
- LLaVa의 한계 (LLaVa 1.5에서 지적)
- 단답형(short-form) 답변을 요구하는 academic benchmarks에서 부족한 성능을 보이며,
- 학습 데이터 분포에 해당 데이터가 부족하여 yes/no 질문에 대해 'yes'로 답변하는 경향
-
architecture
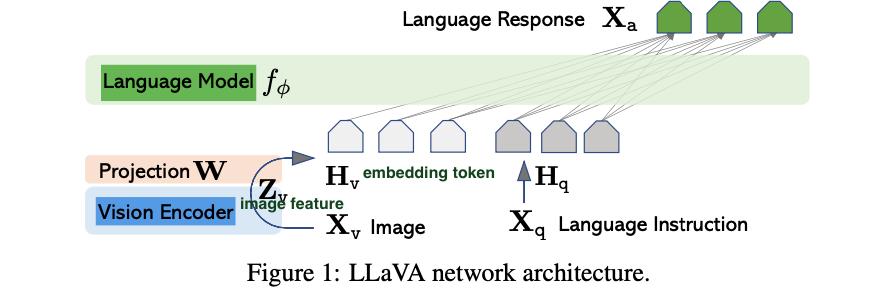
- LLM
- Vicuna
- VIsion Encoder
- pre-trained CLIP visual encoder ViT-L/14
- Linear layer
- image feature를 word embedding space로 projection.
- trainable projection matrix
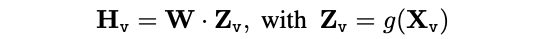
- language embedding tokens 는 word embedding space와 동일한 dimension을 가짐.
- LLM
-
LLaVA는 Linear layer로 image와 language representation을 연결,
Flamingo는 gated cross-attention,
BLIP-2는 Q-former를 사용함. -
in Training
- Stage 1: pre-training for feature alignment
- 목적: aligning image features
with the pre-trained LLM word embedding. - frozen ❄️: visual encoder weights, LLM weights
- update🔥: projection layer weights
- formula: maximize the likelihood of Eq(3) with trainable parameters
- Eq(3)


- Eq(3)
- 목적: aligning image features
- Stage 1: pre-training for feature alignment
- Stage 2: Fine-tuning End-to-End
- frozen ❄️: visual encoder
- update🔥: projection layer weights , LLM weights
- trainable parameters:
-
Benchmark: Science QA(mutimodal reasoning dataset)
-
Example

-
model training에 사용된 input sequence

- 예시에선 2개의 conversation turn가 묘사됨.
- 실전에서는, instruction-following data에 기반해 turn 개수가 vary함.
- system message settint은 Vicuna-v0를 따랐고,
<STOP> = ### 으로 setting. - model은 assistant answers를 prediction하고,
어디에서 stop할지를 train함. - 따라서, auto-regressive model에서,
오직 만 loss 계산에 사용됨.
