
00. NLP와 텍스트 분석
NLP는 머신이 인간의 언어를 이해하고 해석하는 데 더 중점을 두고 기술이 발전해 왔으며, 텍스트 마이닝이라고도 불리는 텍스트 분석은 비정형 텍스트에서 의미 있는 정보를 추출에 중점 맞춤
NLP는 텍스트 분석을 향상하게 하는 기반 기술
- 텍스트 분류
문서가 특정 뷴류 또는 카테고리에 소가는 것을 예측하는 기법을 통칭- 감성 분석
텍스트에서 나타나는 감정/판단/믿음/의견/기분 등의 주관적인 요소를 분석하는 기법을 통칭- 텍스트 요약
텍스트 내에서 중요한 주제나 중심 사상을 추출 (토픽 모델링)- 텍스트 군집화
비슷한 유형의 문서에 대해 균집화를 수행하는 기법 (유사도 측정)
01. 텍스트 분석 이해
- NLP vs 텍스트 분석
NLP : 머신이 인간의 언어를 이해하기 해석하는 데 더 중점을 둠
텍스트 분석 : 비정형 텍스트에서 의미있는 정보를 추출하는 것에 더 중점을 둠
- 피처 벡터화
텍스트를 다수의 피처로 추출하고 이 피처에 단어 빈도수와 같은 가중치를 부여해 텍스트를 단어의 조합인 벡터의 값으로 표현
(예) BoW, Word2Vec, GloVe, FastText
텍스트 분석 프로세스
(1) 텍스트 전처리
(2) 피처 벡터화
(3) ML 모델 수립 및 학습/예측/평가
02. 텍스트 전처리 - 텍스트 정규화
텍스트를 머신러닝 알고리즘이나 NLP 어플리케이션에 입력데이터로 사용하기 위해 클렌징, 정제, 토큰화, 어근화 등의 다양한 텍스트 데이터의 사전작업을 수행하는 것
클렌징, 토큰화, 필터링/ 스톱워드 제거/ 철자 수행, Stemming, Lemmatization텍스트 토큰화 - 문장 토큰화
문장의 마침표, 개행 문자 등 문자의 마지막을 뜻하는 기호에 따라 분리
NTLK의 sent_tokenize를 이용
from nltk import sent_tokenize
import nltk
# 마침표, 개행문자(\n) 등의 데이터 셋: 최초 한번만 다운
# nltk.download('punkt')
text_sample = 'The Matrix is everywhere its all around us, here even in this room. \
You can see it out your window or on your television. \
You feel it when you go to work, or go to church or pay your taxes.'
sentences = sent_tokenize(text = text_sample)
print(type(sentences),len(sentences))
print(sentences)class 'list'> 3
['The Matrix is everywhere its all around us, here even in this room.', 'You can see it out your window or on your television.', 'You feel it when you go to work, or go to church or pay your taxes.']텍스트 토큰화 - 단어 토큰화
공백, 콤마, 마침표, 개행문자 등으로 단어 부닐
단어의 순서가 중요하지 않은 경우 문장 토큰화를 사용하지 않고 단어 토큰화만 사용해도 충분
NTLK의 work_tokenize 이용
from nltk import word_tokenize
sentence = "The Matrix is everywhere its all around us, here even in this room."
words = word_tokenize(sentence)
print(type(words), len(words))
print(words)<class 'list'> 15
['The', 'Matrix', 'is', 'everywhere', 'its', 'all', 'around', 'us', ',', 'here', 'even', 'in', 'this', 'room', '.']► sent_tokenize()와 word_tokenize() 이용해 문장의 모든 단어 토큰화
텍스트 토큰화 - 정규표현식
- 정규표현식
정규표현식 모델 re
특정 규칙이 있는 텍스트 데이터를 빠르게 정제할 수 있음
from nltk.tokenize import RegexpTokenizer
text = "Don't be fooled by the dark sounding name, Mr.Jone's Orphanage is a cheery as cheery goes for a pastry shop"
tokenizer1 = RegexpTokenizer("[\w]+")
tokenizer2 = RegexpTokenizer("\s+", gaps = True)
print(tokenizer1.tokenize(text))
print(tokenizer2.tokenize(text))['Don', 't', 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', 'Mr', 'Jone', 's', 'Orphange', 'is', 'as', 'cheery', 'as', 'cheert', 'goes', 'for', 'a', 'pastry', 'shop']
["Don't", 'be', 'by', 'the', 'dark'. 'sounding'. 'name'. 'Mr.', "Jone's", 'Orphanage', 'is', 'as', 'cherry', 'as', 'cherry', 'goes', 'for', 'a', 'pastry', 'shop']스톱워드 제거
- stopword
분석에 큰 의미가 없는 단어 (is, will, a, the 등)
문법적인 특성으로 인해 빈번하게 텍스트에 나타나므로 사전에 제거하지 않으면 빈번함 때문에 오히려 중요한 단어로 인지될 수 있음
NTLK에 언어별로 스톱워드가 목록화되어 있음
# 영어 stopword
stopwords = nltk.corpus.stopwords.words('english')
# 문장별 단어 토큰화 + stopword 제거
all_tokens = []
for sentence in word_tokens:
filtered_words=[]
# 문장 토큰의 각 단어 토큰
for word in sentence:
# 소문자 변환
word = word.lower()
# stopword 미포함
if word not in stopwords:
filtered_words.append(word)
all_tokens.append(filtered_words)
print(all_tokens)[['matrix', 'everywhere', 'around', 'us', ',', 'even', 'room', '.'], ['see', 'window', 'television', '.'], ['feel', 'go', 'work', ',', 'go', 'church', 'pay', 'taxes', '.']]Stemming & Lemmatization
문법적 또는 의미적으로 변화하는 단어의 원형을 찾는 것
- Stemming
단순화된 방법을 사용하여 원형 단어에서 일부 처자가 훼손돈 어근 단어를 추출하는 경향이 있음
NTLK의 Porter, Lancaster, Snowball Stemmer
from nltk.stem import LancasterStemmer
stemmer = LancasterStemmer()
print(stemmer.stem('working'),stemmer.stem('works'),stemmer.stem('worked'))
print(stemmer.stem('amusing'),stemmer.stem('amuses'),stemmer.stem('amused'))
print(stemmer.stem('happier'),stemmer.stem('happiest'))
print(stemmer.stem('fancier'),stemmer.stem('fanciest'))work work work
amus amus amus
happy happiest
fant fanciest- Lemmatization
문법적 요소와 의미적인 부분을 감안하여 정확한 철자의 어근를 추출
단어의 품사를 입력해줘야 함
NTLK의 WordNetLemmatizer
Stemming 보다 정교하며 의미론적 기반에서 단어의 원형을 찾음
from nltk.stem import WordNetLemmatizer
# nltk.download('wordnet')
lemma = WordNetLemmatizer()
# 동사: v, 형용사: a
print(lemma.lemmatize('amusing','v'),lemma.lemmatize('amuses','v'),lemma.lemmatize('amused','v'))
print(lemma.lemmatize('happier','a'),lemma.lemmatize('happiest','a'))
print(lemma.lemmatize('fancier','a'),lemma.lemmatize('fanciest','a'))amuse amuse amuse
happy happy
fancy fancy한국어 전처리
- PykoSpacing
띄어쓰기가 되어 있지 않은 문장을 띄어쓰기한 문장으로 변환- Py-Hanspell
네이버 한글 맞춤법 검사기를 바탕으로 만든 맞춤법 보정 패키지, 띄어쓰기 또한 보정- SOYNLP
품사 태킹, 단어 토큰화 등의 지원
비지도 학습으로 단어 토큰화, 데이터에 자주 등장하는 단어들을 단어로 분석- Customized KoNLPy
형태소 분석기 Twitter 사용
add_dictionary('단어', '품사')의 형식으로 사용자 사전 추가 가능
03. BoW (Bag of Words)
- BoW
문서가 가지는 단어를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도 값을 부여해 피처 값 추출
- BoW 피처 벡터화
모든 문서에서 모든 단어를 칼럼 형태로 나열
각 문서에서 해당 단어의 횟수나 정규화된 빈도를 값으로 부여하는 데이터 세트 모델로 변경하는 것
- 카운트 벡터화
단어 피처에 값을 부여할 때 각 문서에서 해당 단어가 나타나는 횟수, Count를 부여하는 경우
Count 값이 높을 수록 중요한 단어로 인식 가중치 부여
언어의 특성상 문장에서 자주 사용될 수 밖에 없는 단어까지 높은 값을 부여하게 됨
TF-IDF 벡터화 (Term Frequency - Inverse Document Frequency)
개별 문서에서 자주 나타나는 단어에 높은 가중치를 주되, 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는 패널티를 주는 방식으로 값을 부여함.
문서마다 텍스트가 길고 문서의 개수가 많은 경우 카운트 방식보다는 TF-IDF 방식을 사용하는 것이 더 좋은 예측 성능을 보장할 수 있음
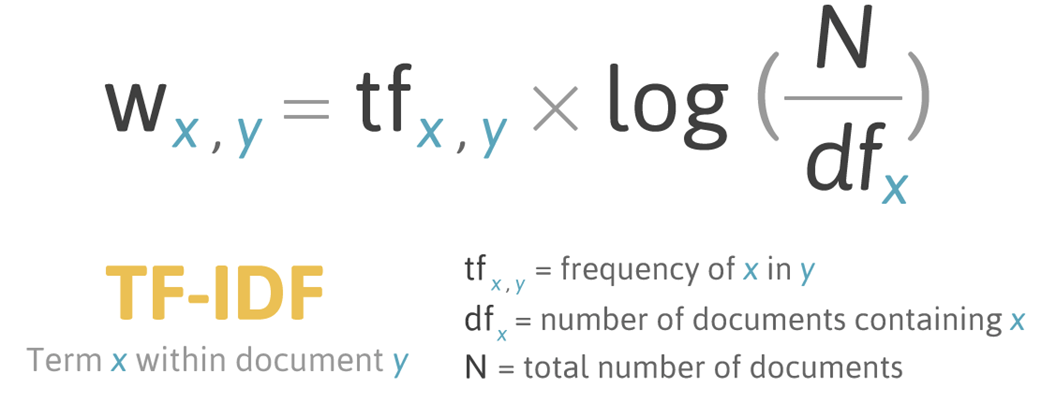
BoW 벡터화를 위한 희소행렬
대규모 행렬의 대부분 값을 차지하는 행렬
BoW 형태를 가진 언어 모델의 피처 벡터화는 대부분 희소 행렬
불필요한 0 값이 메모리에 할당되어 공간이 많이 필요하며, 연산 시에도 시간이 많이 소모
- COO 형식
0이 아닌 데이터만 별도의 데이터 배열 저장하고, 그 데이터의 행과 열의 위치를 별도의 배열로 저장 - CSR
COO 형식이 행, 열의 위치를 나타낸기 위해 반복적인 위치 데이터를 사용해야 하는 문제점을 해결한 방식
04.텍스트 분류 실습 - 20 뉴스그룹 분류
텍스트 분류 특정 문서의 분류를 학습 데이터를 통해 학습해 모델을 생성한 뒤, 해당 모델을 이용해 다른 문서의 분류를 예측하는 것
텍스트를 피처 벡터화로 변환 시 일반적으로 희소 행렬 형태가 됨
- 희소 행렬 처리 알고리즘
로직스틱 회귀, 선형 서포트 벡터 머신, 나이브 베이즈 등
텍스트 정규화
from sklearn.datasets import fetch_20newsgroups
news_data = fetch_20newsgroups(subset='all',random_state=156)
#fetch_20newsgroups()를 이용해 데이터를 로컬 컴퓨터로 내려받고 불러온다.
news_data.keys()
dict_keys(['data', 'filenames', 'target_names', 'target', 'DESCR'])
print("target 클래스의 값과 분포도")
print(pd.Series(news_data.target).value_counts().sort_index())# train set, 내용 외 정보 제거
train_news= fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'), random_state=156)
X_train = train_news.data
y_train = train_news.target
print(type(X_train))
# test set, 내용 외 정보 제거
test_news= fetch_20newsgroups(subset='test',remove=('headers', 'footers','quotes'),random_state=156)
X_test = test_news.data
y_test = test_news.target
print(f'학습 데이터 크기 {len(train_news.data)} , 테스트 데이터 크기 {len(test_news.data)}')
피처 벡터화 변환과 ML 모델 학습/예측/평가
- Count 기반 피처 벡터화
from sklearn.feature_extraction.text import CountVectorizer
# Count Vectorization: train
cnt_vect = CountVectorizer()
cnt_vect.fit(X_train)
X_train_cnt_vect = cnt_vect.transform(X_train)
# Count Vectorization: test
X_test_cnt_vect = cnt_vect.transform(X_test)
print(f"학습 데이터 Text의 CountVectorizer Shape: {X_train_cnt_vect.shape}")
테스트 데이터에서 CountVectorizer 적용 시 반드시 학습 데이터를 이용해 fit()이 수행된 CountVecotrizer 객체를 이용해 데이터를 변환해야 함
테스트 데이터의 피처 벡터화 시 fit_transform()을 사용하면 안됨
- 로지스틱 회귀를 통해 학습/예측/평가
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# LogisticRegression
lr_clf = LogisticRegression()
lr_clf.fit(X_train_cnt_vect , y_train)
pred = lr_clf.predict(X_test_cnt_vect)
lr_acc = accuracy_score(y_test, pred)
print(f"CountVectorized Logistic Regression 예측 정확도: {lr_acc:.3f}")- TF-IDF 기반 피처 벡터화
from sklearn.feature_extraction.text import TfidfVectorizer
# TF-IDF Vectorization: train
tfidf_vect = TfidfVectorizer()
tfidf_vect.fit(X_train)
X_train_tfidf_vect = tfidf_vect.transform(X_train)
# TF-IDF Vectorization: test
X_test_tfidf_vect = tfidf_vect.transform(X_test)
# LogisticRegression
lr_clf = LogisticRegression()
lr_clf.fit(X_train_tfidf_vect , y_train)
pred = lr_clf.predict(X_test_tfidf_vect)
lr_acc = accuracy_score(y_test, pred)
print(f"TF-IDF Logistic Regression 예측 정확도: {lr_acc:.3f}")
- 최적 ML 알고리즘/ 피처 전처리/ 하이퍼 파라미터 튜닝
하이퍼 파라미터 튜닝은 GridSearchCV로 진행
# 피처 벡터화의 파라미터 조정
# TF-IDF Vectorization: train
tfidf_vect = TfidfVectorizer(stop_words='english', ngram_range=(1,2), max_df=300 )
tfidf_vect.fit(X_train)
X_train_tfidf_vect = tfidf_vect.transform(X_train)
# TF-IDF Vectorization: test
X_test_tfidf_vect = tfidf_vect.transform(X_test)
# LogisticRegression
lr_clf = LogisticRegression()
lr_clf.fit(X_train_tfidf_vect , y_train)
pred = lr_clf.predict(X_test_tfidf_vect)
lr_acc = accuracy_score(y_test, pred)
print(f"TF-IDF 파라미터 조정 후 예측 정확도: {lr_acc:.3f}")from sklearn.model_selection import GridSearchCV
# 최적 하이퍼 파라미터: C
params = {
"C":[0.01, 0.1, 1, 5, 10]
}
# GridSearchCV
grid_cv_lr = GridSearchCV(lr_clf ,param_grid = params , cv=3 , scoring='accuracy' , verbose=1 )
grid_cv_lr.fit(X_train_tfidf_vect , y_train)
print('Logistic Regression best C parameter :',grid_cv_lr.best_params_ )
# 최적 C 값으로 학습된 grid_cv로 예측/평가
pred = grid_cv_lr.predict(X_test_tfidf_vect)
lr_acc = accuracy_score(y_test, pred)
print(f"로지스틱 최적 하이퍼 파라미터 적용 후 예측 정확도: {lr_acc:.3f}")05. 감성 분석
감성 분석
문서의 주관적인 감성/의견/감정/기분 등을 파악하기 위한 방법
문서 내 텍스트가 나타내는 여러가지 주관적인 단어와 문맥을 기반으로 감정 수치를 계산
금정 감정 지수와 부정 감정 지수로 구성되있음, 이들을 합산해 긍정/부정 감성 결정
감정 분석 방식
(1) 지도 학습
학습데이터와 타깃 레이블 값을 기반으로 감정 분석 학습 수행
이를 기반으로 다른 데이터의 감정 분석 예측
일반적인 텍스트 기반의 분류와 거의 동일
(2) 비지도 학습
Lexicon이라는 일종의 감성 어휘 사전 활용
용어/문맥 정보 이용 -> 긍정적, 부정적 감정 여부 확인
지도학습 기반 감성 분석 실습 - IMDB 영화평
- 데이터 전처리
HTML 형식의 텍스트<br/>태그 삭제 (공백 처리)
숫자/ 특수문자 삭제정규표현식 활용
import re
# <br> HTML 태그 공백으로 변환
review_df["review"] = review_df["review"].str.replace("<br />", " ")
# 영어가 아닌 문자 제거
# re.sub(정규표현식, new_text, old_text)
review_df["review"] = review_df["review"].apply( lambda x : re.sub("[^a-zA-Z]", " ", x) )- 데이터 준비
결정값 클래스인 sentiment 칼럼 추출 - label 데이터 세트
원본데이터 세트에서 id와 sentiment 칼럼 삭제 - 피처 데이터 세트
train_test_split 이용 - 학습 / 테스트용 데이터 세트로 분리
from sklearn.model_selection import train_test_split
y_target = review_df["sentiment"]
X_feature = review_df["review"]
X_train, X_test, y_train, y_test= train_test_split(X_feature, y_target, test_size=0.3, random_state=156)
X_train.shape, X_test.shape
- 피처 벡터화 & 예측 성능 측정
Pipeline 객체이용
count 벡터화 / TF-IDF 벡터화 적용
Classifier로 LogisticRegression 이용
예측 성능 평가 : 테스트 데이터 세트의 정확도 + ROC-AUC 측정
비지도학습 기반 감성 분석
결정된 레이블값을 가지고 있지 않은 데이터를 분석
- Lexicon 기반
주로 감성만을 분석하기 위해 지원 감성 어휘 사전
감정 지수 활용
단어의 위치, 주변 단어, 문맥, POS 등을 참고해 결정 (NLTK 패키지 활용)
- WordNet
NTLK에서 제공하는 방대한 영어 어휘 사전 모듈
다양한 사오항에서 같은 어휘라도 다르게 사용되는 어휘의 시맨틱 정보를 제공
각각의 품사로 구성된 개별 단어를 Synset이라는 개념을 이용해 표현
- Synset
단어가 가지는 문맥 + 시맨틱 정보 제공
synsets() 호출 시 여러개의 Synset객체를 가지는 리스트 반환됨
POS, 정의, 부명제 등을 시맨틱적인 요소를 표현할 수 있음
from nltk.corpus import wordnet as wn
term = 'present'
# present로 wordnet의 synsets 생성
synsets = wn.synsets(term)# Synsets 속성: 이름/품사/정의/부명제
for i, synset in enumerate(synsets):
print('##### Synset name : ', synset.name(),'#####')
print('POS :', synset.lexname())
print('Definition:', synset.definition())
print('Lemmas:', synset.lemma_names())
print("\n")
if i == 3:
break06. 토픽 모델링
문서 집합에 숨어있는 주제를 찾아내는 것
- 머신러닝 기반의 토픽 모델
숨겨진 주제를 효과적으로 표현할 수 있는 중심단어를 함축적으로 추출
- LSA(Latent Semantic Analysis)
기존의 DTM이나 DTM에 단어의 중요도에 따른 가중치를 주었던 TF-IDF 행렬은 단어 의미나 문맥을 전혀 고려하지 못한다는 단점이 존재
LSA는 기본적으로 DTM이나 TF-IDF 행렬에 절단된 SVD를 사용하여 차원을 축소시키고, 이미 계산된 LSA에 새로운 데이터를 추가하여 계산하려고 하면 보통 처음부터 다시 계산해야 함
새로운 정보에 대해 업데이트가 어려움
- LDA(Latent Dirichlet Allocation)
LSA의 단점 보완
문서들은 토픽들의 혼합으로 구성되어져 있으며, 토픽들은 확률 분포에 기반하여 단어들을 생성한다고 가정
데이터가 주어지면, LDA는 문서가 생성되던 과정을 역추적
Count기반의 Vectorizer만 적용
