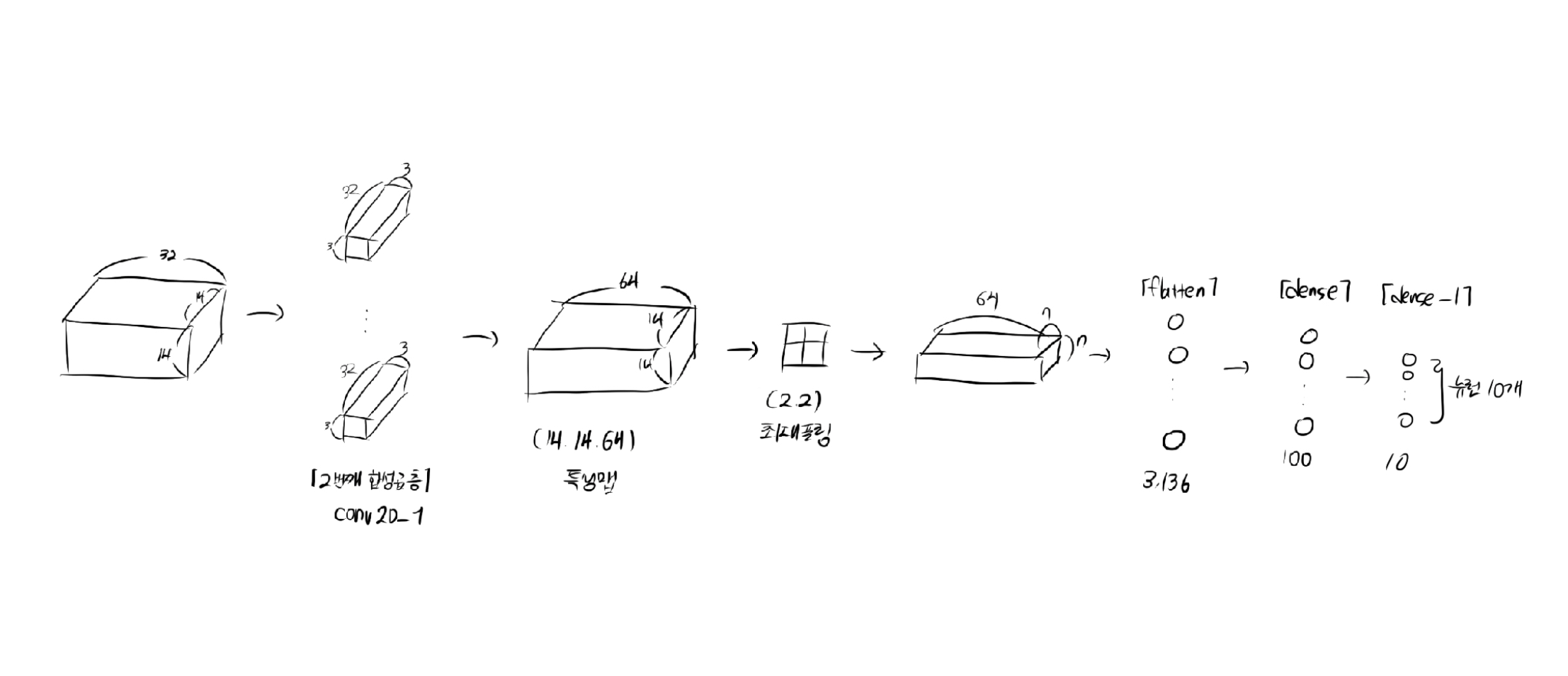
<br/ >
[참고] 모델 구조 설명
(1)summary()Model: "sequential" ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩ │ conv2d (Conv2D) │ (None, 28, 28, 32) │ 320 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ max_pooling2d (MaxPooling2D) │ (None, 14, 14, 32) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ max_pooling2d_1 (MaxPooling2D) │ (None, 7, 7, 32) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ conv2d_1 (Conv2D) │ (None, 7, 7, 64) │ 18,496 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ max_pooling2d_2 (MaxPooling2D) │ (None, 3, 3, 64) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ flatten (Flatten) │ (None, 576) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dense (Dense) │ (None, 100) │ 57,700 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dropout (Dropout) │ (None, 100) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dense_1 (Dense) │ (None, 10) │ 1,010 │ └──────────────────────────────────────┴─────────────────────────────┴─────────────────┘ Total params: 77,526 (302.84 KB) Trainable params: 77,526 (302.84 KB) Non-trainable params: 0 (0.00 B)(2)
plot_model()
3. 모델 컴파일과 훈련
딥러닝 모델의 종류나 구성방식에 상관없이 컴파일과 훈련 과정이 항상 동일하다
model.compile(optimizer='adam', loss= 'sparse_categorical_crossentropy', metrics = ['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-cnn-model.h5.keras', save_best_only= True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_weights= True)
history = model.fit(train_scaled, train_target, epochs=20, validation_data=(val_scaled, val_target),
callbacks = [checkpoint_cb, early_stopping_cb])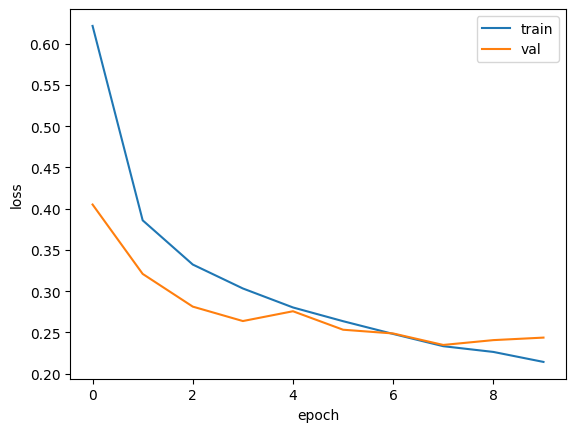
8번째 에포크가 최적, 10번째에서 조기중단함을 확인할 수 있음.
- 10개 클래스에 대한 예측 확률 출력하기
preds = model.predict(val_scaled[0:1]) #슬라이싱
print(preds)[Output]
[[7.1790615e-11 1.9371986e-16 3.0953423e-14 7.3020035e-13 3.2941784e-13
2.9614533e-11 1.7263002e-11 4.9220489e-12 1.0000000e+00 8.7399997e-14]]9번째 클래스에 해당(1)하고 나머지 클래스에 대한 확률은 0이나 다름없음
- 합성곱 신경망의 일반화 성능 (*예상 성능)
test_scaled = test_input.reshape(-1, 28, 28, 1) / 255.0
model.evaluate(test_scaled, test_target)accuracy는 0.9116으로, 모델을 실전에 투입하여 분류한다면 91%의 성능을 기대해볼 수 있을 것

for well-being we need nectar and ambrosia