1. 인터넷 통신
컴퓨터 둘은 수많은 노드(node) 들로 연결되어있는 인터넷에 연결하여 서로 통신을 주고 받습니다.
여기서 노드(node)란 네트워크에 연결되어 있는 1개 1개의 기계를 의미합니다. 전 세계적으로 수 많은 노드들이 연결되어있는 인터넷 세상에서 서로 떨어져있는 두 컴퓨터는 어떻게 통신을 주고 받을 수 있을까요?
2. IP(인터넷 프로토콜)
우선 IP(Internet Protocol)의 개념은 아래와 같습니다.
IP 역할
- 지정한
IP 주소(IP Adress)에 데이터 전달 패킷(Packet)이라는 통신 단위로 데이터 전달
패킷(Packet) 이란
Package과bucket의 합성어- 정보를 보낼 때 특정 형태를 맞추어 보내는 것.(데이터 블록 혹은 조각)
IP 패킷 이란
-
출발지IP, 목적지 IP 등 IP와 관련된 정보들이 들어있는 패킷
현실세계로부터 생각을 해보면 좋을 것 같습니다. A가 B에게 편지를 보내려고 합니다. A가 편지를 보내기 위해선 B의 집 주소를 알아야 합니다. 이처럼 인터넷 세상에서도 각 장치에게 주소를 부여합니다. 그리고 이를 IP 주소(IP Address)라고 합니다.
그리고 컴퓨터가 다른 컴퓨터에게 데이터를 보낼땐 데이터를
IP Packet으로 감싼 뒤 보냅니다.(수 많은 노드들은 목적지 IP를 확인하며 다른 노드에게 패킷을 보냅니다.)
주소만 알면 모든것이 가능 할 것이라고 생각 할 수도 있지만, B가 이사를 가버리거나 그 집이 사라졌다면... 편지를 보내더라도 답장을 받을 수 없을 것입니다. 혹은 배달하던 트럭이 도둑(?) 맞아서 편지가 통째로 사라지거나 할 수도 있습니다.
인터넷 세상도 마찬가지 입니다. 이를 조금 전문적인 용어로 바꿔보겠습니다.
IP 프로토콜의 한계
- 비연결성
- 패킷을 받을 대상이 없거나 서비스 불능 상태여도 패킷 전송
- 비신뢰성
- 중간에 패킷이 사라지면?
- 패킷이 순서대로 안오면?
- 프로그램 구분
- 같은 IP를 사용하는 서버에서 통신하는 애플리케이션이 둘 이상이라면?
이처럼 IP 프로토콜은 위와 같은 한계를 가지고 있습니다. 그렇다면 위의 한계를 해결하기 위해선 무엇이 필요할까요?
3. TCP와 UDP
IP의 한계를 극복하기 위해선 TCP와 UDP가 필요합니다. 이를 이해하기 전에 필요한 선지식부터 학습해보도록 하겠습니다.
인터넷 프로토콜 스택의 4계층
- 4계층: 애플리케이션 계층 - HTTP, FTP
- 3계층: 전송 계층 - TCP, UDP
- 2계층: 인터넷 계층 - IP
- 1계층: 네트워크 인터페이스 계층
프로토콜 계층
- 애플리케이션 계층: 웹브라우저, 네트워크 게임, 채팅 프로그램, SOCKET 라이브러리...
- OS 계층: TCP, UDP, IP
- 네트워크 인터페이스 : LAN 드라이버, LAN 장비
위는 우선 인터넷 프로토콜의 계층에 관한 설명입니다. 보시다시피 4계층으로 이루어져있고, 4계층에서 1계층으로 내려간 뒤 인터넷을 이용해 통신을 합니다.
애플리케이션 계층에서 'Hello, world!' 라는 메세지를 작성한 뒤, 다른 PC에 보낸다고 가정하겠습니다. 이때 정보가 전환되는 과정은 아래외 같습니다.
계층별 정보 변환 과정
- 프로그램이 'Hello, World!' 메시지 생성
- SOCKET 라이브러리를 통해 전달
TCP 정보 생성, 메시지 데이터 포함IP패킷 생성, TCP 데이터 포함- 슝~
위에서 IP 패킷으로 데이터를 한번 감싼다고 했습니다. 그리고 TCP는 IP 패킷으로 감싸기 전에 TCP 정보를 미리 생성하여 메시지를 먼저 감쌉니다. 따라서 IP 패킷은 TCP 데이터와 메시지 데이터를 합친 데이터를 감싸는 것입니다.

그렇다면 TCP란 무엇이길래 IP의 한계를 극복시켜준다는 것일까요?
TCP(Transmission Control Protocol)란?
- 전송 제어 프로토콜
- 신뢰할 수 있는 프로토콜
TCP(Transmission Control Protocol)는 전송 제어 프로토콜입니다. 풀어 설명하면, 데이터를 전달할 때 전송을 신뢰할 수 있게 해주는 약속입니다. 이런 약속을 지키기 위해서 TCP는 다음과 같은 특징을 같습니다.
TCP의 특징
- 연결지향 - TCP 3 way handshake(가상 연결)
- 데이터 전달 보증
- 순서 보장
연결지향 - TCP 3 way handshake
TCP는 데이터를 보내기 전에 우선적으로 데이터를 보내려는 IP주소가 유효한지 확인하는 과정을 거칩니다. 그리고 이를 TCP 3 way handshake 라고 부릅니다. handshake의 과정은 아래처럼 진행됩니다.
- A컴퓨터가 B컴퓨터에게 접속 요청인
SYN를 보낸다. - B컴퓨터는 A컴퓨터에게 요청 수락인
ACK와SYN를 보낸다. - A컴퓨터는 B컴퓨터에게 요청 수락인
ACK를 보낸다.
두 컴퓨터가 접속 요청(SYN)을 받고 요청 수락(ACK)를 받았기에 두 컴퓨터는 논리적으로 연결되어 있다고 확신할 수 있는 상태가 됩니다. 그리고 이를 통해서 IP 프로토콜의 비연결성 문제를 해결할 수 있습니다.
데이터 전달 보증
A컴퓨터와 B컴퓨터가 연결되고 난 후, 데이터 전송을 진행합니다. 그리고 B컴퓨터가 데이터를 받을 때 마다 A컴퓨터에게 데이터를 잘 받았다고 메세지를 보내줍니다. 그리고 데이터를 받았다는 메시지가 안온다면 A컴퓨터는 해당 데이터를 다시 보내줍니다. 이렇게 해서 TCP는 IP 프로토콜의 비신뢰성 중 데이터 소실 문제를 해결할 수 있습니다.
순서 보장
데이터를 한 번만 보낸다면 순서가 상관 없겠지만, 동영상 같이 용량이 큰 정보를 보낼땐 하나의 데이터를 여러개의 패킷으로 나누어 전송합니다. 이때 발생할 수 있는 문제는 모든 패킷이 일정한 노드를 타고 가는것이 아니라, 서로 다른 노드들을 거쳐서 가기 때문에 순서가 각각 다르게 B컴퓨터로 도착할 수 있습니다. 이를 해결하기 위해서 TCP는 만약 패킷1, 패킷3, 패킷2 순서대로 도착을 했다면 패킷2부터 A컴퓨터에게 다시 요청합니다. 이렇게 해서 IP 프로토콜의 비신뢰성 중 패킷 순서 문제를 해결할 수 있습니다.
TCP는 위와같은 특징으로 신뢰성을 보장받고 현재 대부분 TCP를 사용하고 있습니다. 하지만 TCP를 위해선 handshake도 해야하고 데이터도 보내달라 해야해서 때에 따라서 필요한 스팩보다 과하게 데이터를 선송하는 경우가 될 수도 있습니다. 그래서 상황에 맞춰서 직접 커스텀 할 수 있는 프로토콜인 UDP가 있습니다.
UDP 특징
- 하얀 도화지에 비유(기능이 거의 없음)
- 연결 지향X
- 데이터 전달 보증X
- 순서 보장X
- 데이터 전달 및 순서가 보장되지 않지만, 단순하고 빠름
- 정리
- IP와 거의 같다. + PORT + 체크섬 정도만 추가
- 애플리케이션에서 추가 작업 필요
어? 여기서 나온 PORT는 무엇이죠?? 그리고 아직 IP의 한계인 프로그램 구분 문제가 해결 되지 않았습니다... 이어서 쭉 가보겠습니다.
4. PORT
port란 영어로 항구란 뜻입니다. 인터넷은 거대한 바다입니다. 그 거대한 바다를 타고 온 배들은 항구에 정박하여 컨테이너를 각각 필요한 곳으로 옮깁니다. port도 이와 같은 역할을 합니다. 컴퓨터 하나엔 여러 프로그램이 실행되고 있습니다. 모든 애플리케이션들은 모두 하나의 IP를 타고와서 TCP/UDP를 이용하여 데이터를 받고 있을것입니다. 그렇다면 각 애플리케이션들의 데이터들이 섞이지 않을까요? 예상하셨겠지만 port 덕분에 그런 일은 발생하지 않고 우리가 유튜브로 음악을 들으며 카카오톡을 할 수 있는 것입니다.
프로그램들은 각각 하나의 포트를 사용하고 있습니다. 그리고 TCP 안에는 출발 port 번호와 도착 port 번호가 들어있습니다. 따라서 같은 IP를 타고 들어오더라도 TCP 계층에서 port 번호에 따라 데이터가 분류 됩니다.
위의 말을 정리하자면, IP 주소는 컴퓨터를 찾을 때 필요한 주소이고, Port는 컴퓨터 안에서 프로그램을 찾을 때 사용합니다.
Port 번호는 0~65535 까지 있습니다. http는 80포트를 사용하고 https는 443을 사용합니다. 그리고 테스트 서버? 는 주로 8080을 많이 사용합니다.
이렇게 해서 IP주소의 한계를 모두 타파할 수 있었습니다. 그렇다면 정말 남은 딱 하나의 문제는 무엇일까요?
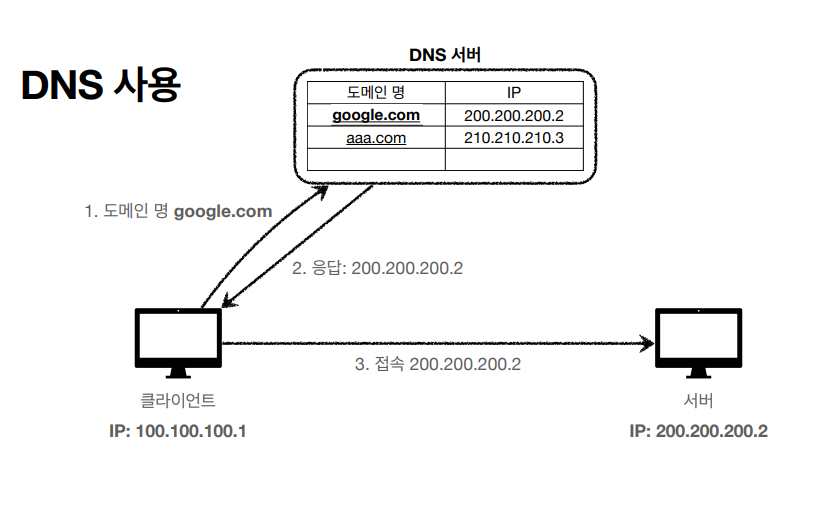
5. DNS
(호흡이 길어서 쓰기 조금 힘드네요... 후딱 쓰겠습니다 ㅎ)
IP주소의 최대 단점은... 사용자가 읽기 어렵다는 것입니다. 게다가 서버의 IP주소가 바뀐다면 백날 알고있던 IP 주소로 접속을 시도해도 들어가지지 않을 것입니다. 이를 해결하기 위해서 사람들은 IP 주소에 이름을 달아주었습니다. 그리고 IP 주소의 이름을 domain이라고 부릅니다.
domain?
- 인터넷에 연결된 컴퓨터를 사람이 쉽게 기억하고 입력할 수 있도록 문자(영문, 한글 등)로 만든 인터넷주소
도메인의 예시론 'naver.com'이나 'google.com'이 있습니다. 인터넷 검색창에 naver.com을 검색하면 늘 네이버 페이지로 이동합니다. 이게 가능한 이유는 DNS 덕분입니다. DNS란 도메인 네임 시스템(Domain Name System)입니다. 쉽게 말해서 도메인 명을 IP주소로 변환해주는 시스템 입니다. 따라서 서버의 IP 주소가 변하더라도 DNS서버에 바뀐 IP 주소를 입력해주면 사용자는 항상 같은 도메인 주소로도 바뀐 IP 주소에 접근할 수 있게 됩니다.