
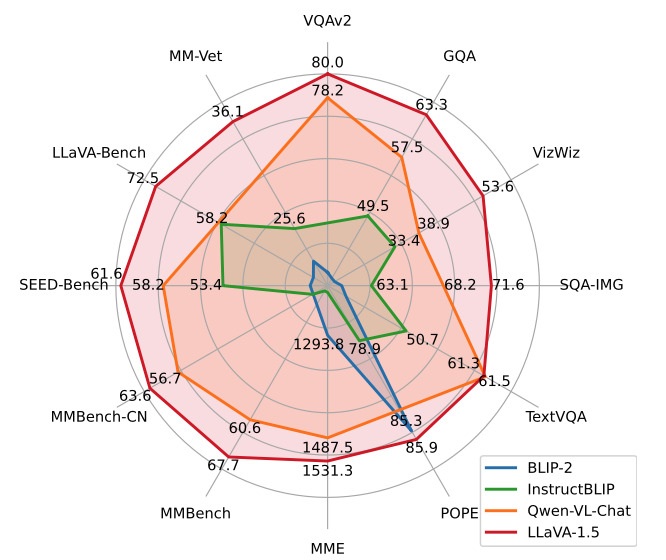
- LMM의 training에 대한 systematic study.
- multi-task learng과 LMMs scaling 사이의 balancing을 위한 effective approach.
LLaVa와의 차이점 정리
-
projection layer: two-layer MLP로 개선.
-
vision encoder
- input image resolution을 로 확대하여 LLM이 이미지의 세부 정보를 명확히 “볼 수 있도록”
CLIP-ViT-L-336px(현재 CLIP에서 가능한 최고 해상도)로 교체 - 아래 내용을 추가한게 "LLaVA-1.5-HD"
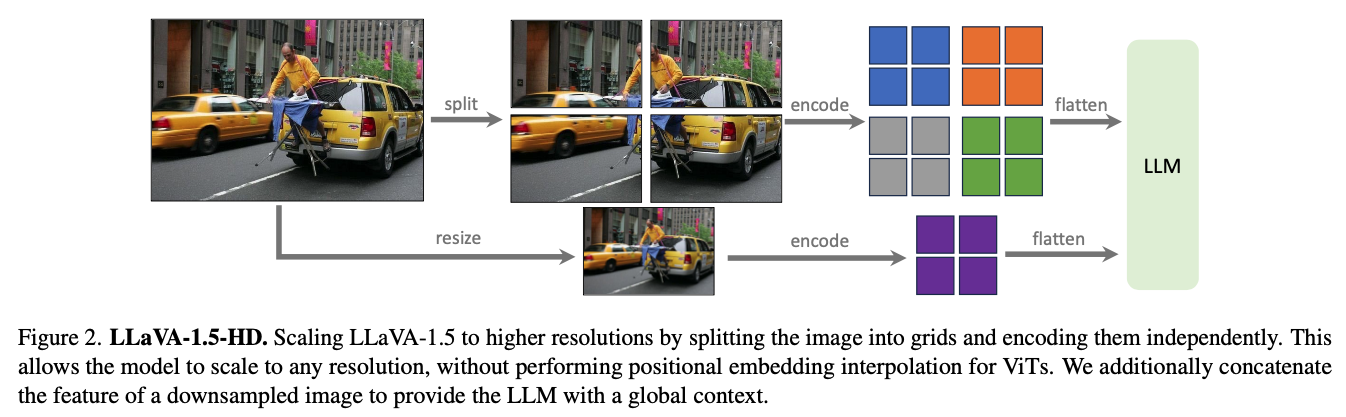
- vision encoder가 원래 학습된 resolution의 작은 image patches로 분할하여 독립적으로 encoding.
- LLM에 global context를 제공하고 split-encode-merge 작업에서 발생할 수 있는 인위적 오류(artifact)를 줄이기 위해, downsampling된 이미지의 feature를 추가적으로 concat.
- input image resolution을 로 확대하여 LLM이 이미지의 세부 정보를 명확히 “볼 수 있도록”
-
LLM: LLM의 크기를 13B로 확장
❗LLaVa 1.5 Limitation
-
high-resolution image 학습 시, 긴 학습 시간
- LLaVA-1.5는 전체 image patches를 활용하므로, 각 training iteration이 길어질 수 있음.
- Visual resamplers [3, 14, 32]는 LLM에서 visual patches의 수를 줄이지만, 유사한 양의 학습 데이터로 LLaVA만큼 효율적으로 수렴하지 못함.
- 이는 resamplers에 더 많은 trainable parameters가 있기 때문일 수 있음.
- sample-efficient visual resampler의 개발은 향후 instruction-following 멀티모달 모델의 확장에 기여 가능!
-
multiple-image 처리 불가.
-
특정 domain에서의 문제 해결 능력 부족.
- 더 강력한 language model과 고품질, 특정 분야에 맞춘 visual instruction tuning data가 필요함.
-
hallucinations을 완전히 피할 수는 없으므로, 의료와 같은 중요한 응용 분야에서는 주의가 필요
MLP cross-modal connector
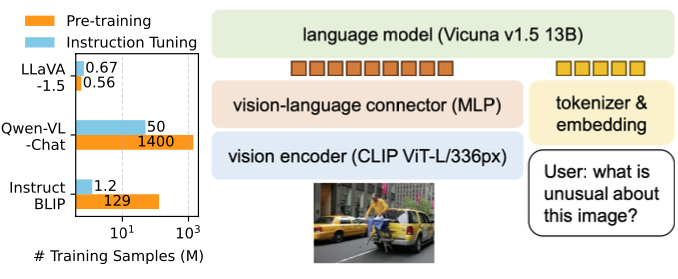
- LLaVA는 LMMs(Large Multimodal Models) 중 가장 단순한 아키텍처 디자인을 사용하며, 단지 600K 개의 image-text pair 데이터만으로 간단한 fully-connected projection layer를 학습
- (InstructBLIP [14] 또는 Qwen-VL [3]이 수억에서 수십억 개의 image-text pair 데이터를 사용해 특별히 설계된 visual resampler를 학습시키는 것과 대조적으로)
Approaches
Prompting
-
문제
- 단답형(short-form) 답변을 요구하는 academic benchmarks에서 부족한 성능.
- 학습 데이터 분포에 해당 데이터가 부족하여 yes/no 질문에 대해 'yes'로 답변하는 경향
-
접근
- VQA question prompt 뒤에다가 'Answer the question using a single word or phrase'를 붙임.
- 이렇게 수정된 prompt로 finetuning.

-
효과
- user's instruction에 따라 출력 형식을 조정 가능.
- VQA 답변을 ChatGPT로 추가 처리할 필요가 없어 다양한 데이터 소스로 확장하는 데 유리.
Scaling the Data and Model
MLP vision-language connector
- vision-language connector의 표현력(representation power)을 two-layer MLP로 개선
- Academic task oriented data
- 모델의 다양한 능력을 향상시키기 위해,
academic-task-oriented VQA datasets을 추가로 포함하여
VQA, OCR, 그리고 region-level perception에 대한 데이터를 학습에 사용
- 모델의 다양한 능력을 향상시키기 위해,
Additional scaling
- 입력 이미지 해상도를 336²로 확대하여 LLM이 이미지의 세부 정보를 명확히 “볼 수 있도록” vision encoder를 CLIP-ViT-L-336px(현재 CLIP에서 가능한 최고 해상도)로 교체
- LLM의 크기를 13B로 확장
Computational cost
- LLaVA-1.5는 pretraining dataset과 training iterations 및 batch size를 LLaVA와 거의 동일하게 유지.
- 그러나 입력 이미지 해상도가 336²로 증가함에 따라 LLaVA-1.5의 학습 시간은 LLaVA의 약 가 소요.
- 구체적으로, pretraining에 약 , visual instruction tuning에 약 이 필요하며, 이는 8× A100 GPUs를 사용한 결과
Scaling to Higher Resolutions
-
문제: input image resolution을 높이면 모델의 성능이 향상되지만,
현재 공개된 CLIP vision encoders의 해상도는 336²로 제한되어 있어,
단순히 vision encoder를 교체하는 방식으로는 더 높은 해상도 지원 불가. -
기존 방식:
ViT를 vision encoder로 사용할 때, resolution을 확장하기 위한 기존 접근법들은 주로 positional embedding interpolation을 수행하고,
ViT backbone을 새로운 resolution에 맞게 fine-tuning. -
기존 방식의 문제
- 대규모 image-text paired dataset으로 모델을 fine-tuning해야 함.
- inference 시 LMM이 fixed size의 image만 처리할 수 있도록 제한됨.
-
접근
-
-
vision encoder가 원래 학습된 resolution의 작은 image patches로 분할하여 독립적으로 encoding함으로써 문제를 극복.
-
개별 patch의 feature map을 얻은 후, 이를 목표 resolution의 하나의 큰 feature map으로 결합하여 LLM에 입력.
-
또한, LLM에 global context를 제공하고 split-encode-merge 작업에서 발생할 수 있는 인위적 오류(artifact)를 줄이기 위해, downsampling된 이미지의 feature를 추가적으로 concat.
-
-
효과
- 임의의 resolution으로 입력을 확장 가능
- LLaVA-1.5의 data efficiency를 유지
- 이렇게 얻은 모델을 LLaVA-1.5-HD라고 명명.
Delve into 🤿 Open problems of LMMs
-
Scaling to high-resolution image inputs
- LLaVA architecure는 image를 grid 형태로 분할하는 간단한 방식으로 high-resolution으로 확장할 수 있는 유연성을 가짐.
- resolution을 높임으로써 모델의 perception 능력이 향상되며, 특히 hallucination 현상이 감소하는 효과.
-
Compositional capabilities
- LMM은 compositional capabilities로의 generalization이 가능
- ex) long-form language reasoning과 short-form visual reasoning을 함께 학습할 경우, 모델의 멀티모달 질문에 대한 writing capability가 향상됨.
- Language capability in visual conversations:
ShareGPT [46] 데이터를 포함한 후, multimodal multilingual capability를 포함한 언어 능력이 향상.
visual conversations에서 더욱 긴 답변과 자세한 응답 제공 가능해짐.
-
Data efficiency
- LLaVA의 training data mixture에서 최대 75%까지 무작위로 downsampling해도 모델 성능에 큰 영향이 없음.
- 이를 통해, 더 sophisticated한 dataset compression strategy가 LLaVA의 효율적인 training pipeline을 더욱 향상할 수 있다는 가능성을 시사함.
- 50% downsampling
- 데이터셋을 50%로 downsampling할 경우, MMBench, ScienceQA, POPE에서 모델의 성능 저하가 전혀 없었으며, MMBench에서는 오히려 성능이 약간 향상.
- 데이터를 50%에서 30%까지 더 downscaling해도 모델의 성능은 안정적으로 유지되었습니다.
- 이러한 결과는 multi-modal 모델에서도 "less-is-more" [61] 효과가 가능성을 보임을 나타냄.
-
Data scaling
- 데이터 granularity의 scaling이 모델의 capability 향상에 중요한 역할.
- hallucination과 같은 artifacts를 도입하지 않고도 모델의 성능을 개선할 수 있음을 empirical evidence를 통해 입증함.
- 데이터 granularity의 scaling이 모델의 capability 향상에 중요한 역할.
Implementation Details
A.1 LLaVA-1.5-HD
pre-processing
- image encoder: CLIP-ViT-L-14 (224²)
- input image를 선택하고 target resolution에 맞게 padding한 후,
이를 224² 크기의 grids로 분할. - 각 224² 이미지 패치를 CLIP 이미지 인코더로 개별 encoding
- encodind된 feature들을 하나의 큰 feature map으로 병합.
- 최종 feature map은 flattened list로 변환되며, 추가적으로 global context를 제공하기 위해 고정된 해상도의 이미지 feature도 결합.
Target resolution selection
-
최대 6개의 grids(1x1, 1x2, 1x3, 1x4, 1x5, 1x6, 2x2, 2x3와 이들의 전치)를 지원하는 해상도 집합을 미리 정의
-
이는 최대 672x448 (또는 448x672) 해상도를 허용하며,
다음 기준을 따름. -
Detail preservation: 선택된 해상도가 원본 이미지의 세부 사항을 최대한 유지할 수 있도록 함.
-
Resource efficiency: 픽셀과 메모리 사용을 최소화하기 위해 불필요하게 큰 해상도(예: 224² 입력에 대해 448² 사용)를 선택하지 않음.
-
post-processing
- Padding removal
- padding에 해당하는 feature는 제거해
visual tokens 개수를 줄임.
- padding에 해당하는 feature는 제거해
- Row-end Tokens
- 각 row의 끝에 special token을 추가해, image shape에 대한 explicit indication을 제공.
- 이는 fixed resolution을 사용하는 LLaVA 및 LLaVA-1.5와 달리,
variable resolution을 사용하는 LLaVA-1.5-HD에서 이미지의 정확한 크기와 모양을 모델이 이해할 수 있도록 도움.
- Flattening
- 마지막으로 image feature map을 flatten하여 languagle token feature와 함께 language model에 입력.
A.2 Data
- 최종 학습 데이터 mixture는 아래의 데이터로 구성.
- VQA [19, 21, 41, 45],
- OCR [42, 47],
- region-level VQA [24, 25, 40],
- visual conversation [36],
- language conversation [46]
A.3 Hyperparameters
-
LLaVA-1.5: 최신 Vicuna v1.5 [60]를 기본 LLM으로 사용
-
기본적으로 original LLaVA와 동일한 하이퍼파라미터를 사용.

-
다만, MLP projection layer를 사용하기 때문에 pretraining에서 learning rate를 절반으로 줄임.
-
Table 9
- vision-language alignment pretraining(1단계)과
visual instruction tuning(2단계)의 training hyperparameter.
- vision-language alignment pretraining(1단계)과
-
evaluation에는 greedy decoding을 사용하여 재현성(reproducibility)을 보장
