이번 글은 지난 글에 이어서 작성하는 글입니다. KoGPT와 대화를 주고 받으며 한 편의 소설을 완성시키는 테스크를 완성하기 위해 데이터를 형태에 맞게 만들어주었습니다. 그 과정은 지난 글에서 확인할 수 있습니다.
목차
1. KoGPT 파인 튜닝하기
2. 결과 예시
이 글에서는 파인 튜닝시키는 과정과 결과에 관해 간단히 살펴보겠습니다.
KoGPT 파인 튜닝하기
Pre-train된 KoGPT를 우리의 테스크에 맞게 파인 튜닝시켜줘야할 필요가 있습니다. 우리는 목적은 대화를 주고 받으며 소설 완성하는 것이기 때문에,
데이터 자체를 Q&A 형식으로 만들어주었습니다.
소설은 이야기이기 때문에 맥락도 중요하기 때문이죠.

이렇게 만들어진 데이터를 모델에 input으로 넣어줍니다.
그대로 데이터만 넣어줄 수는 없고, 몇 가지 고려할 점들이 존재합니다.
(1) 한글 주인공 인식
여러 번 모델을 학습시키고 실험을 하며 인식한 문제점 중 하나는 주인공 이름 이었습니다. 사용자가 입력한 이름을 인식하지 못하거나 학습했던 등장인물의 이름만을 출력하는 문제가 발생한 것이죠.
그래서 NER 방식을 도입하게 됩니다. NER은 간단히 이야기하면, 명명된 개체명을 인식하는 방식입니다. 저희는 한국어 인물 이름에 최적화된 NER을 사용하여 텍스트에서 주요 개체명인 인물 이름을 분리하여 인식할 수 있도록 하였습니다.
(2) 입력 토큰 길이
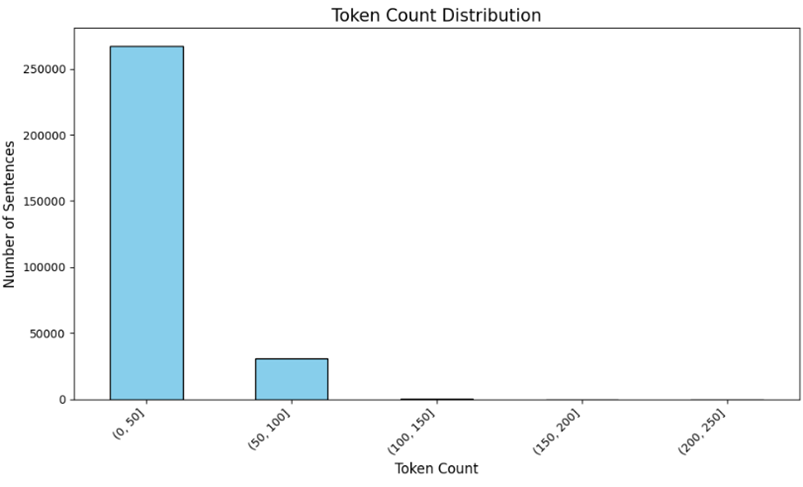
모델을 학습시키기 위해 체크해야할 것은 토큰 길이였습니다. 저희는 제한된 코랩 GPU 환경에서 모델을 학습시켰기에 모델의 크기를 줄이면 줄일수록 좋았습니다. 그래서 학습시킬 문장의 토큰 길이를 확인하여 input 길이를 조정해주었습니다.
최대 100정도의 크기를 가졌으니 Q와 A를 고려하여 max_length는 256으로 설정해주었습니다.
(3) Attention Mask
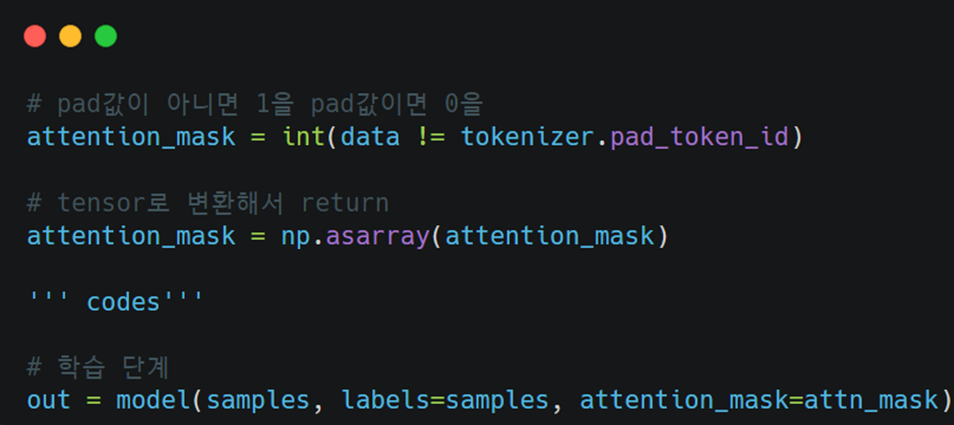
Attention Mask를 설정하여 정확도를 높이고, 계산 비용도 줄여줄 수 있었습니다.
(4) 맥락
소설이 이어지는 느낌이 강하게 들기 위해서는 사용자가 입력한 맥락을 모델이 기억할 필요가 있습니다. 이 부분을 어떻게 해결할 수 있을지 고민해본 결과, sliding window의 방식을 알게 되었습니다.
사용자가 입력한 문장을 다시 모델에 넣어줘서 모델이 맥락을 인식할 수 있도록 만들어주었습니다. 하지만, 이 방식은 단기적으로 효과적이고 오류가 쌓일 수 있다는 단점을 지니고 있습니다.
이러한 부분들이 이 프로젝트의 한계점 및 보완점에 속합니다.
간략하게 4가지 정도를 고려하여 파인튜닝하여 모델을 파인튜닝하고 저희의 니즈에 맞게 완성시켰습니다.
결과 예시

결과는 gradio로 구현하였으며, 이 사진은 발표할 때 사용했던 사진입니다. 다음과 같이 사용자가 입력할 문장과 함께 서사구조와 감정을 입력하면, 모델은 맥락에 맞게 소설을 이어 작성합니다.
이 프로젝트에서 파인 튜닝 과정은 저의 역할이 아니었기 때문에 깊게 이해하지는 못한 거 같아 아쉬운 마음이 있습니다. 시간적인 여유가 생겼을 때, NLP에 집중해서 공부해보고 싶다는 생각이 다시 한 번 들었어요. 입문은 역시 RNN 논문으로 해아하려나요..? ㅎㅎ
