Mask-Attention-Free Transformer for 3D Instance Segmentation
🔑 Key Contributions
-
Author Observes that existing transformer-based methods,
suffer from the low recall of initial instance masks,
which causes training difficulty and slow convergence. -
Instead of relying on mask attention,
construct an auxiliary center regression task
to overcome the low-recall issue
&
design a serires of position-aware components.
➡️Faster convergence and Higher performance
-
Experiments show a new SOTA result and performance
on ScanNetv2, ScanNet200, and S3DIS.
🚀 Motivation
-
Recently, transformer-based methods
have dominated 3D instance segmentation,
where mask attention is commonly involved. -
Specifically, object queries are guided by
the initial instance masks
in the first cross-attention,
'
and then iteratively refine themselves
in a similar manner. -
🔥 However, Paper observes that
tha mask-attention pipleline
usually leads to slow convergence
due to "low-recall" initial instance masks -
✅ Therefore, paper abandons the "mask attention design"
and resort to an auxiliary ⭐ "center regression" ⭐ task instead. -
Through center regression,
effectively overcome the low-reacall issue
and perform cross-attention by imposing positional prior. -
To reach this goal,
paper develops a "series of position-aware designs". -
1️⃣ First, learn a spatial distribution of 3D locations
as the initial position queries.
'
They spread over the 3D space densely,
and thus can easily capture the objects in a scene
with a high recall -
2️⃣ Moreover, present relative position encoding
for the cross-attention & iterative refinement
for more accurate position queries.
Related Works
1. 3D Instance Segmentation
Grouping-based methods [25, 55, 5, 75]
Transformer-based methods [49, 50]
-
with Transformer Decoder Layers,
a fixed number of object queries
attend to global features iteratively
&
directly output instance predictions. -
requires no post-processing
for duplictae removal such as NMS,
since it adopts one-to-one bipartite matching
during training -
Employs mask attention,
which uses the instance mask predicted in the last layer
to guide the cross-attention
[49] Jonas Schult, Francis Engelmann, Alexander Hermans, Or Litany, Siyu Tang, and Bastian Leibe. Mask3d for 3d se- mantic instance segmentation. ICRA, 2023. 1, 2, 3, 4, 5, 6, 7,8
[50] Jiahao Sun, Chunmei Qing, Junpeng Tan, and Xiangmin Xu. Superpoint transformer for 3d scene instance segmentation. AAAI,2023.1,2,3,4,5,6
-
🔥 However,
paper points out that
current transformer-based methods
suffer☠️ from the issue of "slow convergence". -
As shown in Fig.1,
baseline model manifests slow convergence
and lags behind paper's method by a large margin,
particulary in the early stages of training
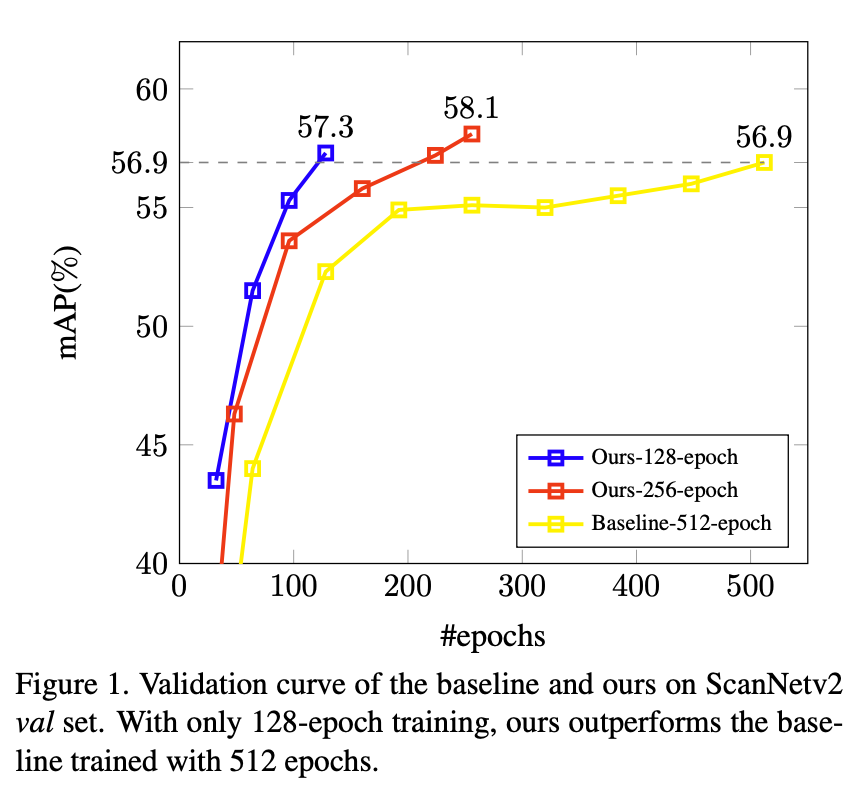
-
Paper dive and find that "slow convergence" issue
is potentially caused by "low recall of initial instance masks".
☕
-
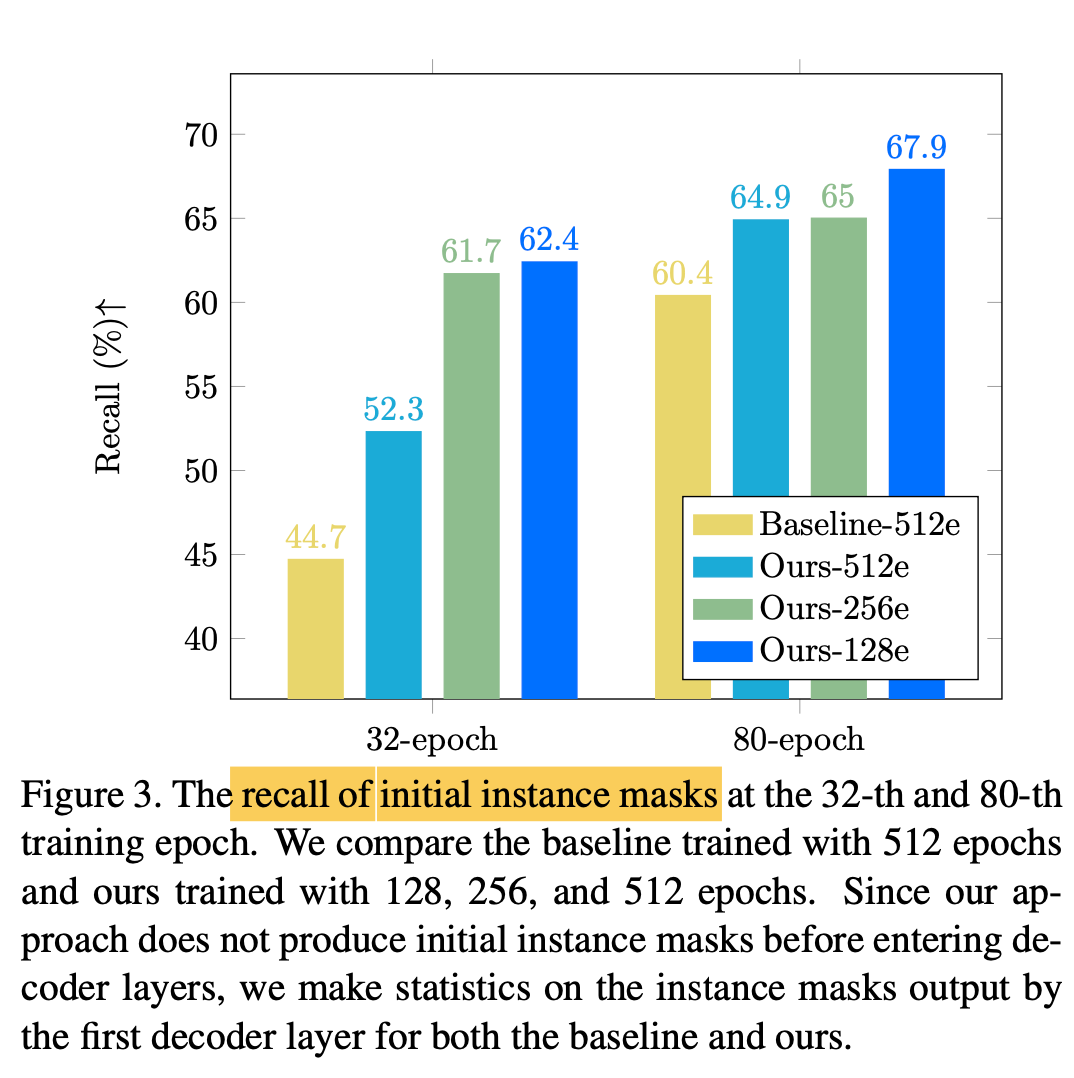
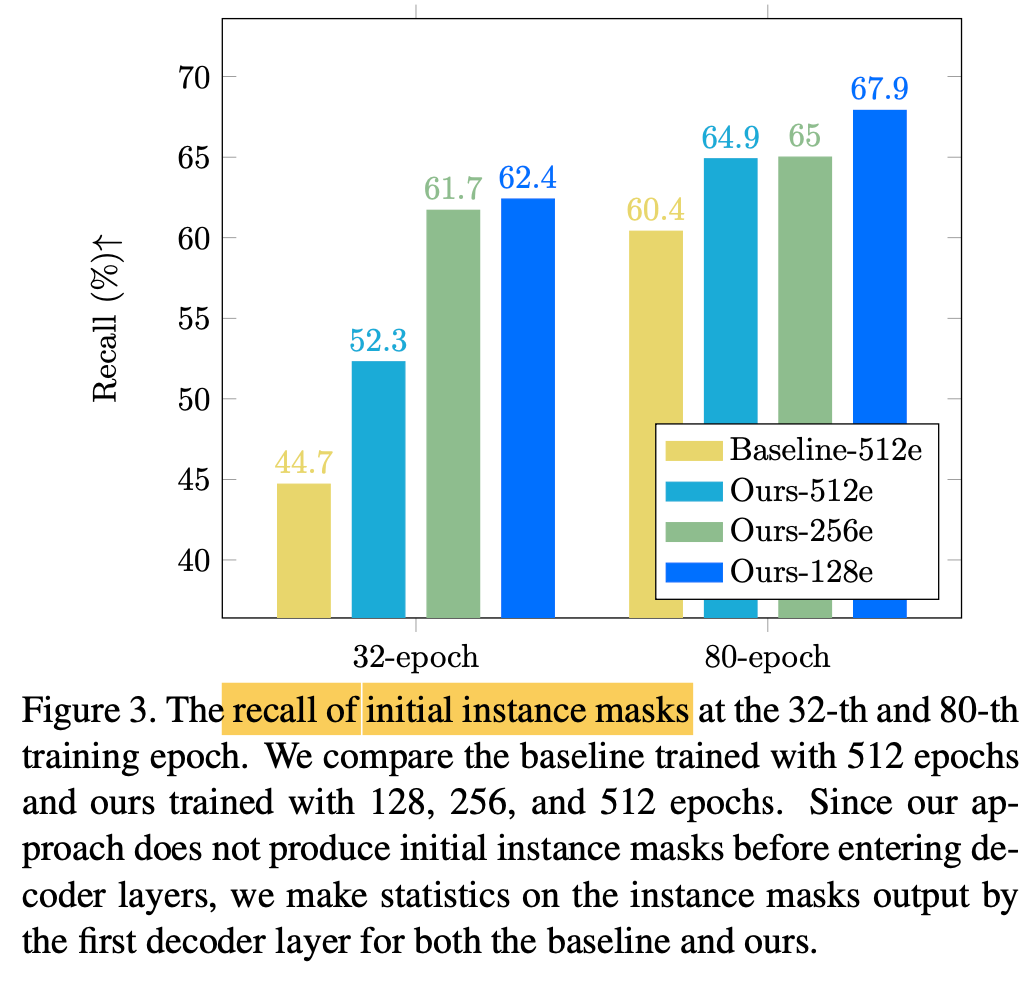
Specifially, as shown in Fig.2
initial instance masks are produced by
"similarity map" between the 'initial object queries' & 'point-wise mask features'.
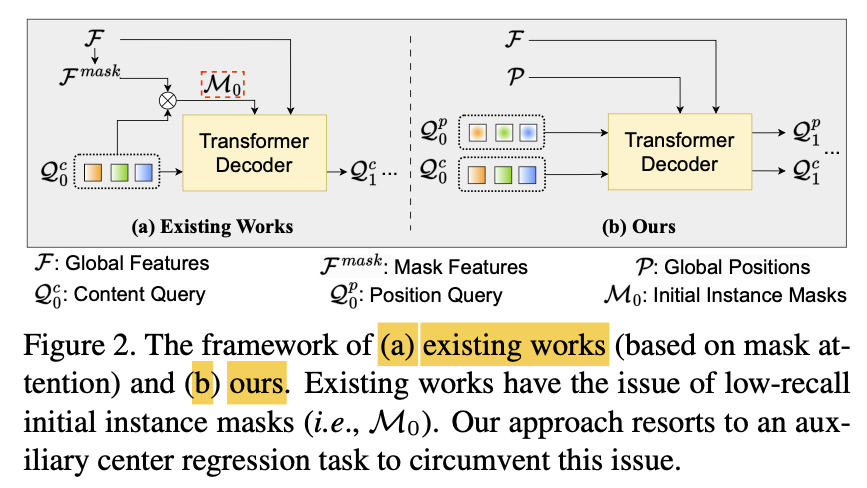
-
Since initial object queries are unstable in
early training,
author notices that "recall of initial instance masks" is substantially lower (Fig.3),
especially at the beginning of training(i.e., the 32-th epoch) -
Low quality initial instance masks
increase the training difficulty,
thereby slowing down convergence.
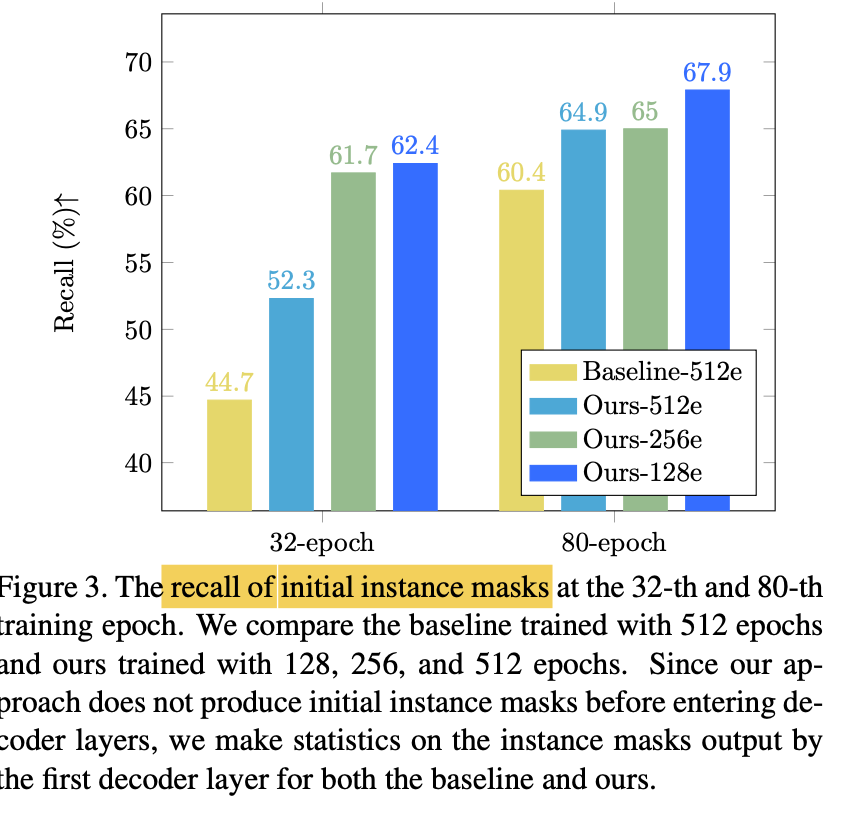
-
Given the low recall of the initial instance masks,
author abandon the 'mask attention design'
and instead construct an "axuiliary center regression" task
to guide cross-attention (Fig.2(b))
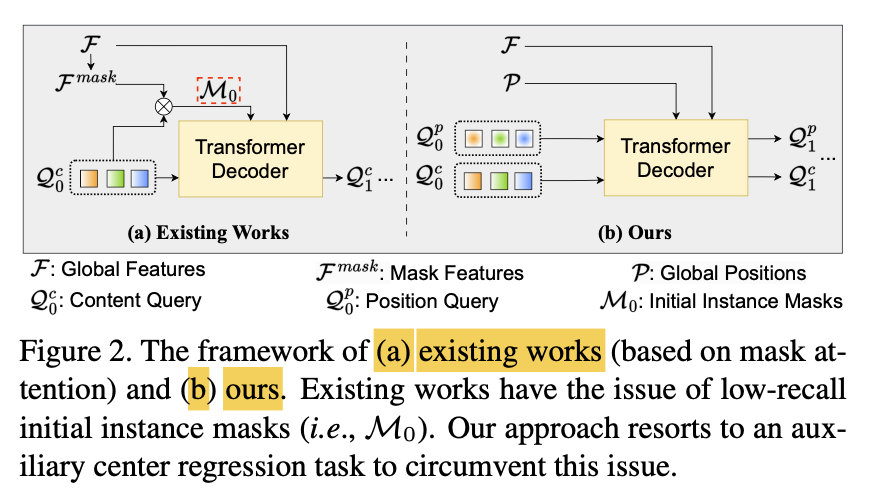
2. Vision Transformer
-
Fundamental model: Attention is all you need[54]
-
Recently, To develop vision fundamental models,
many works [16, 52, 53, 59, 58, 13, 15, 51, 66] rely on the self-attention in transformers.
-
DETR[3] proposes a fully end-to-end pipeline for object detection.
Utilizing transformer decoders
to dynamically aggregate features from images,
&
Using one-to-one bipartite matching
for GT assignmen, yielding an elegant pieline. -
To solve the slow convergence of DETR,
[76, 62, 41, 37, 70, 68] propose deformable attention,
impose strong prior or
decrease searching space in cross-attention
to accelerate convergence. -
[29, 39, 22, 71, 30] prsent ways
to stabilize matching and training
-
Masked attention [8, 7] are proposed
to impose semantic priors
to accelerate training for segmentation tasks. -
⭐ Recently, [28, 73, 63, 64, 43, 49, 50] develop
trasnformer models tailored for 3D point clouds.
[28] Stratified transformer for 3d point cloud segmentation, 2022
[73] Point Transformer, 2021
[63] Pointconvformer, 2022
[64] Point Transformer v2, 2022
[43] Fast point Transforemr, 2022 (Park et al.)
[49] Mask3D, 2023
[50] Superpoint transformer for 3D scene instance segmentation, 2023 -
Following this line of research,
author observes the low recall of initial instance masks,
and present solutions
to circumvent the use of mask attention.
⭐ Methods
Overview
Review of Previous Methods
-
Mask3D[49] & SPFormer[50]
present a fully end-to-end pipeline,
allowing object queries to directly output "instance predictions". -
With transformer decoders,
a fixed number of object queries
aggregate infromation from the global features
(either voxel features [49] or superpoint features[50])
extracted with the backbone. -
Similar to Mask2Former [8, 7],
adopt mask attention
and rely on the instance masks
to guide the cross-attention. -
Specifically, cross-attention is masked with the instance masks
predicted in the last decoder layer,
so that the queries only need to consider "masked features". -
🔥 However, as show in Fig 3,
recall of initial instance masks is low
in the early stages of training.
🔽
It hinders the ability to achieve a high-quality result
in the subsequent layers
and thus increases training difficulty.
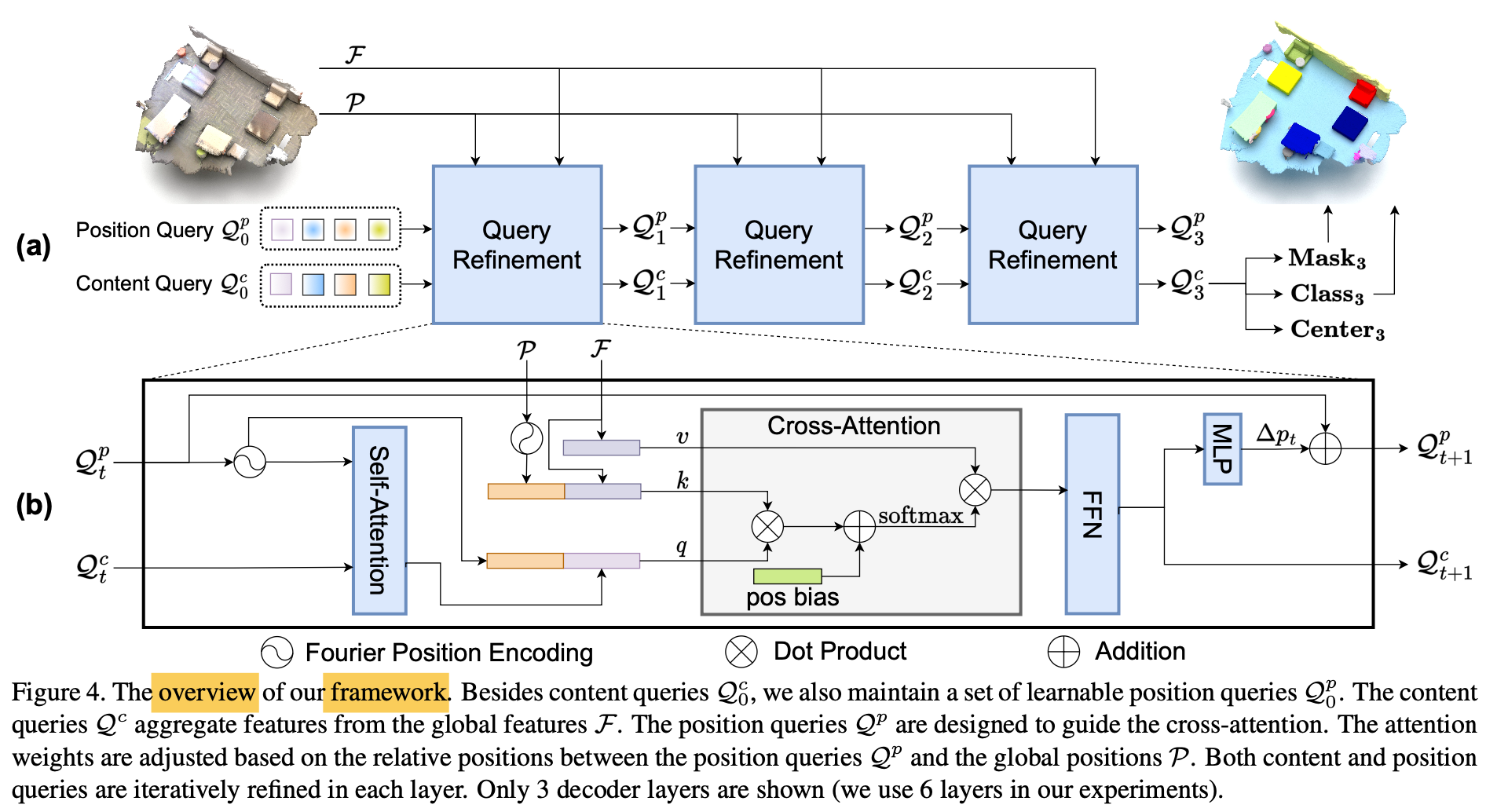
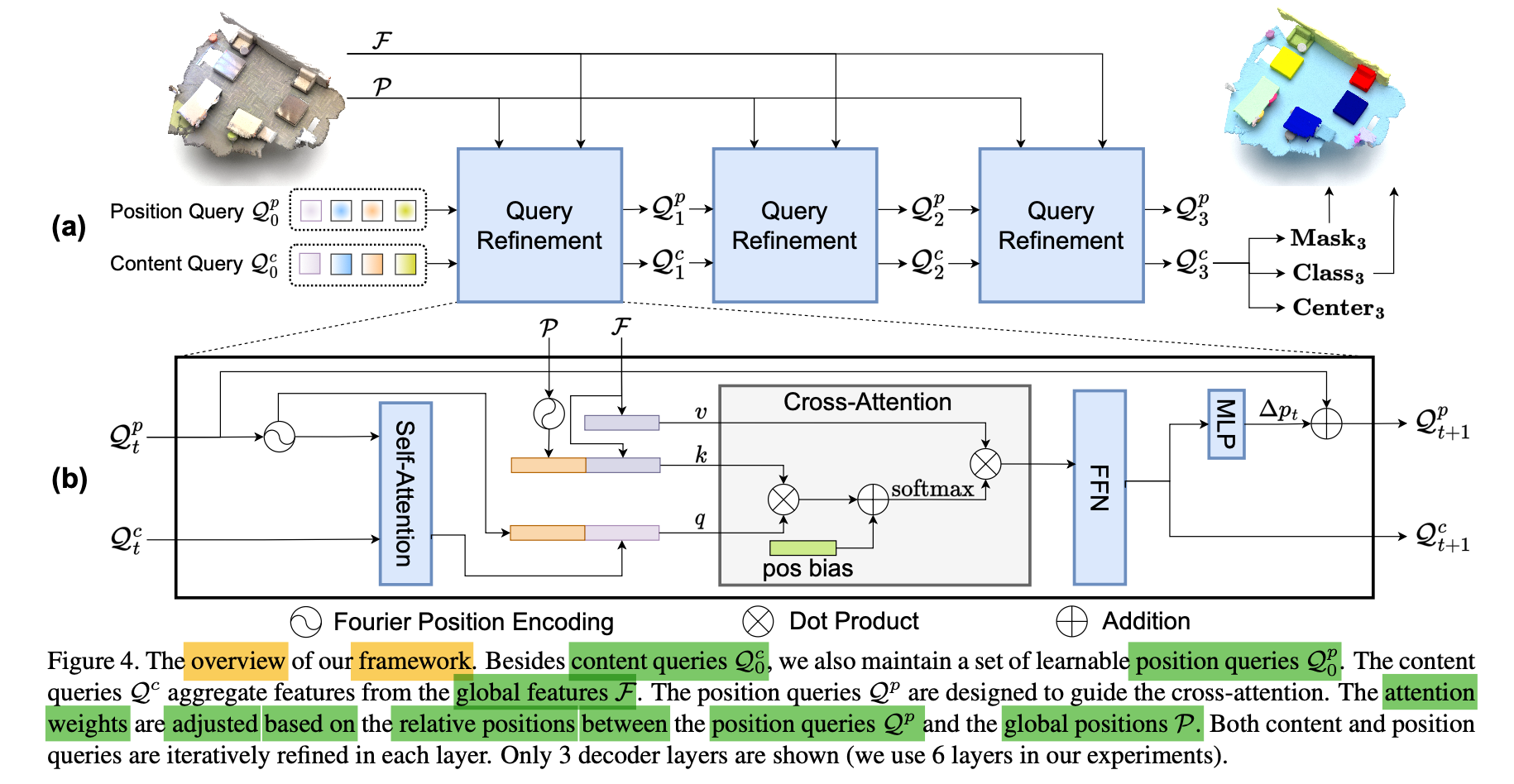
Overview of Paper's Method
-
Instead of relying on "mask attention",
propose an auxiliary center regression task
to guide instance segmnetation. -
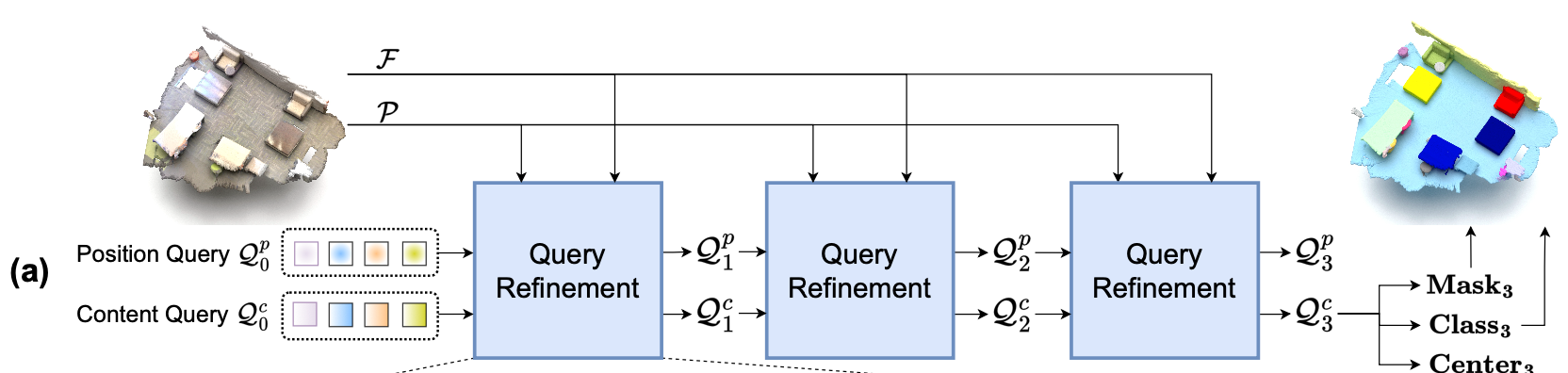
-
First,
yield the global positions P "from the input point cloud" (P ∈ )
&
extract global features F "using the backbone" (F ∈ )
(P and F can be either voxels [49] or superpoints [50] positions and features) -
In contrast to existing works,
besides the content Queries ∈
also maintain a fixed number of position queries ∈ [0, 1] ^
that represent the normalized instance centers. -
is randomly initialized, is initialized with zero.
-
Given global positions and global fetures ,
Goal: let the positional queries guide their corresponding content Queries in cross-attention
and then
interatively refine both sets of queries,
and finally
predict the instance centers, classes and masks. -
For the t-th decoder layer, this process is formulated as

Position-aware designs
Overview of position-aware designs
-
To enable center regression,
and improve the recall of initial instance masks,
paper develops a series of position-aware designs -
1) Firstly,
maintain a set of "learnable position queries",
each of which denotes the position of
its corresponding content query. -
They are densely distributed over the 3D space,
and we require each query
to attend to its local region. -
As a result, queries can easily capture the objects in a scene
with a higher recall,
which is crucial in reducing training difficulty & accelrating convergence. -
2) In addition,
design the "contextual relative position encoding" for cross-attention. -
Compared to the mask attention
used in previous works, this solution is more flexible
since the attention weights are adjusted by
relative positions
instead of hard masking. -
3) Furthermore,
"iterativel update the position queries"
to acheive more accurate representaton. -
4) Finally,
introduce the "center distances"
between predictions & GT
in both matching and loss.
1) Learnable Position Query
-
Unlike previous works [49, 50],
introduce an additional set of position queries
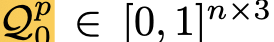
-
Since the range of points varies significantly
among different scenes,
initial position queries are stored in a normalized form as learnable parameters
followed by sigmoid function. -
Basically, wecan obtain the absolute positions
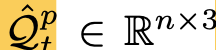
from the normalized position queries

for a given input scene as

-

-
Initial position queries are densely spread
throughout the 3D space. -
Also, every query aggregates features from its local region.
-
This design choice makes it easier
for the initial queries
to capture the objects in a scene
with a high recall (as shown in Fig 3)
-
It overcomes the low-recall issue
caused by initial instance masks,
and consequently reduces the training complexity of the subsequent layers.
2) Relative Position Encoding
-
Other than absolute position encoding **(e.g., Fourier or sine transformations).
-
Adopt contextual realtive position encoding
in cross-attention -
Inspired by [28],
1] calcuate the relative positions ( ∈ )
between the position queries and global positions
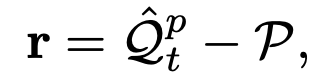
-
And quantize it into discrete relative position ( ∈ )
where s: quantization size, L: length of position encoding table
as shown in Fig.5
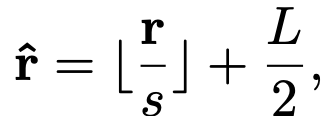
Adding L/2 is to ensure the discrete relative positions are non-negative. -
Then, use discrete relative position as indices
to look up the corresponding "position encoding tables t" ( ∈ ),
as illustrated in Fig. 5
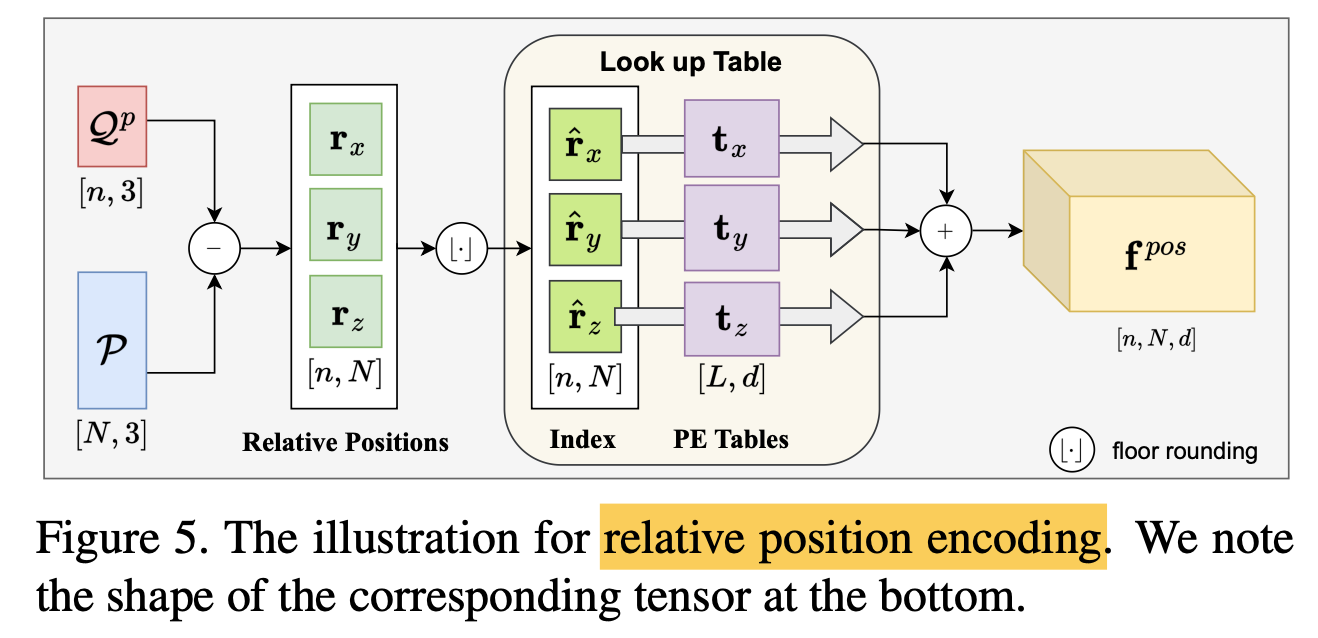
-
Relative position encoding ( ∈ )
is yielded as
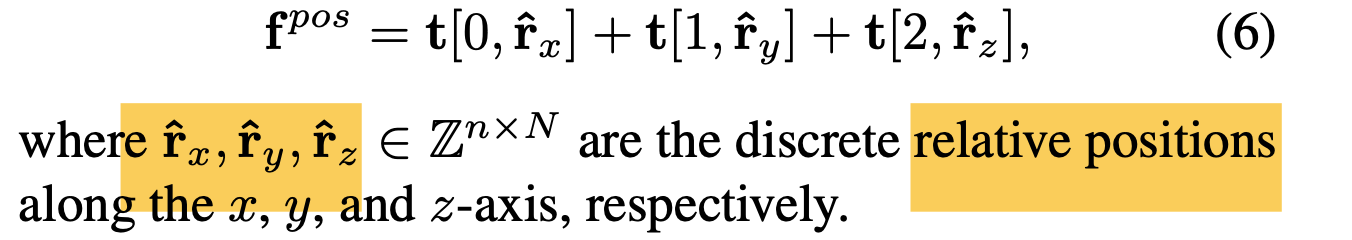
-
Further, the relative position encoding fpos performs dot product with
query features or key features
in thr cross-attention,
which is formulated as:
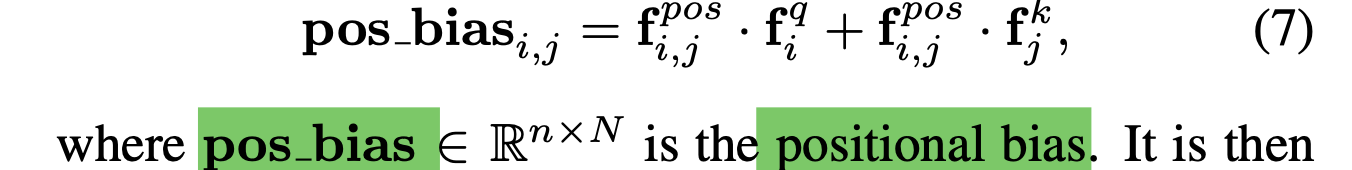
It is then added to the cross-attention weights,
followed by the softmax function, (as shown in Fig.4(b))
-
RPE offers
greater degree of flexibility & error-insensitivity,
compared to mask attention. -
RPE can be likened to a soft mask
that has the ability to adjust attention wegihts flexibly,
instead of hard masking. -
RPE integratees semantic information (e.g., object size and class)
thus can harvest local information selectivel. -
This is accomplished by the interaction
between the relative positions and the semantic features.
3) Iterative Refinement
-
Since content queires in decoder layers are updated regularly,
it is not optimal to maintain frozen position queries
throughout the decoding process. -
Also, initial position queries are static,
it is beneficial to adapt them
to the specific input scene
in the subsequent layers. -
To that end,
iteratively refine the position queries
based on the content queries -
Specifiaclly, as shown in Fig.4(b),
leverage an MLP
to predict a center offset
from the updated content query
-
Then add it to the previous position query
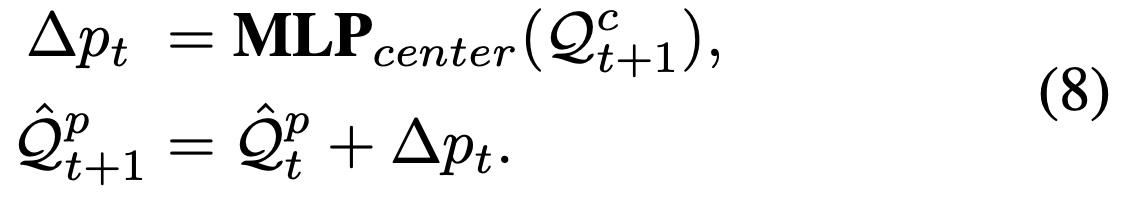
as

4) Center Matching & Loss
-
To eliminate the need for duplicate removal methods
such as NMS(non-maximum suppression),
bipartite matching is adopted during training. -
Existing works [49, 50] rely on semantic predictions and binary masks
to match the GT. -
In contrast, to support center regression,
✅ incorporate center distance in bipartite matching. -
Since we require the queries
to only attend to a local region,
it is critical to ensure that
they only match with nearby GT obejcts. -
To achive this, adapt the matching costs formultation as follows

(k: predicted instance, : GT instance,
C: matching cost matrix,
λ: cost weights) -
Hungarian Algorithm is then applied on C
to yield one-to-one matching result , ( ∈ ℝ ^ (n x ninst) )
which is followed by ths loss function as

👨🏻🔬 Experimental Results
Experimental Setting
Network Architecture
1) For ScanNetv2, ScanNet200
-
Backbone: 5-layer U-Net (followe previous works)
-
Initial Channel: 32
-
Input features: coordinates & colors
Unless otherwise specified -
6 Layers of Transformer decoders
(head number: 8,
hidden dimenstions: 256
feed-forward dimensions: 1024) -
Fourier absolute position encoding
with temperature set to 10,000 -
RPE
quantization size: 0.1 m
length of the RPE table: 48 -
Baseline model: [50]
unless otherwise specified.
2) S3DIS
- Baseline model: Mask3D[49]
- Backbone: Res16UNet34C
- 4 Decoders to attend to the coarset 4 scales,
repeated 3 tiems with shared parameters - Decoder Hidden Dimension: 128
Decoder Feed-Forward Dimension: 1024
Dataset
ScanNetv2, ScanNet200, S3DIS
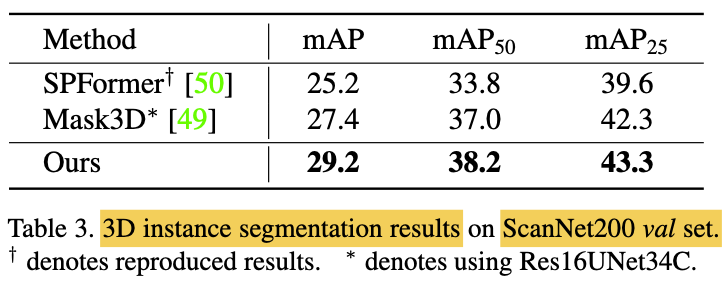
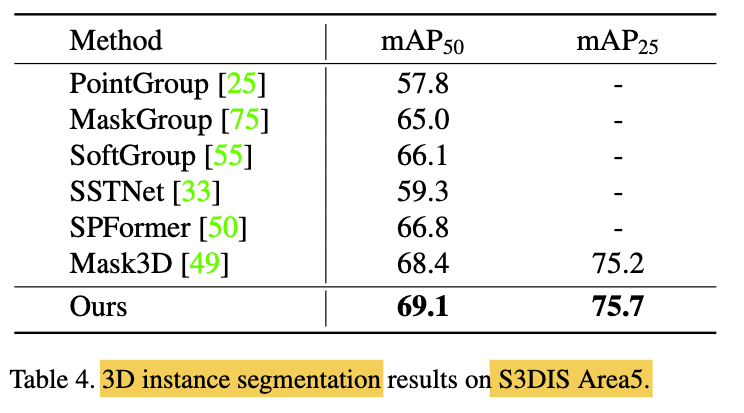
Instance Segmentation Results
-
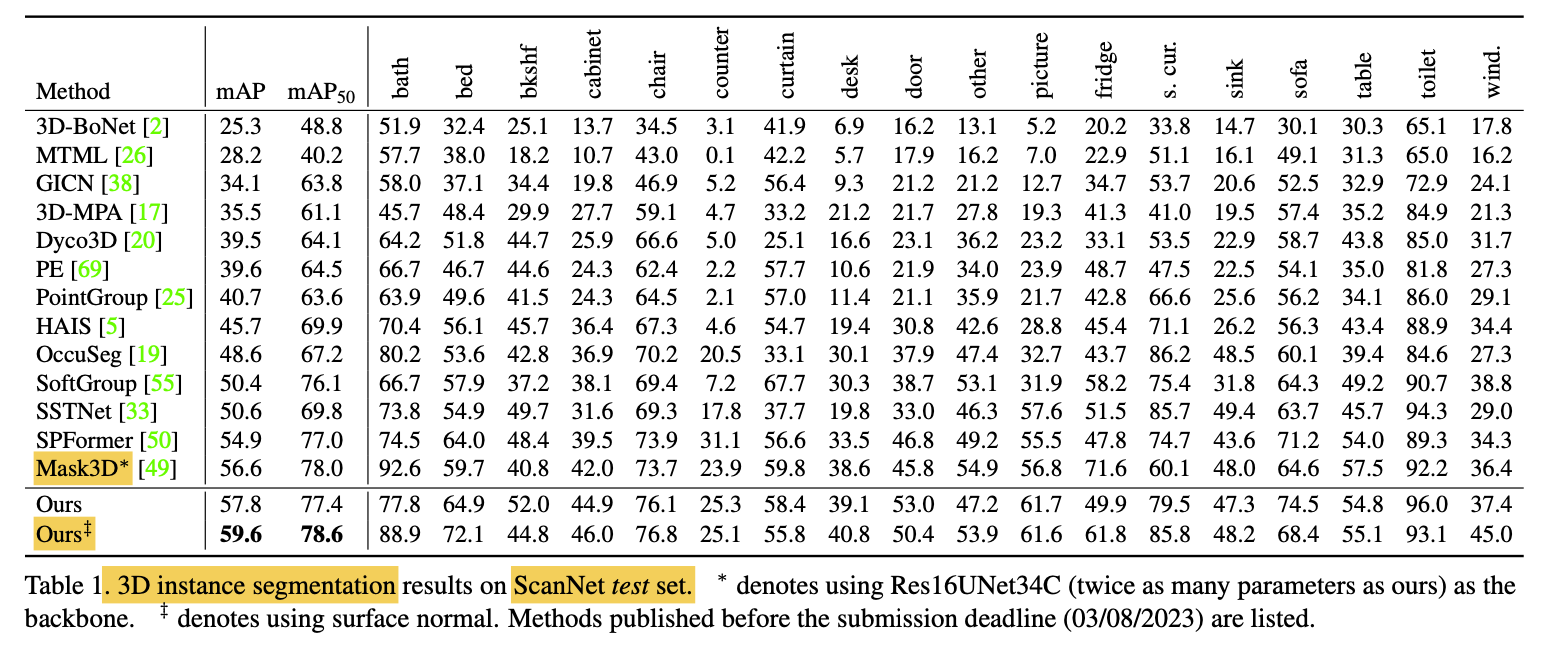
-
Considerable increase in mAP
compared to previous works, -
suggesting superior ability
to capture fine-grained details
& produce high-quality instance segmentation. -
While Mask3D slightly outperforms
in terms fo mAP50,
potentially due to their use of a stronger backbone
(i.e., Res16UNet34C with twice as many parameters as outs)
and DBSCAN post-processing. -
Despite this, we produce significantly better
on the ScanNetv2 val set than Mask3D, (Table2) -
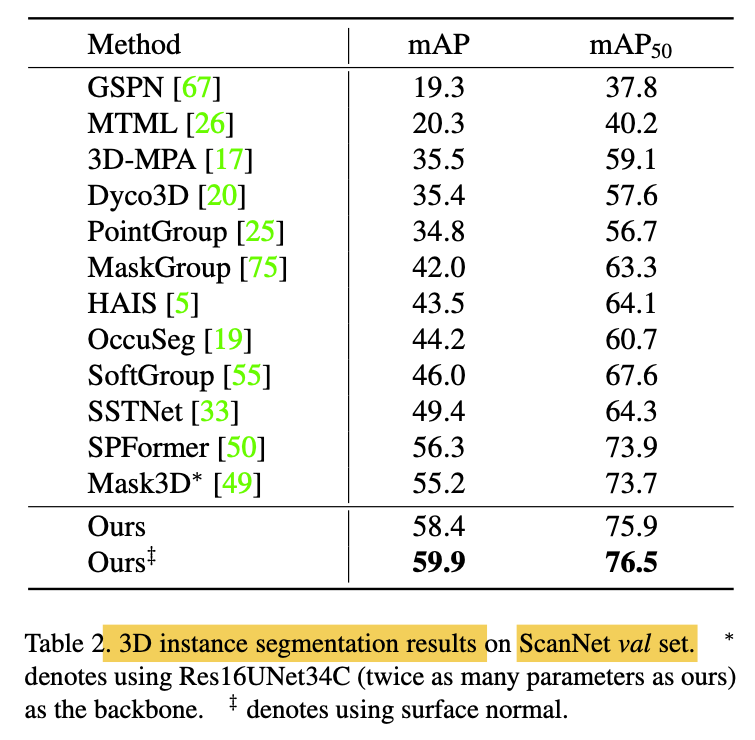
-
-
Previous works employ mask attention,
while we do not. -
This verifies the succes of auxiliary center regression task
in replacing mask attention. -
Ablation Study
1) Learnable Position Query
-
Position query aims to provide an
explicit center representation
to the content query counterpart. -
Making it learnable intends to
learn an optimal initial spatial distribution. -
Previous works adopt non-parametic initial queries,
where FPS(Furthes Point Sampling) is used
to sample a number of points
and transform them into position encodings
via Fourier transformation
followed by an MLP. -
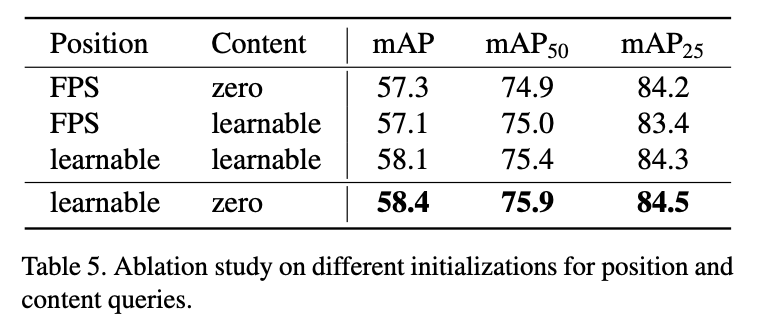
-
Result show that
learnable position query & zero-initialized content query perform best. -
Potential reason why 'FPS' lag behind 'learnable'
: latter leans an optimal spatial distribution. -
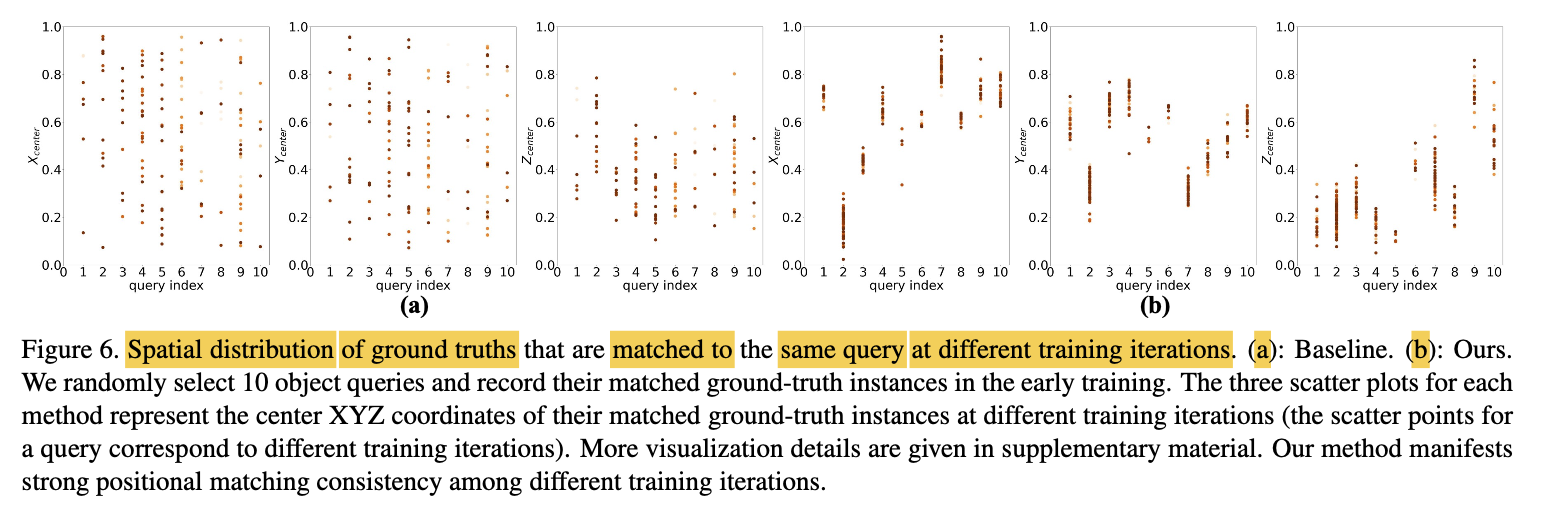
-
To show the pattern of learnable position query,
visualized the spatial distribution of center coordinates
of the matched GT for a query. -
It shows that each query
consistently attends to a local region.
2) Relative Position Encoding
-
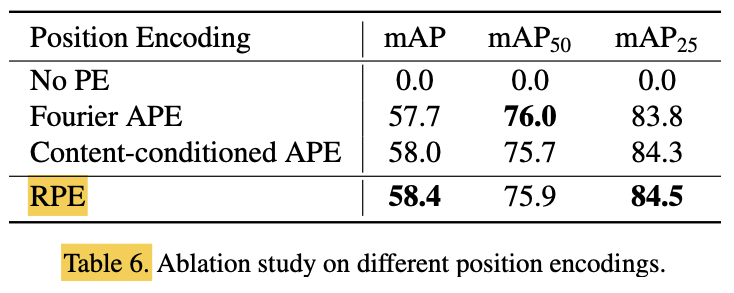
-
Outperformance of RPS implies
Both semantic information and relative relations are beneficial. -
Author notices that
if do not apply any position encoding,
training corrupts.
This shows that positional prior is crucial in paper's framework.
3) Iterative Refinement
-
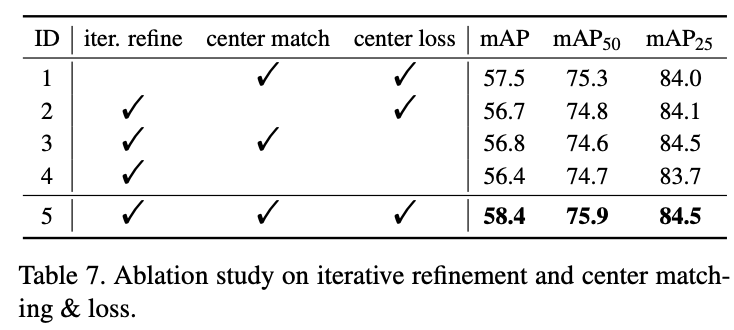
-
When iterative Refinment removed
and positon query be freezed,
it causes a performance drop of 0.9% mAP -
This verifies the effectiveness of iterative refinement.
4) Center Matching & Loss
-

-
Both center matching and loss are important
to paper's framework.
Object Detection Results
-
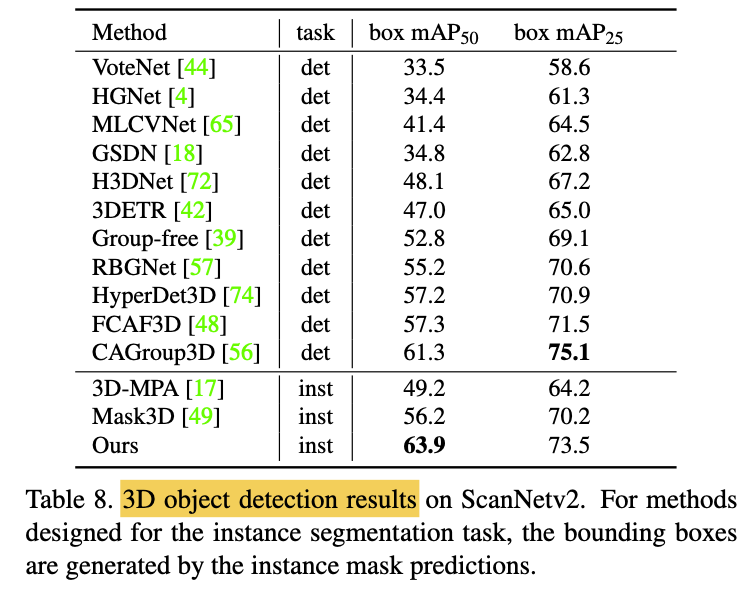
-
instance predictions of instance segmentation
can be easily transformed into bounding box predictions,
by obtainint the min and max coordinates of
maksed instance. -
Better than prev methods tailored for 3D object detection
in terms of mAP50.
Visual Comparison
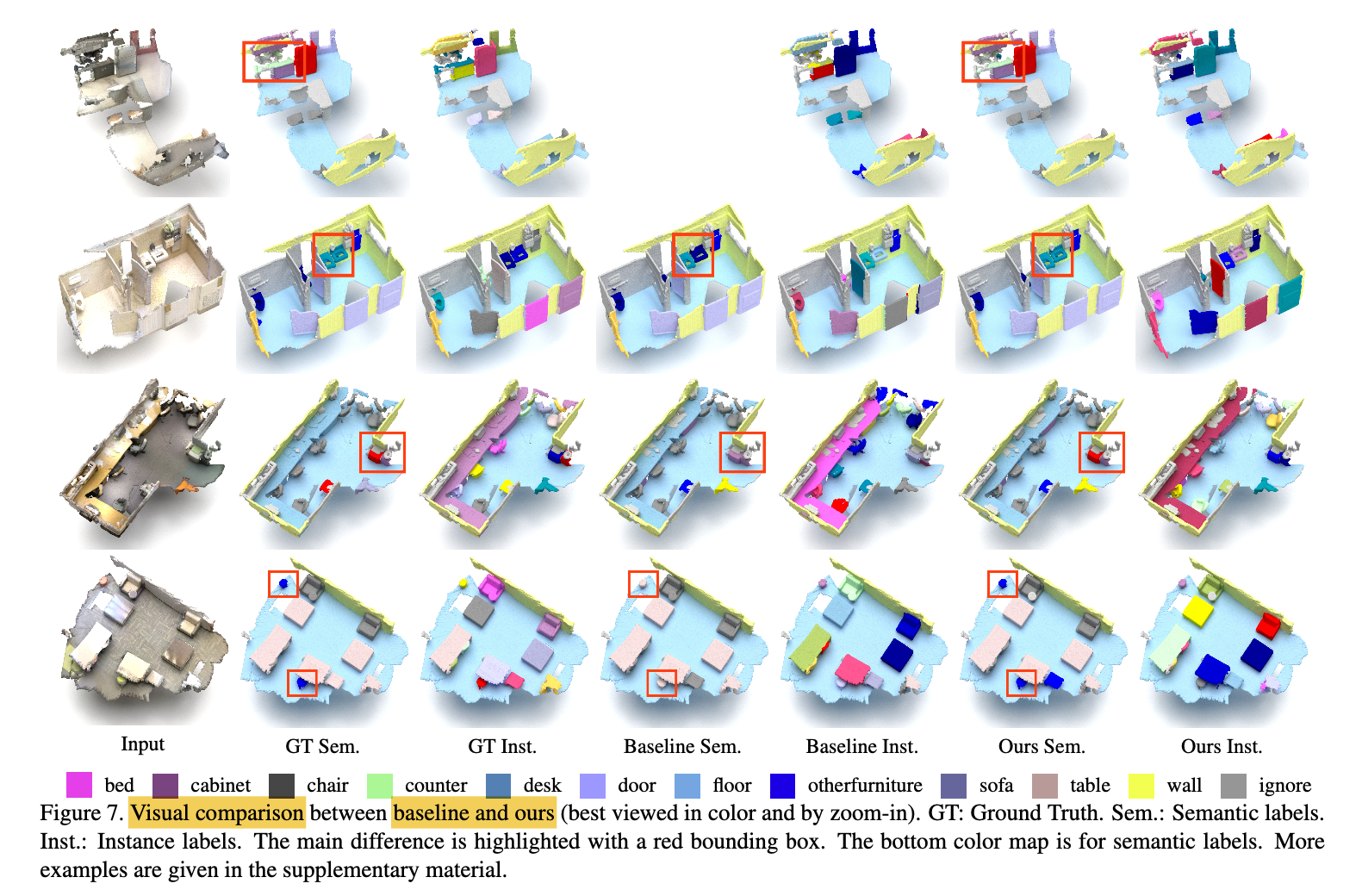
- Tends to correctly recognize
the classes of the instances.
