8일차: 뉴럴네트워크 다중 분류_2
8일차 요약
- 오전: labelimg로 bb 그려서 데이터 레이블링 작업 해보기
- 오후: RNN 실습 프로젝트 진행
labelimg로 bounding box 그리기
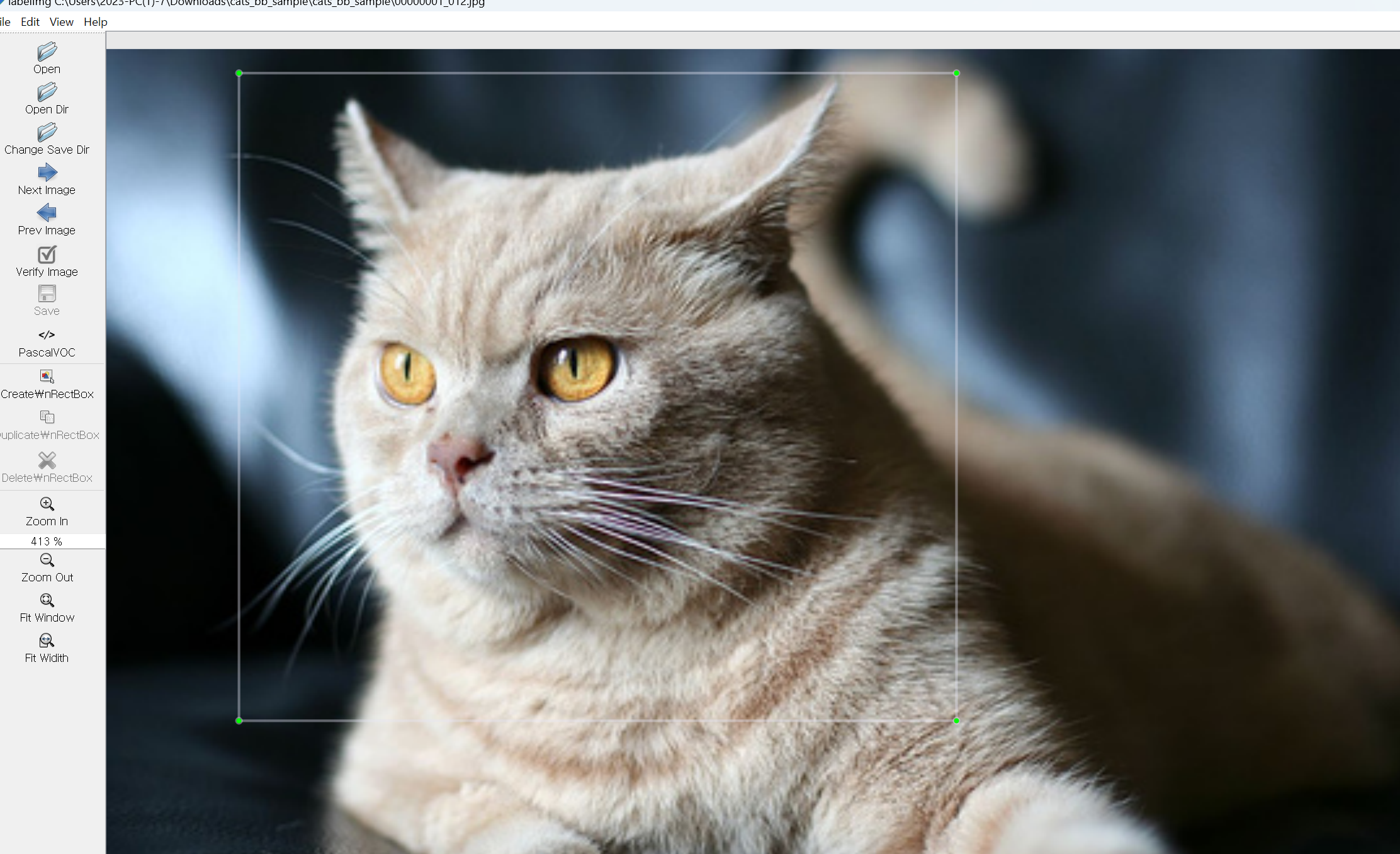
- labelimg 열기
- 좌측 메뉴 중 Create\nRectBox를 클릭
- 원하는 위치에 bounding box 그리기
- label 입히기
- 저장(xml 형식)
segmentation은 labelme로 가능
RNN 실습
삼성 주식 데이터를 활용하여 순환신경망으로 주식 예측하기
- 이게 훈련 데이터 x를 scaling 하니까 validation 이 아주 낮게 나옴
- 해결 방법으로는 y도 scaling을 해주기 or 훈련 모델을 깊게 쌓고 훈련 에포크 늘리기 였음
# y scaling
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
df['Date'] = pd.to_datetime(df['Date'])
df.info()
# 피쳐 추출
# 3일 평균선
df['MA3'] = np.round(df['Close'].rolling(window=3).mean(), 0)
df.head()
# 5일 평균선
df['MA5'] = np.round(df['Close'].rolling(window=5).mean(), 0)
df.head()
df['Mid'] = np.around((df['Open']+df['Close'])/2, 0)
df.head()
# Volume 값이 0인 데이터는 결측치 처리하기
df['Volume'] = df['Volume'].replace(0, np.nan)
X = df[['Open','High','Low', 'Volume','MA3','MA5','Mid']]
y = df['Close']
X_train = X.iloc[:int(len(X)*0.8)]
X_test = X.iloc[int(len(X)*0.8):]
y_train = y.iloc[:int(len(y)*0.8)]
y_test = y.iloc[int(len(y)*0.8):]
def make_sequence_dataset(X, y, window_size):
feature_list = []
label_list = []
for i in range(len(X)-window_size):
feature_list.append(X[i:i+window_size])
label_list.append(y[i+window_size])
return np.array(feature_list), np.array(label_list)
X_train = X_train.dropna()
y_train = y_train[X_train.index]
# 정규화
from sklearn.preprocessing import MinMaxScaler
x_scaler = MinMaxScaler()
X_train_s = x_scaler.fit_transform(X_train)
y_train_s = y_train / y_train.max()
X_train_s, y_train = make_sequence_dataset(X_train_s, y_train_s, 20)
from keras import layers
model = keras.Sequential([
layers.LSTM(units=32,activation = 'tanh',input_shape=(20,7)),
#layers.LSTM(units=512,activation = 'tanh'),
layers.Dense(1)
])
model.compile(loss='mse',optimizer =keras.optimizers.RMSprop(learning_rate=0.001), metrics=['mse'])
EPOCHS = 50
BATCH_SIZE = 32
history = model.fit(
X_train_s, y_train,
epochs = EPOCHS,
batch_size = BATCH_SIZE,
validation_split = 0.2,
verbose=1
)
X_test = X_test.dropna()
y_test = y_test[X_test.index]
X_test.shape, y_test.shape
X_test_s = x_scaler.transform(X_test)
y_test_s = y_test/y_test.max()
X_test_s, y_test_s = make_sequence_dataset(X_test_s, y_test, 20)
y_pred = model.predict(X_test_s)
y_pred_s = y_pred * y_test.max()
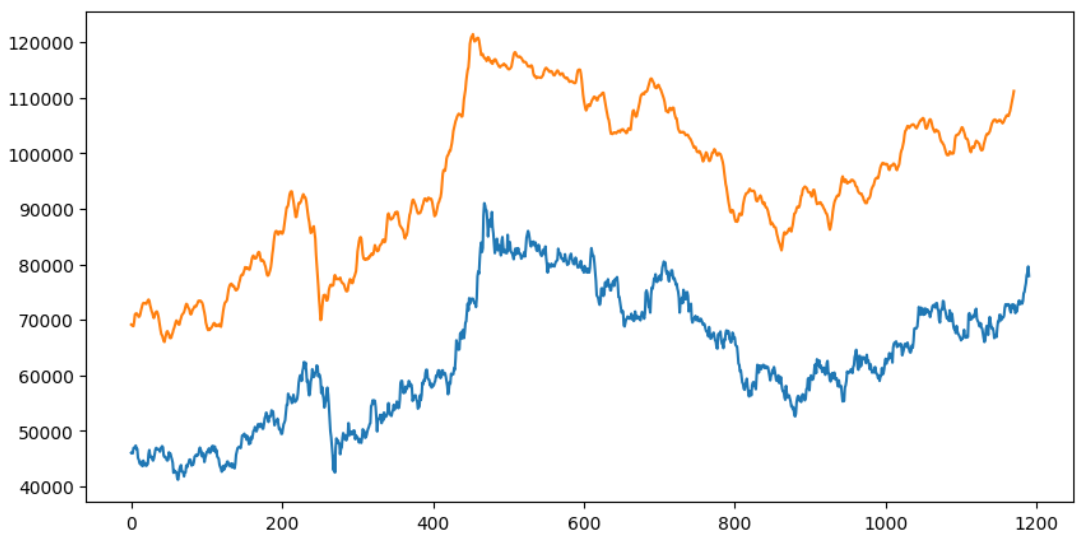
plt.figure(figsize=(10,5))
plt.plot(np.array(y_test), label='True')
plt.plot(y_pred_s, label = 'False')
plt.show()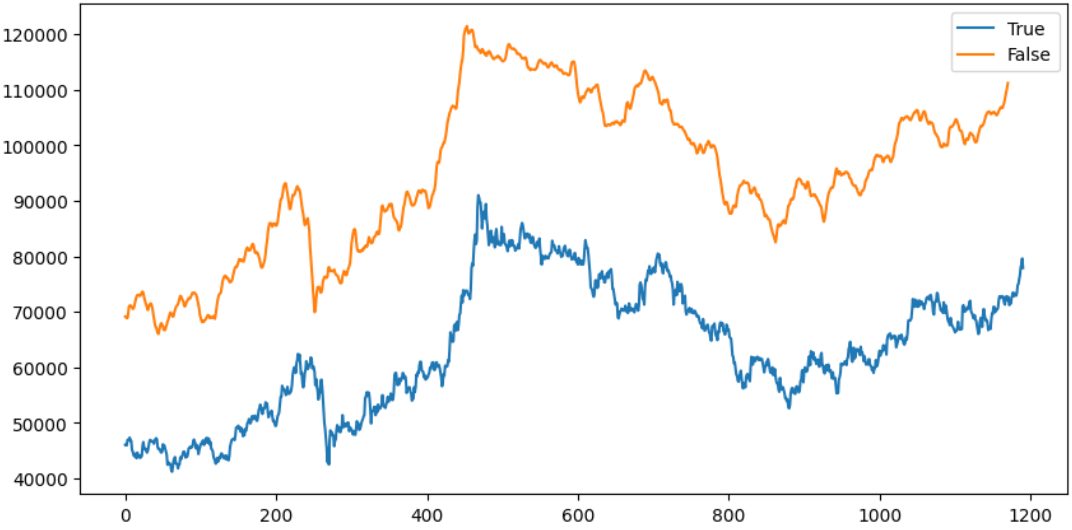
- 드디어 예측값이 어느 정도 개형을 따라가기 시작함
