이번 글부터는 진행했던 NLP 프로젝트에 관해 정리해보겠습니다.
목차는 다음과 같습니다:
목차
1. 주제 선정
2. 모델 선택
3. 데이터 처리
4. 파인 튜닝
이 글에서는 1~3번 과정에 관해 작성하고, 다음 글에서 파인 튜닝 과정에 관해 다루겠습니다.
우선, 이 프로젝트에서 저는 모델 학습 보다 데이터 쪽의 역할을 주로 담당하였습니다. NLP 모델을 학습시키기 위한 데이터 형태를 만들어주는 역할을 담당하였습니다.
주제 선정
당시 딥러닝에 관해 입문하며 기초를 배우고 있었습니다. 토이 프로젝트를 NLP 주제로 진행하였기 때문에, 후반기에도 NLP에 관해 심층적으로 공부하고 싶었습니다. 그래서 NLP 안에서 주제를 생각해보았습니다.
여러 주제들 가운데 문장 생성 과 관련된 주제를 생각해보았습니다. 우리가 많이 쓰는 GPT를 생각하면서요. 문장을 생각하다 소설이라는 주제가 나왔고, 이에 관해 주제를 구체화하였습니다.
단순히 AI와 대화를 주고 받으며 소설을 완성하는 것은 사용자가 개입할 요소가 적다고 생각했습니다. 따라서, 사용자가 직접 감정과 서사구조를 선택할 수 있도록 하여 조금 더 사용자 친화적인 프로그램을 만들어보고자 했습니다.
모델 선택
프로젝트 초반에는 Transformer와 GPT-1에 관한 논문을 읽으며 NLP 모델의 구조를 이해하였습니다. 프로젝트 특성상 기간이 충분하지 않았고, 딥러닝에 입문하는 단계이었기에 많은 논문을 접하거나 기초부터 하나하나 배우는 것에는 시간적인 한계가 있었습니다. 그래서 모델을 직접 설계하는 것에서 이미 공개된 모델을 활용하는 것으로 프로젝트 방향을 변경했습니다.
그렇다면, 우리의 프로젝트에 적합한 NLP 모델은 무엇일까요? 보통 NLP 모델들이 한국어보다는 영어에 특화된 모델들이 많았으나, 저희는 영어말고 한국어로 프로젝트를 진행하고 싶은 마음이 컸습니다. 따라서, 한국어에 대해 Pre-trained된 모델이 필요했죠.
그래서 공개되어있는 KoGPT를 선택하였습니다.
데이터 처리
이 프로젝트에서 어려웠던 점 중 하나는 input 데이터의 형태였습니다. Pre-train된 GPT를 우리의 목적에 맞게 파인튜닝하기 위해서는 우리 목적에 맞는 input data가 들어가야했기 때문입니다.
그렇다면 여기서 말하는 우리의 목적은 무엇일까요?
이 프로젝트에서는 AI와 사용자가 대화를 주고 받으며 소설을 완성해야합니다. 대화를 주고 받는다는 것은 무엇일까요?
AI가 이전 대화를 기억하고, 맥락에 맞게 답변을 주어야 합니다. 여기서 저희는 대화하는 상황을 Q&A로 생각했습니다. 사용자가 문장을 입력하면 AI는 이에 맞는 답변을 주는 것이죠.

따라서, 데이터 처리 단계에서 이 형식에 맞도록 데이터를 가공해주어야 합니다.
데이터
데이터는 AI hub의 다양한 문화 콘텐츠 스토리 데이터를 활용했습니다. 직접 데이터를 수집하는 것이 좋을까도 생각했지만, 저작권 문제를 생각하여 이 데이터를 선택하게 되었습니다.
데이터 구조는 링크에서 확인할 수 있습니다. .json 파일로 구성되어 있습니다. 
전처리
Fine-tuning시킬 데이터를 만듭니다. 위에서 이야기했듯 사용자 친화적인 프로그램을 만들기 위해 감정과 서사 구조는 사용자가 입력하도록 합니다. 그래서 감정과 서사 구조에 대한 전처리를 진행하고, Q&A 형식을 만들어주었습니다.
먼저, .json 파일들을 읽어 데이터프레임으로 저장합니다. 저장할 때는 다음과 같은 열들만 저장합니다.

(1) 감정
주어진 데이터의 감정을 그대로 가져가기에는 종류가 너무 많았습니다. 따라서 종류를 줄여주되, 데이터의 불균형도 처리해야했습니다. 데이터의 불균형이 심하면 모델을 학습시킬 때 편향된 결과를 초래할 수 있기 때문입니다.
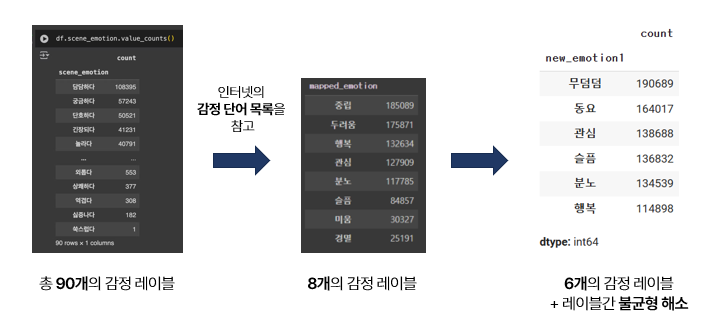
감정 단어 목록을 참고하여, 직접 8개의 감정 레이블을 다시 설정해주었고, 데이터 불균형 문제를 해소하기 위해 최종적으로 6개의 감정 레이블로 만들어주었습니다.
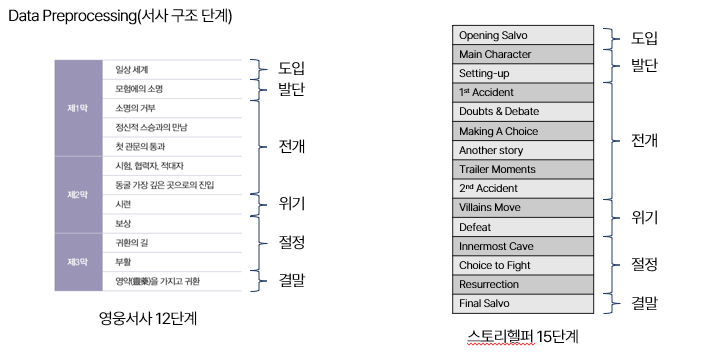
(2) 서사구조
서사구조도 감정과 마찬가지로 종류가 많았고, 영웅서사와 스토리헬퍼 사이에는 다른 서사구조로 되어있었습니다. 따라서 이 부분도 직접 레이블링을 다시 해주었습니다.
(3) 기타 처리
이 외에 기타 처리도 해주었습니다. 소설의 생동감을 위해 대사와 평서문을 구분해줄 필요가 있었습니다. 원래 데이터의 문장은 이를 narrative와 script로 나누어 따로 기입하였지만, script인 문장들은 큰 따옴표(")로 감싸주어, 모델이 학습할 때 이를 반영하도록 처리해주었습니다.
또한, 등장인물 이름을 맥락에 맞게 전달되도록 하기 위해 따로 이를 수집하여 모델이 학습할 수 있도록 하였습니다. 모델을 학습하는 과정에서 모델이 데이터 속 등장인물 이름만을 인식하는 문제가 있었기 때문입니다. 예를 들어, 사용자는 영희가 주인공인데 갑자기 언급되지도 않은 C001이 나오는 문제가 있었습니다.
(4) Q&A
대화를 주고 받는 상황을 저희는 Q&A로 정의했습니다. 그렇다면, input data도 그렇게 생겨야 모델도 이에 맞춰 기능을 하겠죠?
그리고 추가로 Q&A는 내용이 이어져야 합니다. 따라서, Q는 한 문장으로, A는 3문장 이하로 구성하여 AI가 한 문장이 아닌 다양한 길이의 답변을 할 수 있도록 하였습니다.

이렇게 완성된 데이터를 활용해 KoGPT를 fine-tuning해주었습니다. 이에 관한 내용은 다음 글에서 작성해보도록 하겠습니다.
이제까지는 했던 머신러닝 모델이 아닌 AI 모델을 학습시키기 위해 데이터 전처리를 해보았는데 생각보다 고려할 점이 많아서 데이터 처리 자체가 많은 시행착오를 겪었습니다. 이 과정에서 데이터 불균형 문제 해소의 중요성, input 데이터의 형태 등을 어떤 방식으로 고려해야하는지 고민하는 과정에서 성장했다고 생각합니다.
추가로, NLP 관련한 논문을 이번 기회에 RNN부터 읽어보고 싶다는 생각을 했습니다. 이번 방학에 도전 !
