
07. 문서 군집화
문서 군집화
비슷한 텍스트 구성의 문서를 군집화 하는 것
분석 흐름
(1) 텍스트 전처리
(2) 벡터화
(3) 군집화 알고리즘 적용
(4) cluster_centers(추출) 통해 군집별 핵심 단어 추출
Opinion Review Data 실습
- 텍스트 전처리
import pandas as pd
import glob, os
import warnings
warnings.filterwarnings('ignore')
pd.set_option('display.max_colwidth', 700)
# 아래는 제 컴퓨터에서 압축 파일을 풀어 놓은 디렉터리이니, 여러분의 디렉터리를 설정해 주세요
path = 'OpinosisDataset1.0/topics'
# path로 지정한 디렉터리 밑에 있는 모든 .data 파일들의 파일명을 리스트로 취합
all_files = glob.glob(os.path.join(path, "*.data"))
filename_list = []
opinion_text = []
# 개별 파일들의 파일명은 filename_list 리스트로 취합,
# 개별 파일들의 파일 내용은 DataFrame 로딩 후 다시 string으로 변환하여 opinion_text 리스트로 취합
for file_ in all_files:
# 개별 파일을 읽어서 DataFrame으로 생성
df = pd.read_table(file_,index_col=None, header=0,encoding='latin1')
# 절대경로로 주어진 file 명을 가공. 만일 Linux에서 수행시에는 아래 \\를 / 변경.
# 맨 마지막 .data 확장자도 제거
filename_ = file_.split('\\')[-1]
filename = filename_.split('.')[0]
# 파일명 리스트와 파일 내용 리스트에 파일명과 파일 내용을 추가.
filename_list.append(filename)
opinion_text.append(df.to_string())
# 파일명 리스트와 파일 내용 리스트를 DataFrame으로 생성
document_df = pd.DataFrame({'filename':filename_list, 'opinion_text':opinion_text})
document_df.head()- TF-IDF 기반 vectorization 적용 및 kmeans 군집화 수행
tfIdfVectorizer의 tokenizer 인자로 사용될 lemmatization 어근 변환 함수를 설정
생성 LemNormalize 함수 설정
from nltk.stem import WordNetLemmatizer
import nltk
import string
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
lemmar = WordNetLemmatizer()
# 입력으로 들어온 token단어들에 대해서 lemmatization 어근 변환.
def LemTokens(tokens):
return [lemmar.lemmatize(token) for token in tokens]
# TfidfVectorizer 객체 생성 시 tokenizer인자로 해당 함수를 설정하여 lemmatization 적용
# 입력으로 문장을 받아서 stop words 제거-> 소문자 변환 -> 단어 토큰화 -> lemmatization 어근 변환.
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))군집화 알고리즘 적용
- 군집화 알고리즘 적용
군집이 각 주제별로 유사한 형태로 잘 구성됐는지
문서별로 텍스트가 TF-IDF 변환된 피처 벡터와 행렬 데이터에 대해 군집화를 수행해 어떤 문서끼리 군집되는지 확인
from sklearn.cluster import KMeans
# 5개 집합으로 군집화 수행. 예제를 위해 동일한 클러스터링 결과 도출용 random_state=0
km_cluster = KMeans(n_clusters=5, max_iter=10000, random_state=0)
km_cluster.fit(feature_vect)
cluster_label = km_cluster.labels_
cluster_centers = km_cluster.cluster_centers_- 핵심 단어 추출
군집별 핵심단어 추출
각 군집에 소간 문서는 핵심단어를 주축으로 군집화되어 있음
각 군집을 구성하는 핵심 단어 확인
cluster_centers = km_cluster.cluster_centers_
print('cluster_centers shape :',cluster_centers.shape)
print(cluster_centers)Cluster_centers_속성값을 이용해 각 군집별 핵심 단어 찾기
각 군집을 구성하는 핵심 단어 확인
# 군집별 top n 핵심단어, 그 단어의 중심 위치 상대값, 대상 파일명들을 반환함.
def get_cluster_details(cluster_model, cluster_data, feature_names, clusters_num, top_n_features=10):
cluster_details = {}
# cluster_centers array 의 값이 큰 순으로 정렬된 index 값을 반환
# 군집 중심점(centroid)별 할당된 word 피처들의 거리값이 큰 순으로 값을 구하기 위함.
centroid_feature_ordered_ind = cluster_model.cluster_centers_.argsort()[:,::-1]
#개별 군집별로 iteration하면서 핵심단어, 그 단어의 중심 위치 상대값, 대상 파일명 입력
for cluster_num in range(clusters_num):
# 개별 군집별 정보를 담을 데이터 초기화.
cluster_details[cluster_num] = {}
cluster_details[cluster_num]['cluster'] = cluster_num
# cluster_centers_.argsort()[:,::-1] 로 구한 index 를 이용하여 top n 피처 단어를 구함.
top_feature_indexes = centroid_feature_ordered_ind[cluster_num, :top_n_features]
top_features = [ feature_names[ind] for ind in top_feature_indexes ]
# top_feature_indexes를 이용해 해당 피처 단어의 중심 위치 상댓값 구함
top_feature_values = cluster_model.cluster_centers_[cluster_num, top_feature_indexes].tolist()
# cluster_details 딕셔너리 객체에 개별 군집별 핵심 단어와 중심위치 상대값, 그리고 해당 파일명 입력
cluster_details[cluster_num]['top_features'] = top_features
cluster_details[cluster_num]['top_features_value'] = top_feature_values
filenames = cluster_data[cluster_data['cluster_label'] == cluster_num]['filename']
filenames = filenames.values.tolist()
cluster_details[cluster_num]['filenames'] = filenames
return cluster_details08. 문서 유사도
문서 유사도 측정방법 - 코사인 유사도
벡터와 벡터 간의 유사도를 비교할 때 벡터의 크기보다는 벡터의 상호 방향성이 얼마나 유사한지
코사인 유사도는 두 벡터의 사잇값을 구해서 얼마나 유사한지 수치로 적용
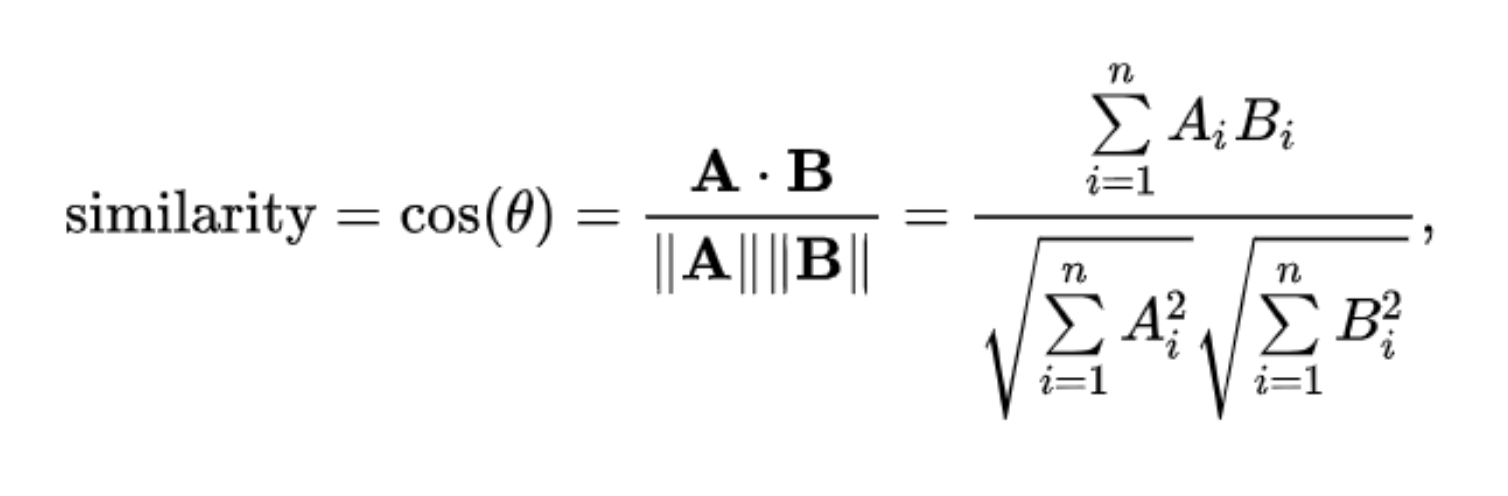
문서 유사도를 측정하는 사이킷런 API
from sklearn.metrics.pairwise import cosine_similarityCosine_similarity()
2개의 입력 파라미터
희소 행렬, 밀집 행렬 모두 가능, 행렬 또는 배열 모두 가능
쌍으로 코사인 유사도 값 제공 ndarray 제공
from nltk.stem import WordNetLemmatizer
import nltk
import string
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
lemmar = WordNetLemmatizer()
# 입력으로 들어온 token단어들에 대해서 lemmatization 어근 변환.
def LemTokens(tokens):
return [lemmar.lemmatize(token) for token in tokens]
# TfidfVectorizer 객체 생성 시 tokenizer인자로 해당 함수를 설정하여 lemmatization 적용
# 입력으로 문장을 받아서 stop words 제거-> 소문자 변환 -> 단어 토큰화 -> lemmatization 어근 변환.
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))import pandas as pd
import glob, os
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
import warnings
warnings.filterwarnings('ignore')
# Define a lemmatization function
def LemNormalize(text):
lemmatizer = WordNetLemmatizer()
stop_words = set(stopwords.words('english'))
words = word_tokenize(text)
return ' '.join([lemmatizer.lemmatize(word) for word in words if word.lower() not in stop_words])
path = r'OpinosisDataset1.0\topics'
all_files = glob.glob(os.path.join(path, "*.data"))
filename_list = []
opinion_text = []
for file_ in all_files:
df = pd.read_table(file_, index_col=None, header=0, encoding='latin1')
filename_ = file_.split('\\')[-1]
filename = filename_.split('.')[0]
filename_list.append(filename)
opinion_text.append(df.to_string())
document_df = pd.DataFrame({'filename': filename_list, 'opinion_text': opinion_text})
tfidf_vect = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english', \
ngram_range=(1, 2), min_df=0.05, max_df=0.85)
feature_vect = tfidf_vect.fit_transform(document_df['opinion_text'])
km_cluster = KMeans(n_clusters=3, max_iter=10000, random_state=0)
km_cluster.fit(feature_vect)
cluster_label = km_cluster.labels_
cluster_centers = km_cluster.cluster_centers_
document_df['cluster_label'] = cluster_label호텔을 주제로 군집화된 문서를 이용해 특정 문서와 다른 문서 간의 유사도 측정
호텔을 주제로 군집화된 데이터 먼저 추출, 이 데이터에 해당하는 TfidfVectorizer의 데이터 추출
09. 한글 텍스트 데이터 처리
한글 NLP 처리의 어려움
한글 언어 처리가 영어 등의 라틴어 처리보다 어려운 이유 - 띄어쓰기, 다양한 조사
- KoNLPy
파이썬의 대표적인 한글 형태소 패키지
- Mecab
오픈 소스 한국어 형태소 분석기
한나눔이나 꼬꼬마 등의 기존 형태소 분석기의 띄어쓰기 구분의 오류나 공개 소스를 구하기 어렵다는 문제를 극복하기 위해 시작됨
원하는 단어가 형태소 분석으로 tagging이 안될때 형태소 분석기에서 사용자 사전을 구축해 해당 단어가 형태소 분석기에 tagging이 될 수 있도록 할 수 있음
네이버 영화리뷰 데이터 실습
-
데이터 전처리
Train_df이 존재하는 Null을 공백으로 변환
숫자의 경우 단어적인 의미가 부족하므로 파이썬 정규 표현식 모듈 re를 이용해 공백으로 변환
import re
# document 결측 공백으로 변환
train_df = train_df.fillna(" ")
# 정규 표현식으로 숫자를 공백으로 변경 (정규 표현식에서 \d는 숫자를 의미)
train_df["document"] = train_df["document"].apply(lambda x: re.sub(r"\d+", " ", x))
# test set 동일 작업
test_df = pd.read_csv('nsmc-master/ratings_test.txt', sep='\t')
test_df = test_df.fillna(" ")
test_df["document"] = test_df["document"].apply(lambda x: re.sub(r"\d+", " ", x))
# id 컬럼 제거
train_df.drop("id", axis=1, inplace=True)
test_df.drop("id", axis=1, inplace=True)
SNS 분석에 적합한 Twitter 클래스를 한글 형태소 엔진으로 이용
Twitter 객체의 morphs() 메서드를 이용하면 입력인자로 들어온 문장을 형태소 단어 형태로 토큰화 해 list 객체로 반환
from konlpy.tag import Twitter
twitter = Twitter()
def tw_tokenizer(text):
# 텍스트를 형태소 단어로 토큰화 후 리스트로 반환
tokens_ko = twitter.morphs(text)
return tokens_ko- 피처 벡터화
사이킷런의 TfidfVectorizer를 이용해 TF-IDF 피처 모델을 생성
- 감정 분석 - 로지스틱 회귀
로지스틱 회귀를 이용해 분류 기반의 감정 분석을 수행
로지스틱 회귀의 하이퍼파라미터 c 최적화를 위해 GridSearchCV를 이용
# GridSearchCV
params = {
"lr_clf__C": [1, 3.5, 10]
}
grid_cv = GridSearchCV(pipeline, param_grid=params, scoring="accuracy", verbose=1)
grid_cv.fit(train_df['document'], train_df['label'])
print(grid_cv.best_params_, round(grid_cv.best_score_,4))- 테스트 데이터 세트로 최종 감정 분석 예측
from sklearn.metrics import accuracy_score
# 예측/평가 (best_estimator로 안해도 이미 최적으로 학습되어 있음)
best_estimator = grid_cv.best_estimator_
pred = best_estimator.predict(test_df["document"])
acc = accuracy_score(test_df["label"], pred)
print(f"Logistic Regression 정확도: {acc:.4f}")Mercari Price Suggestion Challenge
- 데이터 로드
from sklearn.linear_model import Ridge, LogisticRegression
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import pandas as pd
mercari_df = pd.read_csv('train.tsv', sep='\t')
mercari_df.head(3)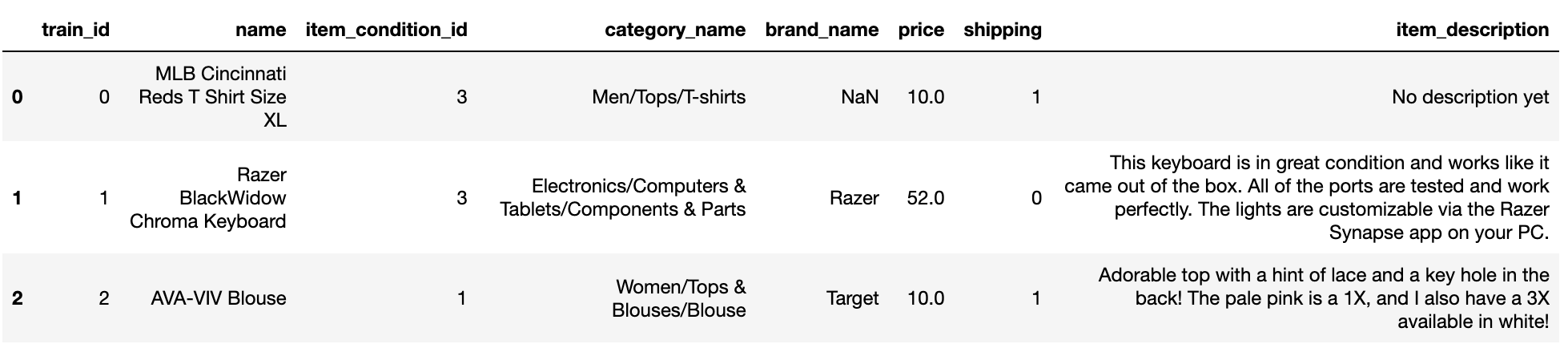
- 피처 type과 Null 여부 확인
가격에 영향을 미치는 중요 요인인 brand_name이 많은 Null을 가직고 있음
- target 값의 데이터 분포
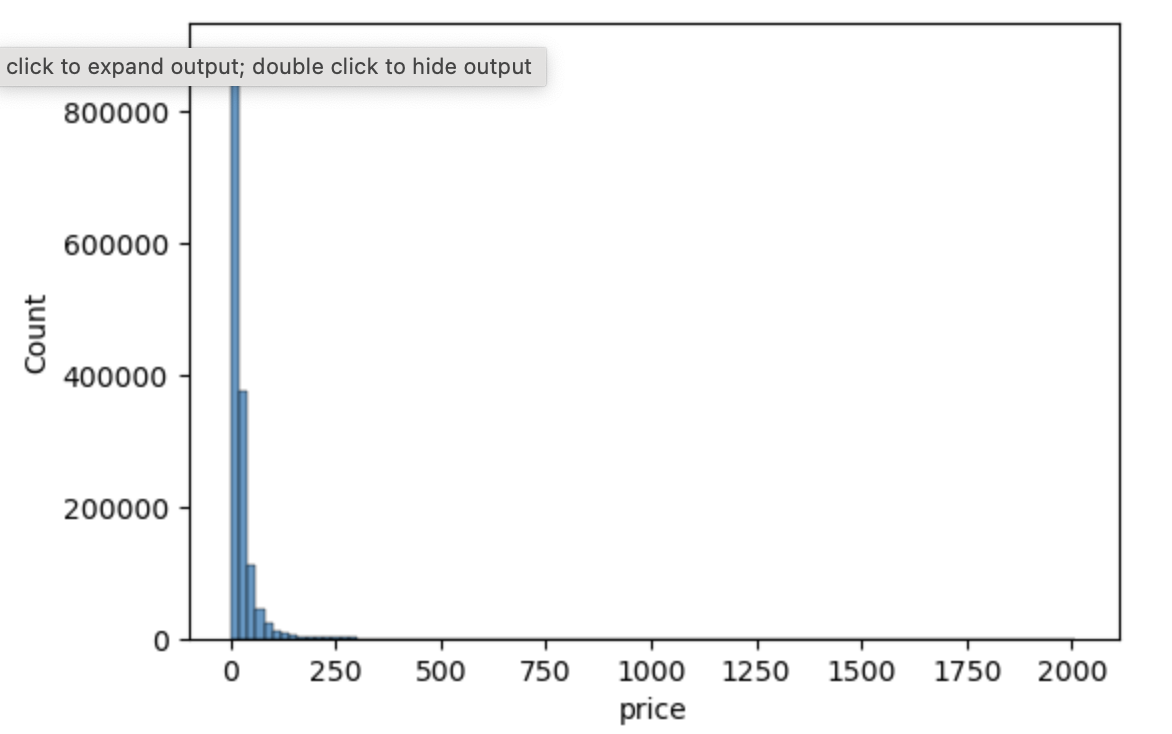
Price 값이 비교적 적은 가격의 데이터 값에 왜곡돼 분포
로그 값으로 변환해 정규 분포 형태로 변환
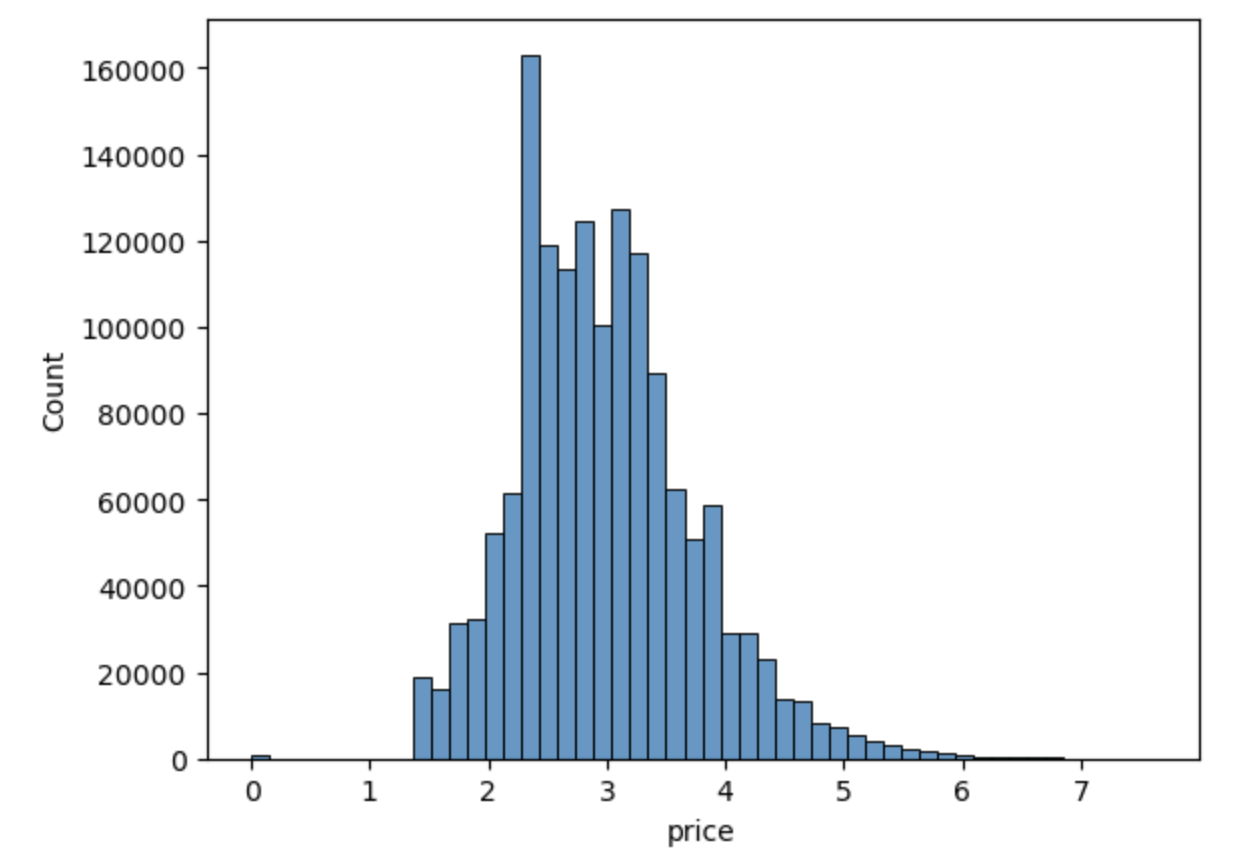
mercari_df['price']= np.log1p(mercari_df['price'])
mercari_df['price'].head(3)- 데이터 전처리
category_name의 '/'를 기준으로 단어 토큰화 후 각각 별도 피처로 저장
Null이 아닌 경우 split("/")을 이용해 대, 중, 소분류를 분리 (리스트로 반환)
Null 일경우 except catch 하여 대, 중, 소분류 모두 'Other Null' 값을 부여
#apply lambda에서 호출되는 대, 중, 소 분할 함수 생성, 대, 중, 소 값을 리스트로 변환
def split_cat(category_name):
try:
return category_name.split('/')
except:
return ['Other_Null', 'Other_Null', 'Other_Null']
#위의 split_cat()을 apply lambda에서 호출해 대,중,소 칼럼을 mercari_df에 생성.
mercari_df['cat_dae'], mercari_df['cat_jung'], mercari_df['cat_so'] = zip(*mercari_df['category_name'].apply(
lambda x : split_cat(x)))
print("대분류 유형 :\n", mercari_df['cat_dae'].value_counts())
print("중분류 개수 :", mercari_df['cat_jung'].nunique())
print("소분류 개수 ", mercari_df['cat_so'].nunique())- fill_na()로 다른 칼럼들의 Null 값 처리
mercari_df['brand_name'] = mercari_df['brand_name'].fillna(value='Other_Null')
mercari_df['category_name'] = mercari_df['category_name'].fillna(value='Other_Null')
mercari_df['item_description'] = mercari_df['item_description'].fillna(value='Other_Null')
# 각 칼럼별로 Null 값 건수 확인. 모두 0이 나와야 합니다.
mercari_df.isnull().sum()- 피처 인코딩과 피처 벡터화
본 대회에서 예측 모델은 상품 가격을 예측해야 하므로 회귀 모델을 기반으로 함
선형 회귀에서는 원-핫 인코딩 선호
피처 벡터화의 경우 짧은 텍스트 - Count 기반 벡터화
긴 텍스트 - TF-IDF 기반 벡터화 적용
- 릿지 회귀 모델 구축 및 평가
예측된 price값을 다시 지수 변환을 통해 원복해야 함
Evaluate_org_price(y_text, preds) 원복된 데이터를 기반으로 RMSLE를 적용
- 릿지 회귀 예측
linear_model = Ridge(solver="lsqr", fit_intercept=False)
sparse_matrix_list = (X_name, X_brand, X_item_cond_id,
X_shipping, X_cat_dae, X_cat_jung, X_cat_so)
linear_preds, y_test = model_train_predict(model=linear_model, matrix_list = sparse_matrix_list)
print('Item Description을 제외했을 때 rmsle 값:', evaluate_org_price(y_test, linear_preds))
sparse_matrix_list = (X_descp, X_name, X_brand, X_item_cond_id,
X_shipping, X_cat_dae, X_cat_jung, X_cat_so)
linear_preds, y_test = model_train_predict(model = linear_model, matrix_list = sparse_matrix_list)
print('Item Description을 포함한 rmsle 값:', evaluate_org_price(y_test, linear_preds))- LightGBM 회귀 모델 구축과 앙상블을 이용한 최종 예측 평가
LightGBM을 이용해 회귀 수행한 뒤 앞서 구한 릿지모델 예측값과 LightGBM 모델 예측값을 간단한 앙상블 방식으로 섞어서 최종 회귀 예측값을 평가
from lightgbm import LGBMRegressor
sparse_matrix_list = (X_descp, X_name, X_brand, X_item_cond_id,
X_shipping, X_cat_dae, X_cat_jung, X_cat_so)
lgbm_model = LGBMRegressor(n_estimators=200, learning_rate=0.5, num_leaves=125, random_state=156)
lgbm_preds, y_test = model_train_predict(model = lgbm_model, matrix_list= sparse_matrix_list)
print('LightGBM rmsle 값:', evaluate_org_price(y_test, lgbm_preds))
preds = lgbm_preds*0.45 + linear_preds*0.55
print('LightGBM과 Ridge를 ensemble한 최종 rmsle 값:', evaluate_org_price(y_test, preds))