
파이썬, 유투브API 그리고 ChatGPT 를 활용하여 ‘웹크롤링’ 을 해보았다. 문서를 살펴보고 구글링을 하다보니 유투브API 로 할수있는것이 무궁무진한데 이번 실습에서는 ‘댓글추출’ 을 해보았다.
실습목적
- 웹크롤링
- 파이썬 패키지 및 라이브러리 설치
- 유투브API 활용
- ChatGPT 활용
--> 웹크롤링 이란?
Web상에 존재하는 Contents를 수집하는 작업
- HTML 페이지를 가져와서, HTML/CSS등을 파싱하고, 필요한 데이터만 추출하는 기법
- Open API(Rest API)를 제공하는 서비스에 Open API를 호출해서, 받은 데이터 중 필요한 데이터만 추출하는 기법
- Selenium등 브라우저를 프로그래밍으로 조작해서, 필요한 데이터만 추출하는 기법
이번 실습에서는 2번의 방식으로 웹크롤링을 진행하였다.
✏️참고
https://www.fun-coding.org/post/crawl_basic2.html#gsc.tab=0
--> 파이썬
파이썬 실행을 위한 패키지 및 라이브러리 설치가 이번 실습에서 파이썬에 관해 얻어야할 전부다. 실습의 목적은 파이썬 공부가 아닌 웹크롤링, 유투브API, ChatGPT 의 활용에 있기 때문이다.
‘웹크롤링’을 할 때, 데이터전문가들 혹은 개발 비전공자들이 비교적 쉽고 빠르게 접근할 수 있는 방법이 파이썬을 활용하는 방법이다.
- 파이썬 설치
- 파이썬 라이브러리 설치 (python3 을 설치했기때문에 라이브러리 설치시에도 pip3 사용)
어떤 기능을 사용하느냐에 따라서 설치해야하는 라이브러리도 다른데, ChatGPT는 필요한 라이브러리 까지 알려준다. 설치방법 및 실행방법은 물론이다.
터미널 명령
- pip3 install requests
- pip3 install BeautifulSoup4
- pip3 install google-api-python-client
- 텍스트 에디터 선택
파이썬 에디터로 ‘파이참’을 많이 이용하더라.
나의 목적은 파이썬이 아니기 때문에 일단 기존에 사용하던 editor + 확장 프로그램 을 활용해 보기로 한다.
vscode + extension(Python)

--> 유튜브 API
https://developers.google.com/youtube/v3/docs?hl=ko
- API key 발급
- 수집하고자 하는 정보가 담긴 JSON 파일 추출
--> ChatGPT
- 요청사항을 순차적으로 상세하고 명확하게 전달한다.
- 한번에 제대로 실행이 안되고 에러가 날 수 있다. 수정사항을 계속 받아 적용해도 에러가 나더라. 나의 경우는 한글파일로 인코딩해달라는 요청에 대한 답을 얻지 못했다. 이런 경우는 ChatGPT에만 집착하지말고 구글링 등 다른 방법을 찾아서 해결하면 된다.
--> - 계속되는 인코딩문제
ChatGPT 가 알려준 cp949, euc-kr, utf-8 해결 불가,
구글링을 통해 utf-8-sig 으로 해결
좋아하는 유투버의 영상을 고르고 실습을 진행했다. 공부도 하고 영상도 한번 더 보고 😃-😃
ChatGPI 에게 요청
1. 파이썬과 유투브API 를 활용하여 웹크롤링 코드를 만들겠다.
2. 유투브 영상에서 댓글을 추출하겠다.
3. 유투브 API key 는 이러하다.
4. 비디오ID 는 이러하다 (유투브 비디오 ID 는 유투브 영상링크, API key 를 통해 추출한 JSON 파일, 또는 구글링을 통해 확인 가능)
5. 댓글을 추출하고, 그것을 csv 파일로 저장해라.
6. 한국어 인코딩이 필요하고, 댓글작성자, 날짜, 공감횟수 관련 정보가 필요하다.
in English
Make codes for the web crawling with python, using YouTube API.
I want to get the comments from a specific video on YouTube.
API key is here. "MY_API_KEY".
VideoID is here. "VIDEO_ID".
Get all the comments and save them with csv file. Also I need Korean encoding. Also comments' authors, date, number of likes.
--> ChatGPT 작성 코드
import pandas
from googleapiclient.discovery import build
# 각기다른 추출위해 videoID 변경
# csv 파일명은 영상id 또는 영상title
#Id = 'MOVIE_ID'
comments = list()
api_obj = build('youtube', 'v3', developerKey='MY_API_KEY')
# 댓글수집
response = api_obj.commentThreads().list(part='snippet,replies', videoId='VIDEO_ID', maxResults=100).execute()
while response:
for item in response['items']:
comment = item['snippet']['topLevelComment']['snippet']
comments.append([comment['textDisplay'], comment['authorDisplayName'], comment['publishedAt'], comment['likeCount']])
if item['snippet']['totalReplyCount'] > 0:
for reply_item in item['replies']['comments']:
reply = reply_item['snippet']
comments.append([reply['textDisplay'], reply['authorDisplayName'], reply['publishedAt'], reply['likeCount']])
if 'nextPageToken' in response:
response = api_obj.commentThreads().list(part='snippet,replies', videoId='sWC-pp6CXpA', pageToken=response['nextPageToken'], maxResults=100).execute()
else:
break
# 댓글저장
df = pandas.DataFrame(comments)
df.to_csv('./test2.csv', header=['comment', 'author', 'date', 'num_likes'],encoding="utf-8-sig")
# df = pandas.DataFrame(comments)
# df.to_excel('results.xlsx', header=['comment', 'author', 'date', 'num_likes'], index=None)
print(comments)
--> 저장된 CSV 파일
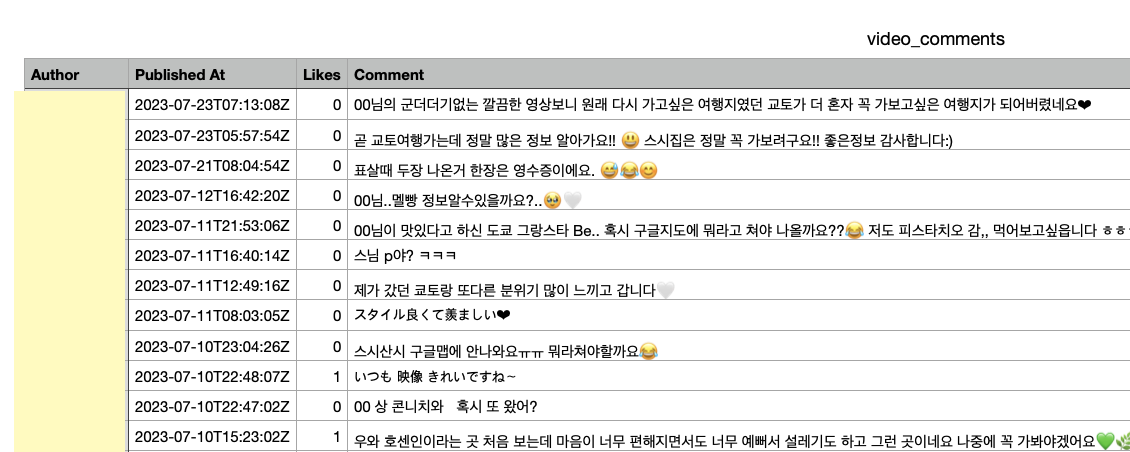

즐겁게 읽었습니다. 유용한 정보 감사합니다.