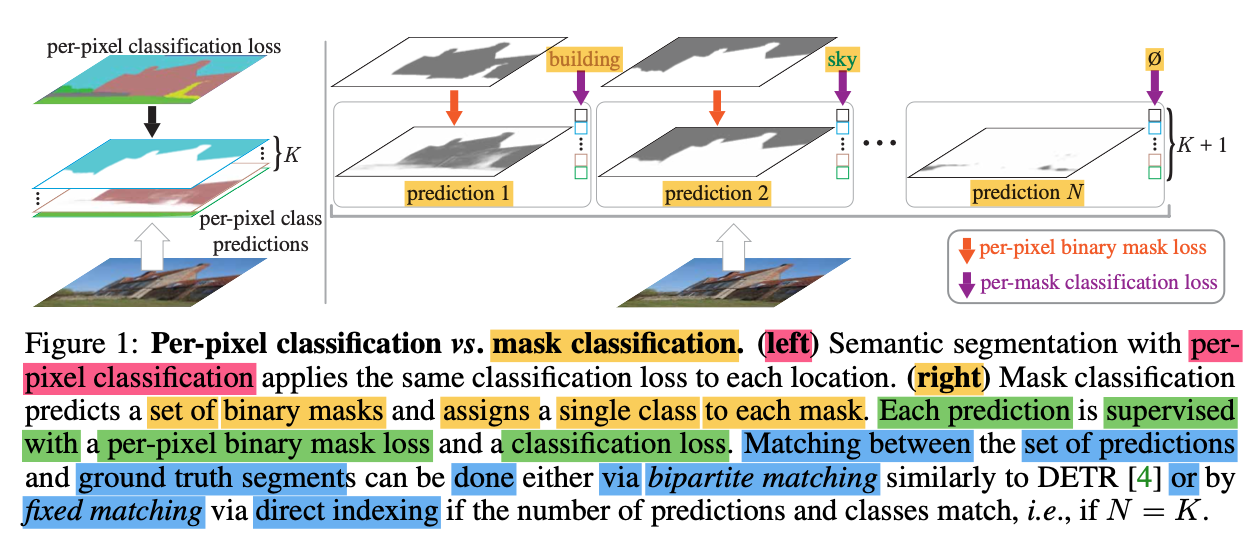
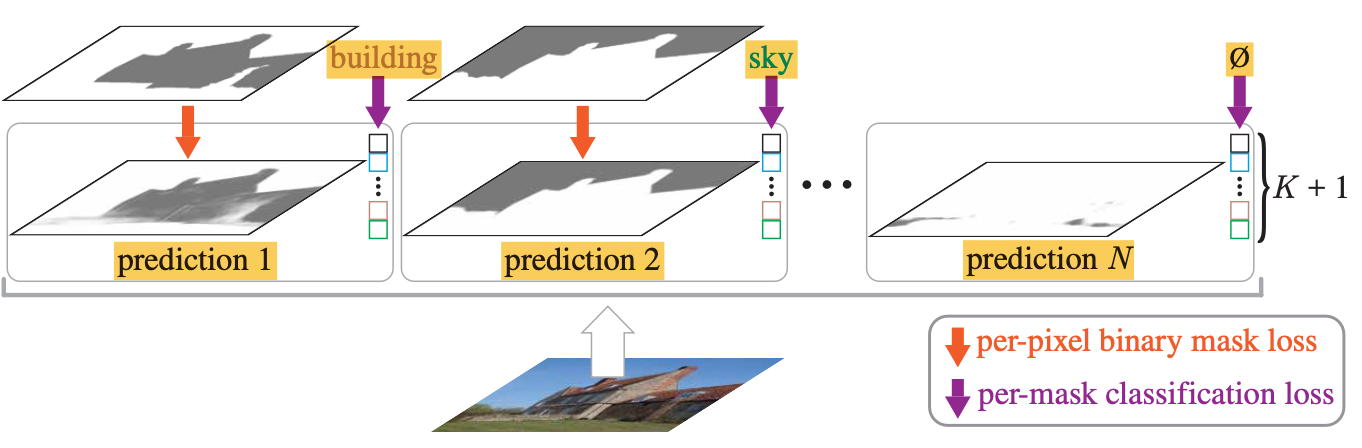
Per-Pixel Classification vs Mask Classification
Per-pixel classification
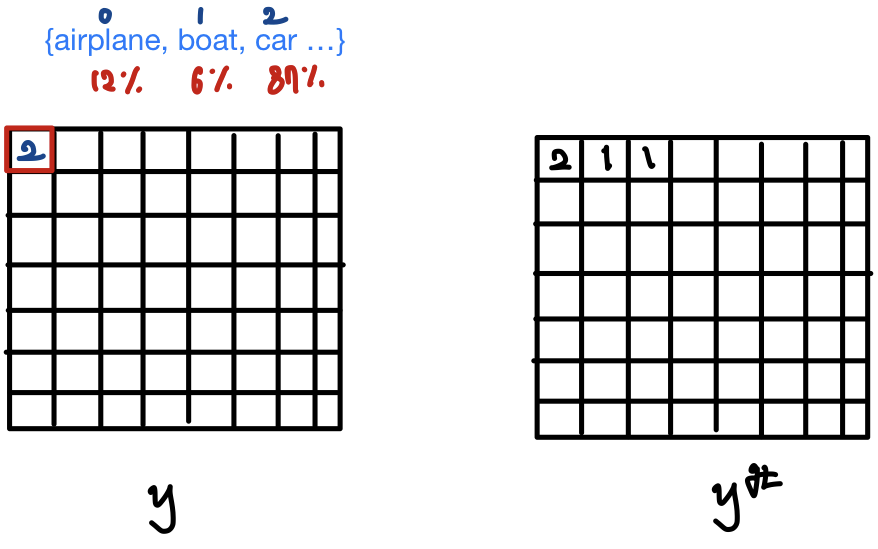
모든 pixel들에 대해 K개의 카테고리들에 속할 확률 분포를 예측한다.
만약, image가 있다고 한다면, 가 K개 차원의 확률 분포라고 할 때,
예측값 를 예측한다.
그리고, 모든 pixel의 Ground Truth 카테고리 Label인 와, 예측 값인 간의 cross-entropy loss를 주로 사용해 loss를 계산해 모델 학습을 진행한다.
Mask Classification
Mask Classification은 두 단계로 이루어진다.
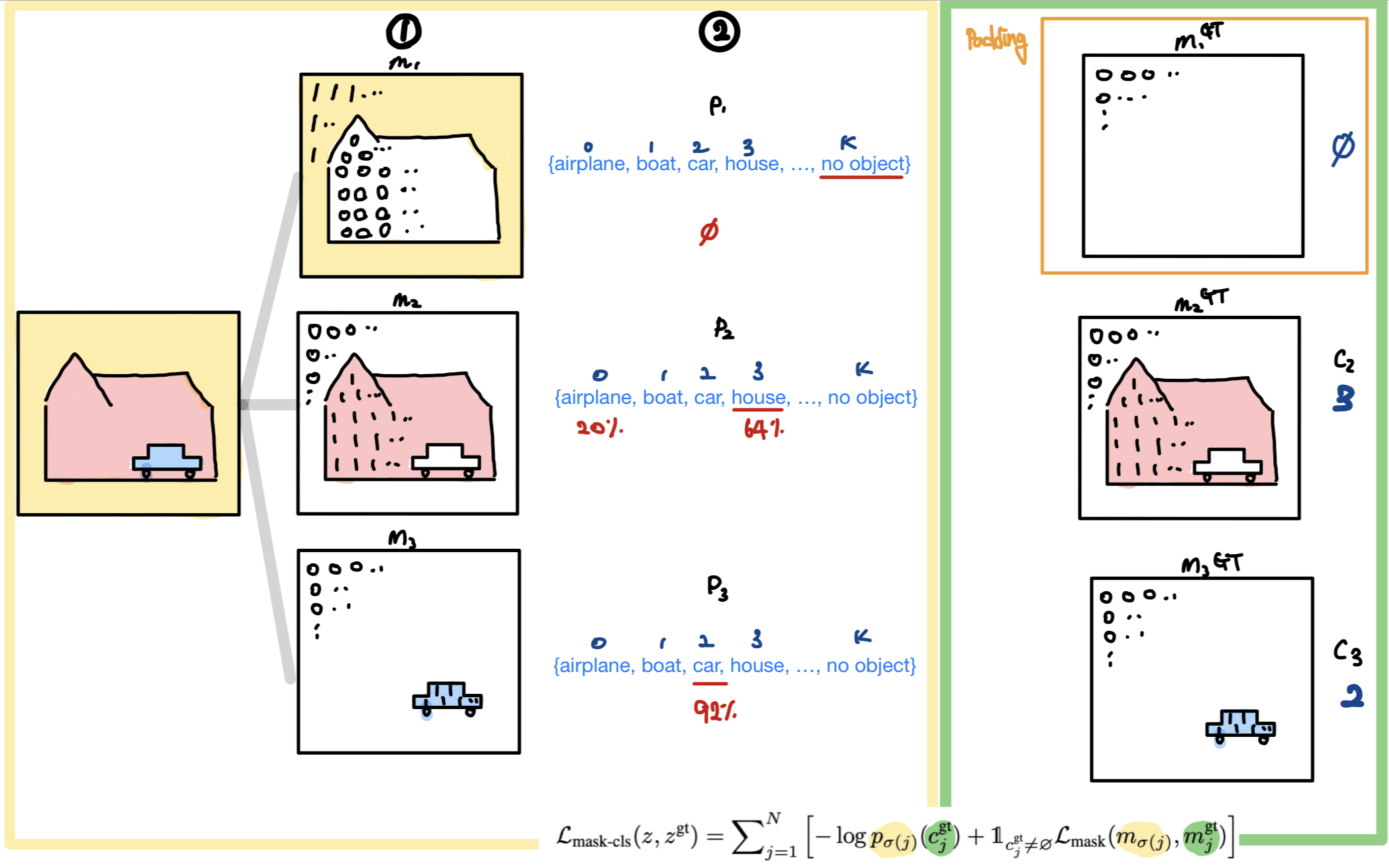
1) 먼저, 각 image를 개의 segments로 나눈다.
각 segments는 binary mask로 표현된다.
따라서, 결과적으로 개의 mask가 생긴다.
(이때, 은 전체 카테고리 개수 와 같을 필요는 없다.)
2) 각 segment, 즉 각 개의 mask가 어떤 카테고리에 속하는지, 각 개의 카테고리에 관해 확률 분포를 예측한다.
결과적으로 개의 probability-mask 쌍인 예측값 를 예측한다.
()
참고로, per-pixel classification과 또 다른 점은,
은 개의 카테고리 label 외에,
"no object" label()도 포함한다는 점이다.
그래서 어떠한 K개의 카테고리에도 대응되지 않는 mask에는 label로 예측한다.
Ground Truth 값인 와
예측 값인 사이의 loss를 계산해 모델 학습을 진행한다.
(: 번째 segment의 ground truth class}
예측 set 의 크기 과, GT set 의 크기 가 보통 다르므로,
로 가정하고,
GT set 의 label을 "no object"로 padding하여 1 대 1 매칭이 가능하도록 만든다.
✅ 참고로, 각 개의 mask와 개의 category label을 match하기 위해서,
MaskFormer에서는 fixed matching 대신 bipartite matching을 사용했으며,
이 matching을 기반으로 모델의 파라미터를 학습시키기 위한
각 segment에 대한 main mask classification loss 는
cross-entropy classification loss와 binary mask loss 로 구성된다.
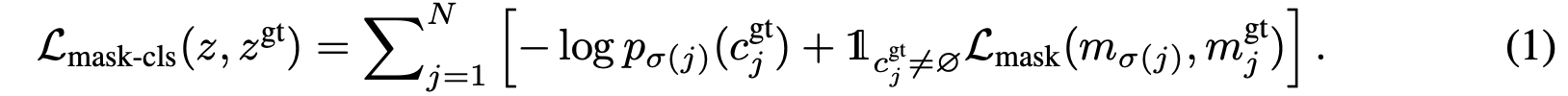
Mask Former
기존의 semantic segmentation task에서는 각 pixel마다 이 pixel이 속하는 class를 예측하는 방식의 "per-pixel classification" 방식이 주로 사용됐다.
반면, instance segmentation task에서는 mask 주로 classification 방식이 사용됐다. (e.g. Mask R-CNN, DETR)
하지만, 2021년 Facebook AI Research 팀은 논문 "Per-Pixel Classification is Not All You Need (Bowen Cheng et al)"에서, Mask Classification 방식은 semantic segmentation과 instance segmentation에 모두 general하게 사용될 수 있음을 발표했다. MaskFormer는 어떤 per-pixel classification 모델도 mask classification model로 쉽게 변환할 수 있기 때문이다.
Prediction Pipeline
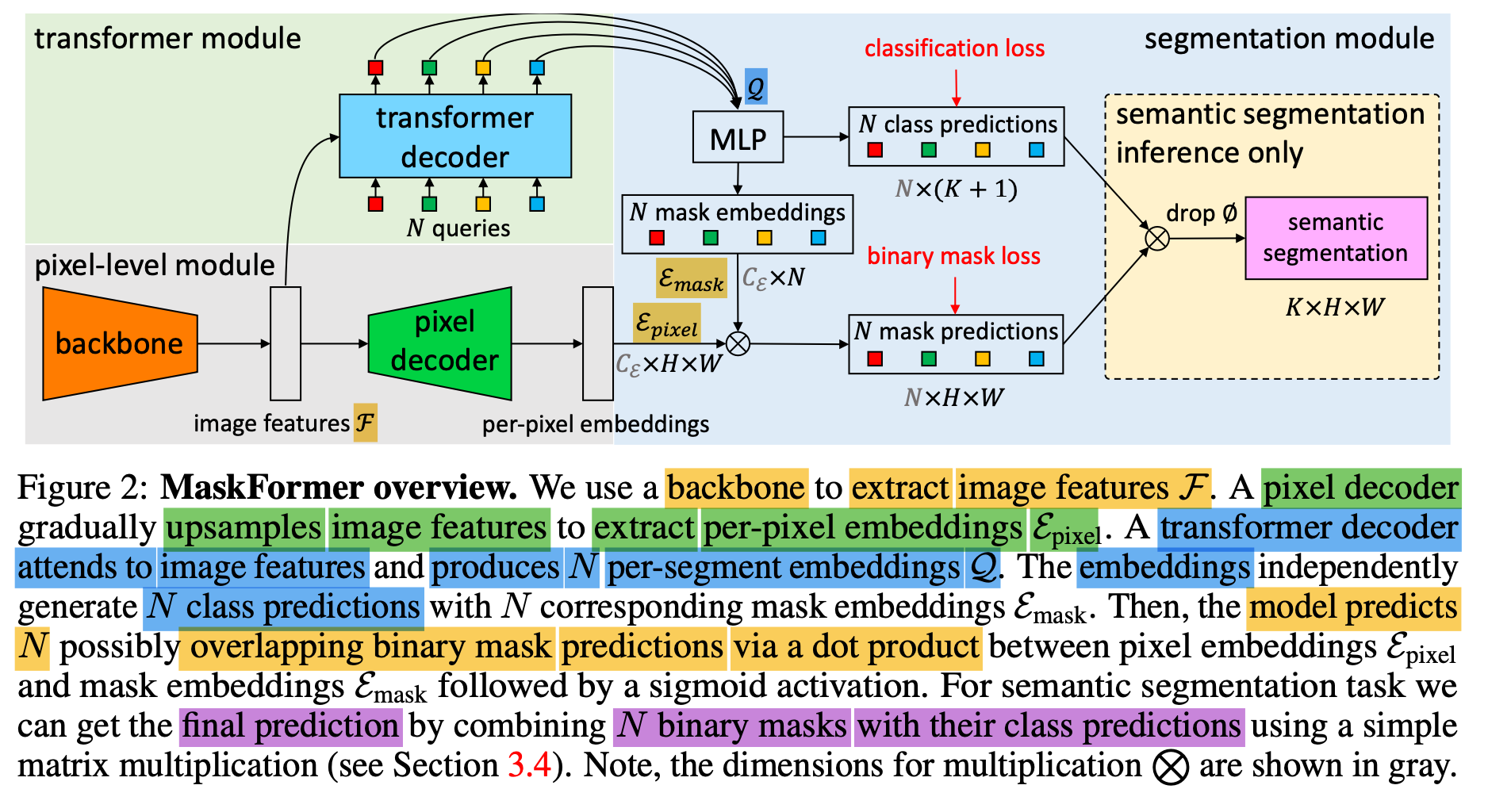
MaskFormer는 크게 세 가지 모듈로 구성돼있다.
첫 번째는, pixel-level module로 per-pixel embedding을 추출한다.
두 번째는, transformer module로 Trasnformer decoder layer들이 개의 per-segment embedding을 계산한다.
마지막으로 segmentation module에서는 per-pixel embedding과 per-segment embedding으로부터 개의 probability-mask pairs 를 예측한다.
1) Per-pixel module
input: image of size
output: per-pixel embeddings
backbone
extract low-resolution image feature map
(: num of channels = , : stride of the feature map)
( depends on the specific backbone, and MaskFormer use )
Implementation Details
MaskFormer는 Backbone으로 Convolution-based ResNet과
Transformer-based Swin-Transformer를 사용했다.
pixel decoder
low-resolution image features 를 upsampling 하여,
per-pixel embeddings 를 출력한다.
(: embedding dimension = 256)
'Implementation Details'
MaskFormer의 pixel decoder는 FPN[26] architecture를 기반으로 한다.
FPS의 구조에 따라, low-resolution feature map을 2배 upsampling 하고,
이 upsampling된 feature map을
'대응되는 resolution을 가진 projection된 feature map'에 더한다.
여기서 Projection은 1 x 1 convolution layer와 GN(Group Norm)을 사용해,
feature map의 channel dimension을 맞추기 위함이다.
upsampling한 feature map과 projection된 feature map을 sum한
summed feature를 3 x 3 convolution layer와 GN, ReLU 함수를 통과시킨다.
이 과정을 feature map of stride 32가 최종 feature map of stride 4이 될 때까지 반복한다.
최종적으로, 1 x 1 convolution layer를 사용해 per-pixel embeddings를 얻는다.2) Transformer module
transformer decoder
image features 에 attention하여,
per-segment embeddings을 만든다.
이때, image feature 와 개의 positional embeddings (i.e. queries)로부터
개의 per-segment embeddings인 를 계산한다.
per-segment embedding은, MaskFormer가 예측한 각 segment에 대한 global한 정보를 encoding하고 있다.
MaskFormer가 Transformer decoder를 사용하는 것은,
DETR에서 제안된 set prediction mechanism을 활용해,
class prediction과 mask embedding vector로 구성된 pair들의 set을 계산하기 위함이다.
Implementation Detail
DETR에서 사용한 Transformer decodr 디자인을 동일하게 사용했다.
$N$ 개의 query embeddings는 zero vector로 initialized되고,
leanrnable positional encoding을 각 query에 연관시켰다.
6개의 Transformer decoder layer와 100 개의 queries를 사용했고,
DETR과 같이 각 decoder에 동일한 loss를 적용했다.
semantic segmentation에서는 single decoder layer로도 충분했고,
instance segmentation에서는 중복을 제거하기 위해 multiple layer가 필요함을
실험을 통해 알 수 있었다고 한다.
3) Segmentation module
per-segment embeddings 에 linear classifier와 함께 softmax 함수를 적용해,
각 segement에 대한 class probability 예측값 을 예측한다.
Mask prediction을 위해서, MLP(with 2 hidden layers)가 per-segment embeddings 를
개의 mask embeddings 로 변환한다.
최종적으로, mask embedding과 per-pixel embedding 간에 dot product와 sigmoid 함수를 이용해,
각 binary mask prediction 를 예측한다.
⭐
Implementation Details
256 채널의 2개의 hidden layer를 가진 MLP가 사용됐다.
이 MLP는 mask embedding $Ɛ_{mask}$를 예측하며,
$Ɛ_{pixel}$ 과 $Ɛ_{mask}$ 모두 256 채널을 가진다.4) Loss
mask loss로는 focal loss와 dice loss를 사용했다.
( , )
DETR과 같이, classification loss에서 no object는 0.1로 설정.
Mask-classification Inference
mask classification ouput인 을 semantic segmentation output 형식으로 변환하는지에 대해 알아보자.
Pixels to Segments
image의 각 pixel에 개의 예측 probability-mask pairs 중 하나에 할당해, image를 segment들로 나눈다(partitioning).
할당에는 다음 수식을 이용한다.
여기서
는 각 probability-mask pair 에 대해 가장 확률이 높은 class label
즉, 이므로,
는 "가장 확률이 높은 class label의 확률"이고,
는 예측 binary mask, ⭐ 이다.
즉, 가장 가 높은 pair의 index를 할당받는 것이다.
직관적으로 이 과정을 요약해보면,
[h,w] 위치에 있는 각 pixel에
class probability 와 mask prediction probability 가 모두 높은
probability-mask pair 를 할당하는 것이다.
For semantic segmentation,
동일한 category label을 갖는 segment들은 동일한 그룹으로 묶인다.
For instance segmentation,
probability-mask pari의 index 가 동일한 class 사이에서 instance를 구별하는데 사용된다.
MaskFormer에서는, 낮은 confidence prediction들은 inference 전에 모두 필터링해서 버리고,
50 % 이상 다른 prediction에 의해 occluded된 예측 segment들(도 제거한다.
