Mask3D: Mask Transformer for 3D Semantic Instance Segmentation
🚀 Motivation
-
Modern 3D semantic instance segmentation approaches
predominantly rely on
specialized "voting mechanisms"
followed by carefully designed geometric clustering techniques. -
Author observes a strong shift from
ubiquitous CNN architectures
towards Transformer-based models[6, 11, 33]. -
In 3D, the move towards Transformer is less pronounced
with only a few methods focusing on
3D object detetction or 3D semantic segmentation
and no methods for 3D instance segmentation -
Overall, these approaches are still behind
in terms of performacne
compared to current SOTA methods.
-
Building on the success of recent Transformer-based methods
for object detection and image segmentaion,
✅ paper proposes the first Transformer-based approach
for 3D semantic segmentation. -
Main Challenge: directly predicting
instance masks & their corresponding semantic labels. -
To this end,
model predicts instance queries
that encode semantic and geometric info of each instance in the scene. -
Each instance query is then
decoded into a semantic class and an instance feature -
Key idea to directly generate masks
: compute similarity scores between
"individual instance features"
&
"all point features" in the pont cloud
🔽
This results in a heatmap over the point cloud,
which (after normazization and thresholding) yields the final binary instance mask

-
Mask3D builds on recent advances in both
Transformers [5,37] & 3D deep learning [8, 17, 57]:
👨🏻🏫 to compute strong point features, leverage a sparse convolutional feature backbone [8]
(that efficiently processes full scenes
and naturally provides multi-scale point features.)
Trasnformer
[5] MaskFormer2, [37] 3DETR
3D Deep Learning
[8] 4D Spatio- Temporal ConvNets: Minkowski Convolutional Neural Networks
[17] Submanifold Sparse Convolutional Networks
[57]O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis
- To generate instance queries,
rely on stacked Transformer decoders [5,6]
that iteratively attend to "learned point features"
in a coarse-to-fine fashoin
using non-parametric queries [37].
- Unlike voting-based methods,
directly predicting and supervising masks
causes challenges during training:
before computing a mask loss,
have to establish correspondences between
predicted & annotated masks.
🔽
Paper performs "bipartite graph matching"
to obtain optimal associations
between GT and predicted masks [2, 61]
🔑 Key contributions
-
First competitive Transformer-based model
for 3D semantic instance segmentation -
Mask3D is based on Transformer decoders,
and learns instance queries that,
combined with "learned point features",
directly predict semantic instance masks
'
without the need for
hand-selected voting schemes
or
hand-crafted grouping mechainsms. -
Mask3D builds on domain-agnostic components,
avoiding center voting, non-maximum suppression, or grouping heuristics,
and overall requires less hand-tuning. -
Mask3D achieves SOTA performance on
ScanNet, ScanNet200, S3DIS and STPLS3D.
👪 Related works
Transformers
-
Initially [55] for NLP
-
Revolutionized the field of CV
as ViT[11] for image classification,
DETR[2] for 2D object detection,
Mask2Former [5,6] for 2D segmentation tasks. -
Success of Transformers has been less prominent in the 3D point cloud domain
though recent focus on either 3D object detection [34,37,39]
or 3D semantic segmentation[29, 40, 63] -
[29] Xin Lai, Jianhui Liu, Li Jiang, Liwei Wang, Hengshuang Zhao, Shu Liu, Xiaojuan Qi, and Jiaya Jia. **Stratified Transformer for 3D Point Cloud Segmentation**. In IEEE Conference on Computer Vision and Pattern Recognition, 2022. -
[40] Chunghyun Park, Yoonwoo Jeong, Minsu Cho, and Jaesik Park. **Fast Point Transformer**. In IEEE Conference on Computer Vision and Pattern Recognition, 2022. -
[63] Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip HS Torr, and Vladlen Koltun. **Point Transformer**. In International Conference on Computer Vision, 2021.
⭐ Methods
-
✅ Leverage generic Transformer building blocks
to directly predict instance masks
from 3D point clouds. -
In Mask3D,
each object instance is represented as an instance query -
Using Transformer decoders,
instance queries are learned by
iteratively attending to point cloud features
at multiple scales. -
Combined with point features,
instance queries directly yield all instance masks
in parallel.
Architecture
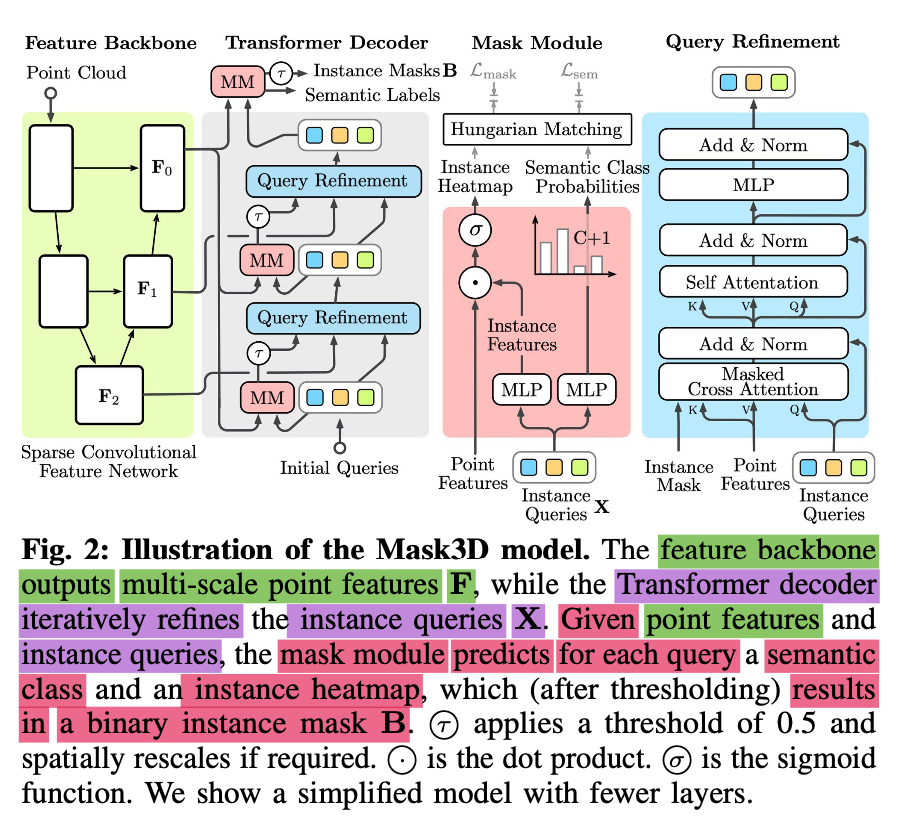
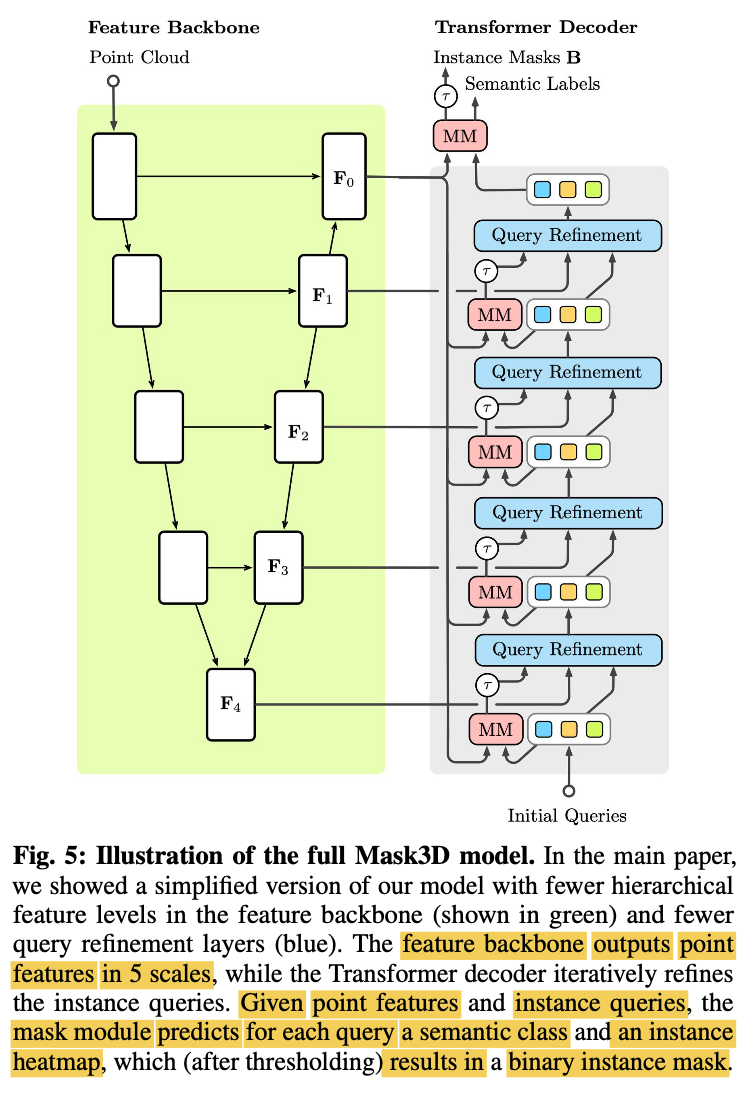
Overview
- Mask2Former includes
a feature backbone,
a Transformer decoder (built from mask modules),
Transformer decoder layers (usde for query refinement)
- Instance Queries are at the core of the model,
which each should represent one object instance in the scene
and predict the corresponding point-level instance mask.
-
To that end,
intance queries are iteratively refined
by the Transformer decoder
which allows the instance queries to cross-attend
to point features extracted from the feature backbone
and self-attend the other instance queries. -
This process is repeated for multiple iterations and feature scales,
yielding the final set of refined instance queries. -
Mask Module predicts for each query
a semantic class and an instance heatpmap,
which (after thresholding) results in a binary instance mask B.
Sparse Feature Backbone
-
Use sparse convolutional U-net backbone
with a symmetrical encoder and decoder,
based on the MinkowskiEngine [8]. -
Input: colored point cloud P of size N
☑️ P ∈ ℝ ^ (Nx6) -
Output: Feature maps Fr
F0 = Full-resolution feature map,
Fr = Coarser(finer) feature map
☑️ Fr ∈ ℝ ^ (Mr x D) -
P is quantized into M0 voxels V,
where each voxel is assigned
the average RGB color of the points within that voxel
as its initial feature.
☑️ V ∈ ℝ ^ (M0 x 3) -
Next to the full-resolution output feature map F0
, also extract a multi-resolution hierarchy of features
from the backbone decoder
before upsampling to the next finer feature map.
☑️ F0 ∈ ℝ ^ (M0 x D) -
At each of these resolution r >= 0
we can extract features for a set of Mr voxels,
which we linearly project to a fixed and common dimension D,
yielding feature matrices Fr
☑️ Fr ∈ ℝ ^ (Mr x D) -
Let queries attend to features
from coarser feature maps
of the backbone decodder, (i.e. r >= 1),
and
use the full-resolution feature map (r=0)
to compute auxiliary and final per-voxel instance masks.
Mask Module(MM)
-
Input: set of K instance queries X
☑️ X ∈ ℝ ^ (K x D) -
Output: Instance masks B
☑️ B ∈ {0, 1} ^ (M x K) -
Given X,
Predict a binary mask for each instance
and
classify each of them as one of C classes or as being inactive. -
To create the binary mask,
map the instance queriees through an MLP fmask(⋅),
to the same feature space
as the backbone output features. -
Then compute the dot product
between these instance features
and the backbone features F0. -
Resulting similarity scores
are fed through a sigmoid σ
and threshold at 0.5,
✅ yielding the final binary mask B ∈ {0, 1} ^ (M x K):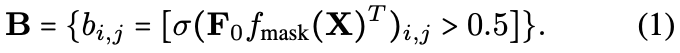
-
👨🏻🏫 Paper applys the mask module to the
refined queries X
at each Transformer layer
using the full-resolution feature map F0,
to create auxiliary binary masks
for the masked corss-attention of the following refinement step. -
When this mask is used as input
for the masked cross-attention,
paper reduces the resolution
according to the voxel feature resolution
by average pooling. -
Next to the binary mask,
paper predics a single semantic class "per instance". -
This step is done via a linear projection layer
into C + 1 dimenstions,
followed by a softmax. -
While prior work [4, 13, 56] typically needs
to obtain the semantic label of instance
via majority voting or grouping
over per-point predicted semantics,
'
this information is directly contained in the refined instance queries.
Query Refinement
- Transformer decoder starts with K instance queries,
and refines them
through a stack of L Transformer decoder layers
to a final set of instance queries (accurate, scene specific)
by
cross-attending to scene features,
& reasoning at the instance-level through self-attention
Cross-Attention Step
-
Each layer attends to one of the feature maps
from the feature back bone
using standard cross-attention:
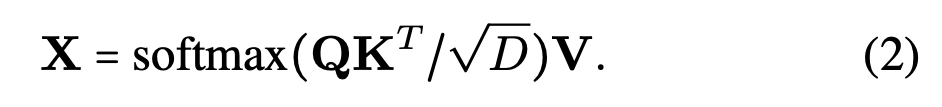
-
To do so,
voxel features Fr
are first linearly projected to
a set of keys and values
of fixed dimensionality K, V -
And our K instance queries X
are linearly projected to the queries Q. -
This cross-attention
allows the queries to extract information
from the voxel features
Self-Attention Step
-
Cross-attention is followed by a
self-attention step between queries,
where the keys, values, and queries are all computed
based on linear projections of the instance queries. -
Without such inter-query communications,
model could not avoid multiple instance queries
latching onto the same object,
resulting in duplicate instance masks.
Positional Encodings
-
Similar to most Transformer-based approaches,
paper uses positional encodings for keys and queries. -
Paper uses Fourier positinal encoding[52] based on voxel positions)
-
Add the resulting positional encodings
to their respective keys
before computing the cross-attention. -
All instance queries are also assigned a fixed positional embedding,
that is not updated throughout the query refinement process. -
These prositional encodings are added
to the resepective queries
in the cross-attention,
as well as to bothe the keys and queries in the self-attention.
Masked variant cross-attention
-
Instead of using the vanilla cross-attention
(where each query attends to all voxel features in one resolution),
'
paper uses a masked variant
(where each instance query only attends to the voxels
within its corresponding intermediate instance mask B
predicted by the previous layer) -
This is realized by adding -∞ to the attention matrix
to all voxels for which the mask is 0.
✅ Eq.2 then becomes Eq.3:
🔽
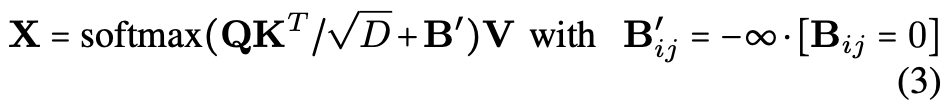
-
Likely reason is that the Trasnformer does not need to learn
to focus on a specific instance
instead of irrelevant context,
but is forced to do so by design.
-
In practice, paper attends to
the 4 coarset levels of the feature backbone,
from coarse to fine,
&
do this a total of 3 times,
🔽
resulting in L = 12 query refinement steps. -
Transformer decoder layers
share weights for all 3 iterations. -
Early experiments showed that
this approach preservers the performance
while keeping memory requirements in bound.
Sampled Cross-Attention
-
Point clouds in a training batch
typically have different point counts. -
While MinkowskiEngine can handle this,
current Transformer implemnetations rely on
a fixed number of points
in each batch entry. -
In order to leverage well-tested Transformer implementations,
paper proposes to pad the voxel features
and mask out the attention where needed. -
In case the number of voxels exceeds a certain threshold,
we resort to sampling voxel features. -
To allow instances to have access to all voxel features
during cross-attention,
paper resamples the voxels
in each Transformer decoder layer though,
and use all voxels during inference.
✅ This can be seen as a form of dropout[50] -
In practice, this procedure
saves significant amounts of memory
& is crucial for obtaining competitive performance. -
In particular, since the proposed sampled cross-attention
requires less memory,
it enables training on higher-resolution voxel grids
which is necessary for achieving competitive results
on common benchmarks
(e.g., 2cm voxel side-length on ScanNet[9]).
Training & Implementation Details
Correspondences
-
Given there is no ordering
to the set of instances in a scene & the set of predicted instances,
We need to establish correspondences
between two sets during training. -
To that end, Paper uses bipartite graph matching.
(It has become more common in Transformer-based approaches[2,5,6]) -
Construct a cost matrix C
☑️ C ∈ ℝ^(K x Khat)
where Khat: number of GT instnacens in a scene. -
Matching cost
for a predicted instance k & a target instance k hat
is given by:
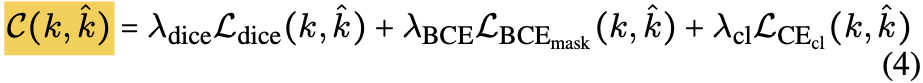
(Paper sets the weights to)
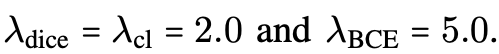
-
Optimal solution for this cost assignment problem
is efficiently found using the Hungarian method[27]. -
After establishing the correspondences,
we can directly optimize each predicted mask
as follows:
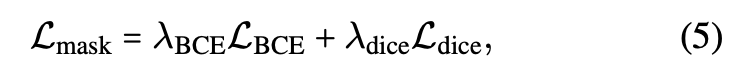
LBCE: binary cross-entropy loss (over the FG and BG of the mask)
Ldice: Dice loss [10]
LCEcl: deault multi-class cross-entropy loss (to supervise the classification) -
If a mask is left unassigned,
we seek to maximize the associated no-object class,
for which the LCEcl loss is weighted by an additional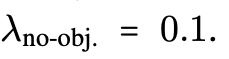
-
✅ Overall loss for all auxiliary instance predictions
after each of the L layers is defined as:
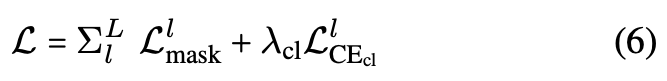
Prediction Confidence Score
-
Paper seeks to assign a confidence
to each predicted instances. -
While other existing methods require a dedictaed ScoreNet[26]
which is trained to estimate the IoU
with GT instances, -
Paper directly obtain the confidence scores
from the refined query features & point features
as in Mask2Former[5]. -
First select the queries
with a dominant semantic class,
for which we obtain the class confidence based on the softmax output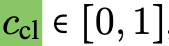
,
which we additionally multiply with a mask based confidence:
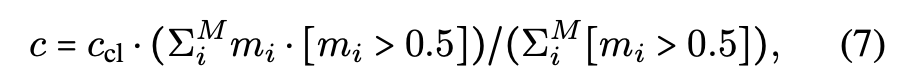
(where mi ∈ [0, 1] : instance mask confidence
for the ith voxel
given a single query) -
In essence, this is the mean mask confidence of all voxels
falling inside of the binarized mask [5] -
For an instance prediction to have a high confidence,
it need both a confident classification among C classes,
and a mask that predominantly consists of high-confidence voxels.
Query Types
Other Methods using "parametric queries"
- Methods like DETR[2] or Mask2Former[5, 6]
use parametric queries.
'
During training, both the "instance features" and the "corresponding positional encodings" are learned.
'
This thus measn that during training,
the set of K instance queries has to be optimized
in such way
that it can cover all instances present in a scene
during inference.
using "non-parametric queries"
-
Misra et al.[37] propose to initialize queries
with sampled point coordinates
from the input point cloud
based on farthest point sampling.
'
Since this initialization does not involve learned parameters,
they are called non-parametric queries. -
Interestingly, instance query features are initialized with zeros
and only the 3D position of the sampled points is used
to set the corresponding positional encoding. -
Paper uses sampled point features as
instance query features.
&
observe improved performance
when using non-parametric queries (similar to [37])
although less pronounced -
Key advantage of non-parametric queries is that
during inference,
we can sample a different number of queries
than during training. -
This provides a trade-off
between inference speed and performance,
w.o. need to retrain model
when using more instance queries.
Training Details.
-
Feature backbone: Minkowski Res16UNet34C [8]
-
Train for 600 epochs using AdamW [35]
-
One-cycle learning rate schedule [49] with a
max learning rate of 10^(-4). -
Longer training times (1000 epochs) didn't further imporve results.
-
One training on 2cm voxelization takes ~78 hours
on a NVIDIA A40 GPU. -
Perform standard data augmentation:
horizontal fliping,
random rotations around z-axis,
elastic distortion [46]
and random scaling. -
Color augmentations include
jittering, brightness and contrast augmentations. -
During training on ScanNet,
reduce memory consumption
by computing the dot product
between instance queries and aggregated point fetures within segments.
👨🏻🔬 Experiments
Comparing with SOTA Methods
Datasets and Metrics
-
Evaluate Mask3D
on 4 publicly available 3D instance segmentation datasets. -
1️⃣ ScanNet
1) richly-annotated dataset of 3D reconstructed indoor scenes.
2) conains hundreds of different rooms
showing a large variety of room types such as hotels, libraries and offices.
3) provided spilts contain 1202 training, 312 valudation, 100 hidden test sceces.
4) Each scene is annotated with semantic and instance segmt lables covering 18 object categories.
5) Benchmark evaluation metric: mAP -
2️⃣ ScanNet200
1) extends the original ScanNet scenes
with an order of magnitude more classes.
2) allows to test an algorithm's performance
under the natural imbalance of classes,
particulary for challenging long-tail classes
such as coffee-kettle and potted-plant. -
3️⃣ S3DIS
1) large scale indoor dataset
showing 6 different areas
from 3 diffrernt campus buildings.
2) Contains 272 scans
and annotated with semantic instance masks
over 13 different calsses.
3) paper follows the common splits
and evaluate on Area-5 and 6-fold cross validation.
4) paper reposrts scores using the mAP metric from Scan Net
and mean precision/recall at IoU threshold 50% (mPrec50 / mRec50)
as initially introduced by ASIS[59]
5) Unlike AP, this metric does not consider confidence scores,
therefore we filter out instance masks with a prediction confidence score bloew 80%
to avoid excessive false positives.
- 4️⃣ STPLS3D
1) synthetic outdoor dataset
closely mimiking the data generation process
of aerial photogrammetry point clouds.
2) 25 urban cenes totalling 6 km^2
are densely annotated with 14 instance classes.
3) paper follows the common splits [3,56].
Results
-
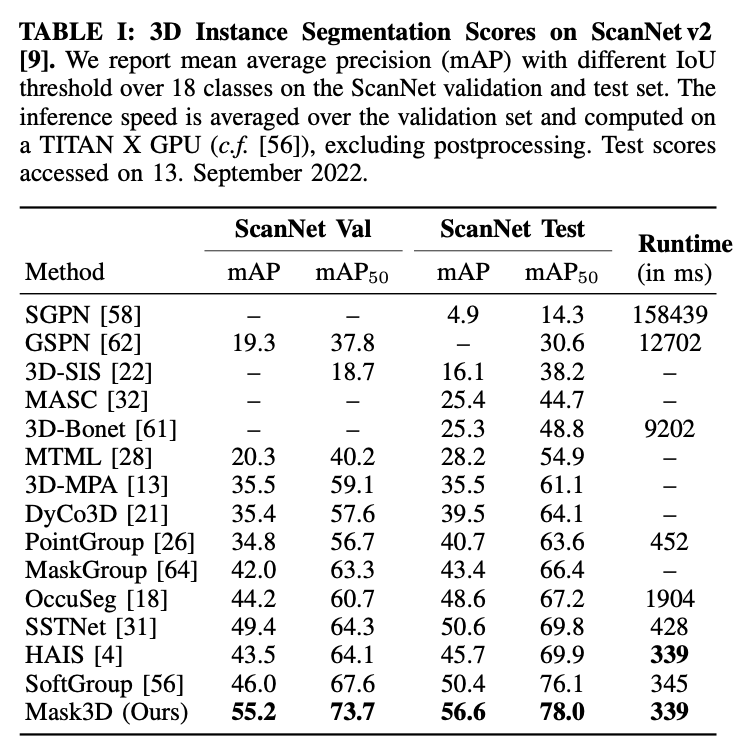
ScanNet
-
S3DIS
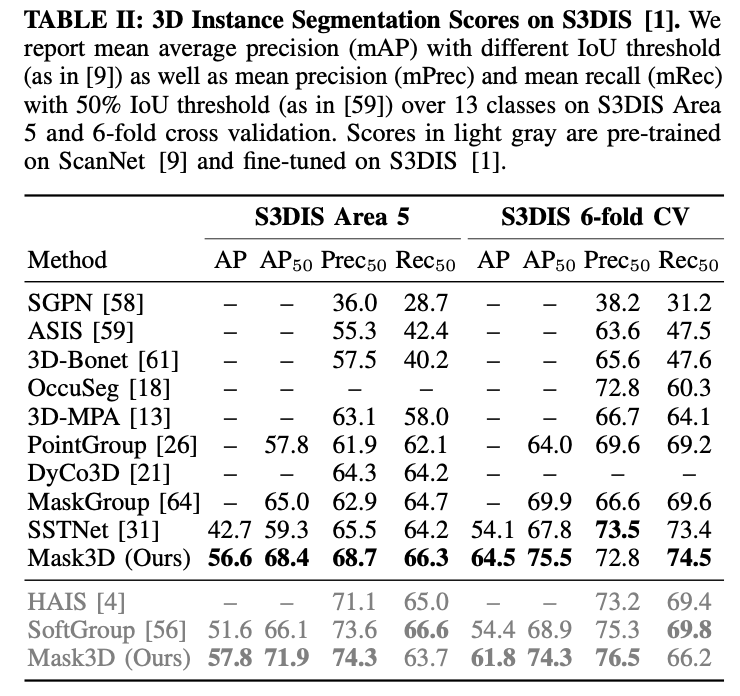
-
ScanNet200(left), STPLS3d(right)
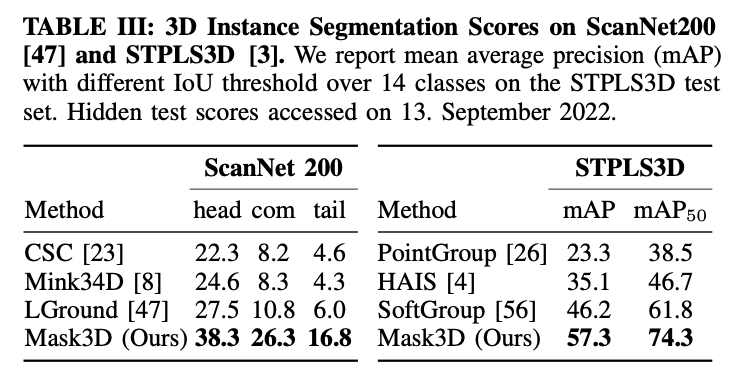
-
Mask3D outperforms prior work by a large margin
on the most challenging metric mAP by at least
6.2mAP on ScanNet,
6.2 mAP on S3DIS,
10.8 mAP on ScanNet200
11.2 mAP on STPLS3D. -
Also report scores for models pre-trained on ScanNet
and fine-tuned on S3DIS.
For Mask3D, pre-training improves performance by 1.2mAP on Area5. -
Mask3D's strong performance on indoor and outdoor datasets
as well as its ability to work under challenging class imbalance settings
w.o. inherent modifications to the architecture or training regime
highlights its generality.
Analisysis Experiments
1) Query Types
- Mask3D iteratively refines instance queries
by attending to voxel features. - Paper distinguished 2 types of query initialization
prior to attending to voxel features:
- parametric queries
- & 3. non-prametric initial queries
-
Parametric refers to learned positions and features [2],
while Non-parametric refers to point positions sampled with FPS(furthest point sampling). -
When selecting query positions with FPS,
we can either initialize the queries to zero (2, as in 3DETR[37])
or use the point fatures at the sample position (3). -
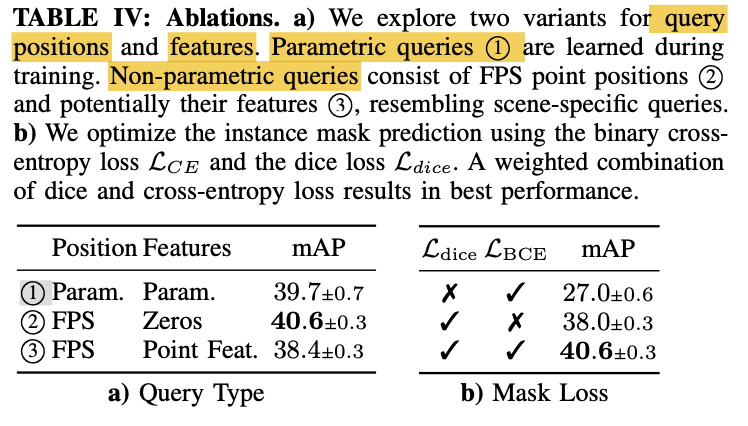
-
Tab 5 shows the effects of using
parametric or non-parametric queries
on ScanNet validation(5cm). -
✅ Paper observes that non-parametric queries 2
outperfrom parametric queires 1 -
Interestingly, 3 results in degraded performance
compared to both parametric 1 and
position-only non-parametric queries 2
2) Number of Queries and Decoders
Number of Queries
-
Paper analyze the effect of varing numbers of queries K
during inference on models trained with
K = 100 and K = 200 non-parametric queries
sampled with FPS. -
By increasing K from 100 to 200 during training,
paper observes a slight increase in performance
at the cost of additional memory.
(Fig3. left)
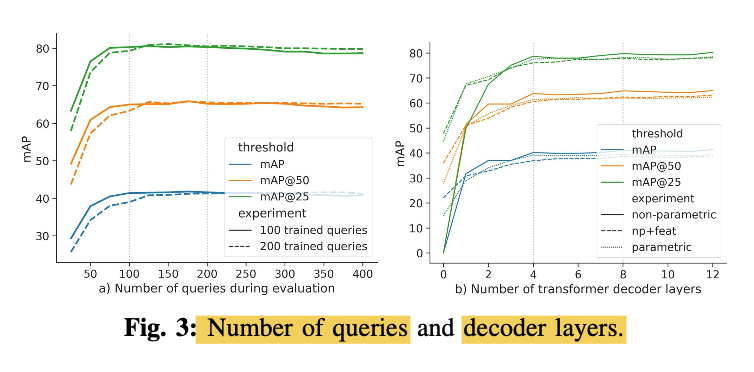
-
When evaluating with fewer queries
than traind with,
paper observes reduced performance
but faster runtime.
'
When evaluating with more queries
than trained with,
paper observes slightly improved performance (typically less than 1mAP) -
Paper's final model uses K = 100
due to memory constraint
when using 2cm voxels
in the feature backbone.
# of Decoder Layers
- Also anayse the mask quality
that paper obtians after
each Transformer decoder layer
in trained model (Fig3. right)
-Rapid increase up to 4 layers,
then the quality increases a bit slower.
3) Mask Loss
-
Mask Module generates instance heatmaps
for every instance query. -
After Hungarian matching,
the corresponding GT mask is used
to compute the mask loss Lmask -
Binary corss entropy loss LBCE
is the obvious choice for binary segmentation taksk.
However, it doens't perform well
under large class imbalance
(few FG mask points, many BG points) -
Dice loss Ldice is designed to address such data imbalance.
- Tab 5 (right) shows scores on ScanNet validation
for combinations of both losses.

- ✅ While Ldice improves over LBCE,
paper observes an additional improvement
by training model with a weighted sum of both losses. (Eq.5)
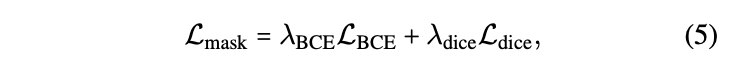
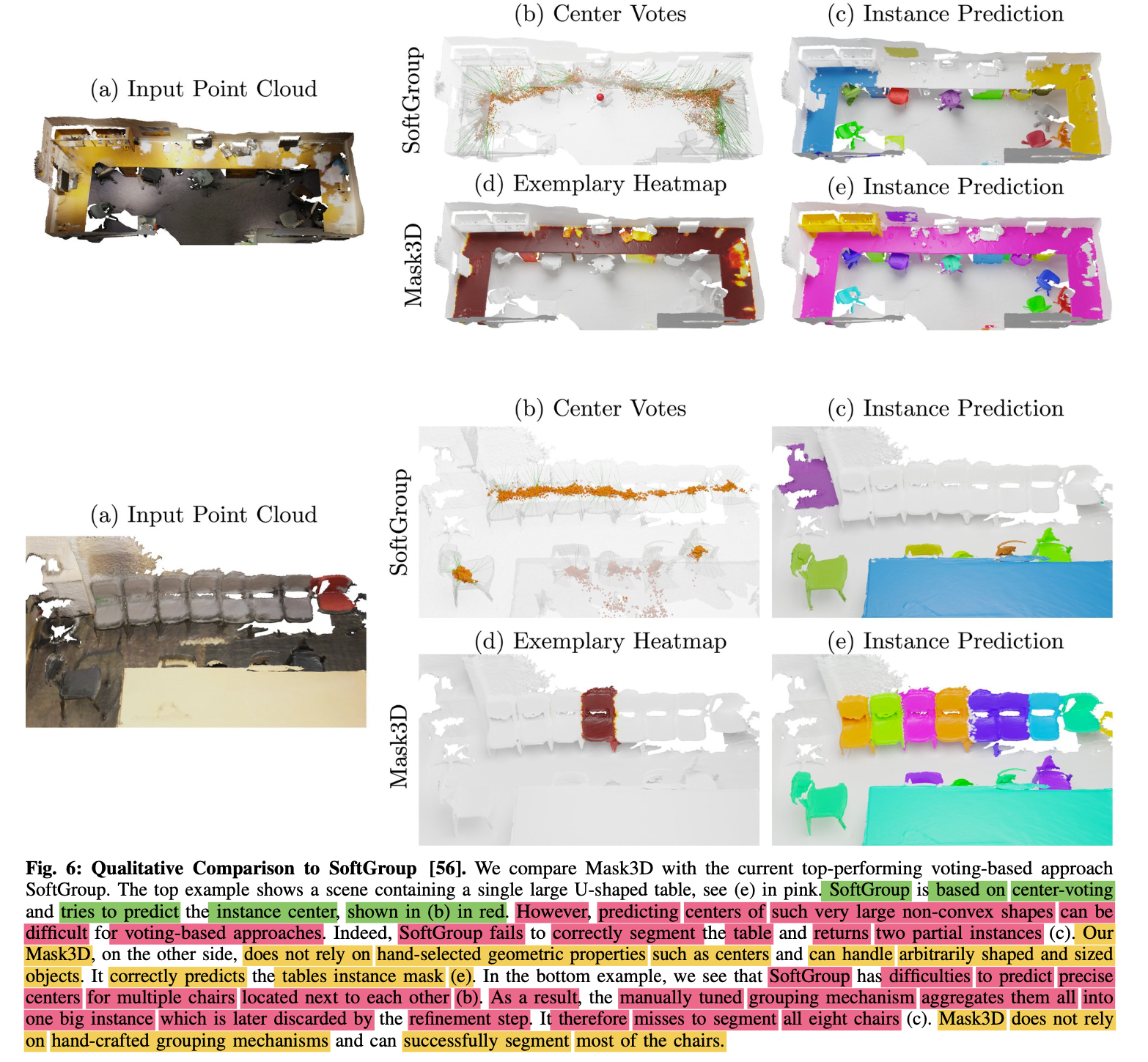
Qualitative Results
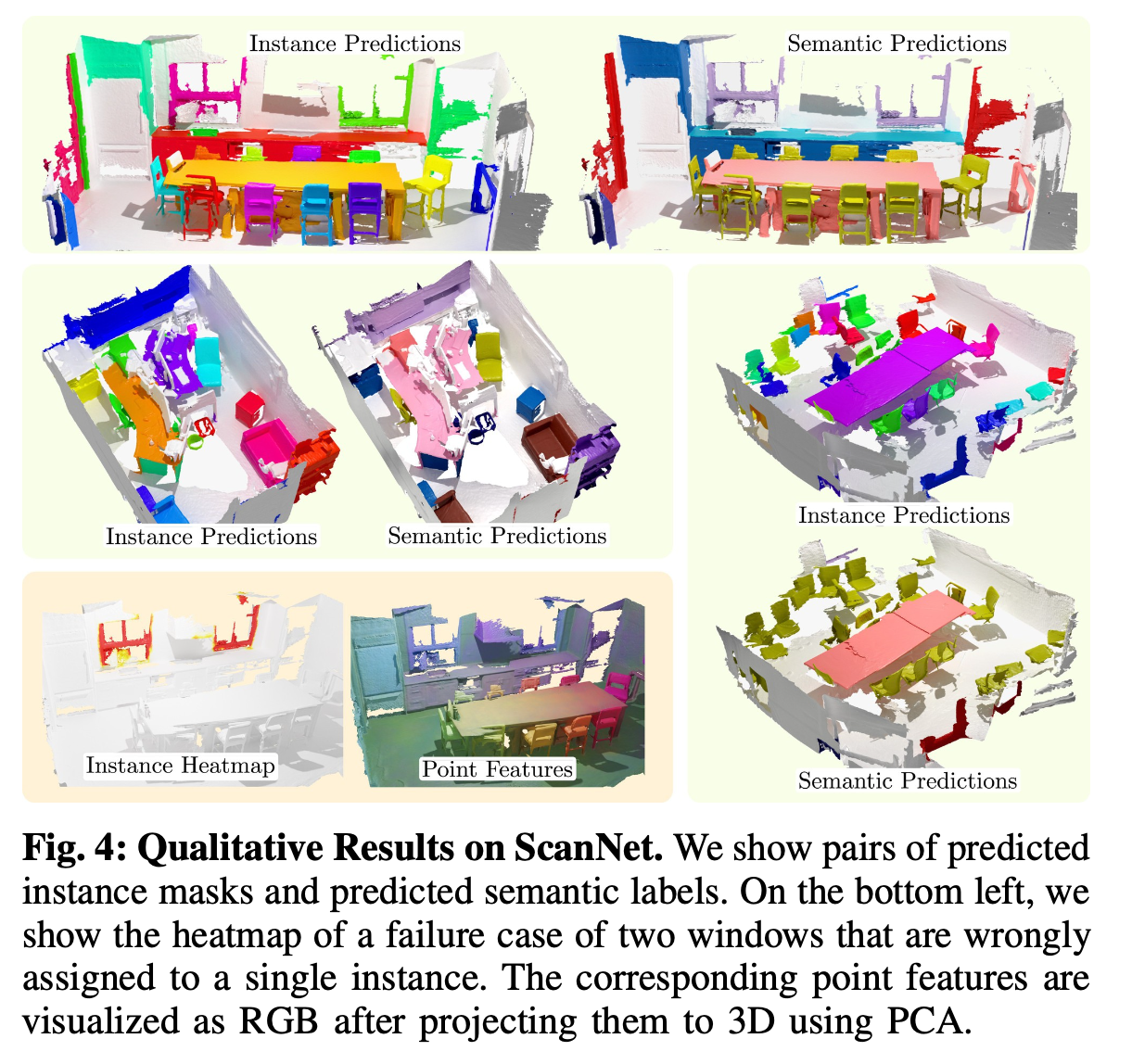
- Scenes are quite divers and present a number of challenges,
including clutter, scanning artifacts and numerous similar objects. - Still, Model shows quite robust results.
🤔 Limitation
-
Systematic mistake that
paper observed are merged instances
that are far apart (Fig.4 bottom left) -
As attention mechanism can attend to full point cloud,
it can happen that
two objects with similar semantics and geometry
expose similar learned point features -
and are therefore combined into one instance
even if they are far apart in the scene. -
This is less likely to happen
with method that explicitly encode geometric priors.
✅ Conclusion
-
Paper introduces Mask3D,
for 3D semantic instance segmentation. -
Mask3D is based on Transformer decoders,
and learns instance queries that,
combined with learned point features,
directly predict semantic instance masks
w.o. need for hand-selected voting shcemes
or hand-crafted grouping mechanisms. -
Author thinks that Mask3D
is an attractive alternative to current voting-based approaches
and expect to see follow-up work along this line of research.
Supplementary Material