해당 포스팅은 논문에 대한 번역이 아닌 요점 위주로 정리해놓은 글임을 밝힙니다.
또한, DSBA 연구실에서 해당 논문에 대해 자세히 설명해놨는데 많이 참고해서 적은 글임을 밝힙니다.
Background
- Knowledge Intensive Task (KIT) : 단순한 정보 검색 그 이상을 의미함. 문제 해결을 위해 광범위한 배경 지식이 필요하며, 지식의 응용이 필요한 작업
- KIT에는 Fact Checking, Abstractive QA 등 여러 task들이 있음
- Open-Domain Question Answering (ODQA) : 엄청나게 많은 정보들을 포함하고 있는 대량의 문서들로부터 질문에 대한 답변을 찾는 문제. KIT의 일부라고 여겨짐.
- Retriever : question과 관련된 passage를 KB(Knowledge Base)에서 찾는 모델.
- BM25와 같은 TF-IDF 기반 구조 → 최근에는 BERT와 같은 인코더 구조 ↑
- Reader : passage에서 answer에 해당하는 span을 찾는 모델.
- BERT와 같은 인코더 구조 ↑
- Generator : passage와 question 입력 → answer를 출력하는 모델.
- BART, T5와 같은 인코더-디코더 구조.
- Retriever : question과 관련된 passage를 KB(Knowledge Base)에서 찾는 모델.
Reader와 Retriever는 병렬적으로 사용하는 것이 아닌 방법론에 따라 선택
ODQA 및 KIT 연구흐름
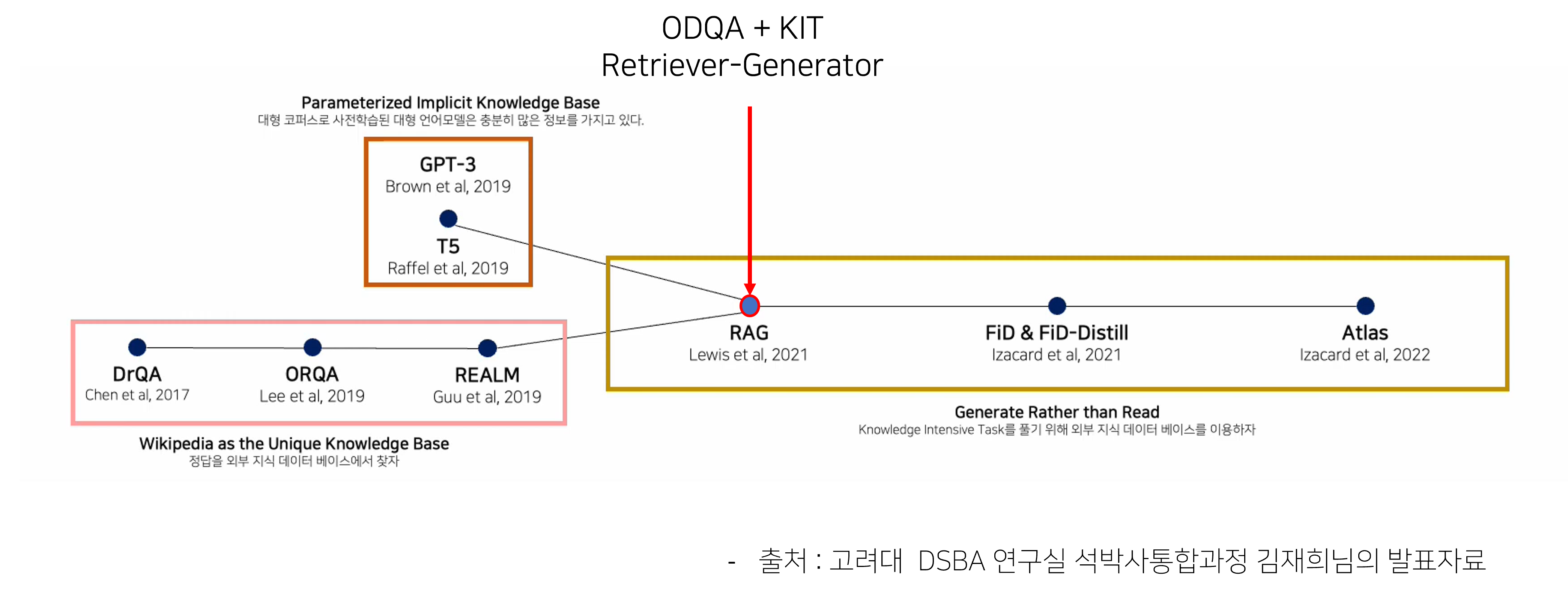
- DrQA, ORQA, REALM의 경우 ODQA의 연구 분야들이고, 이를 위해 Retriver-Reader 구조를 사용
- RAG는 이와 다르게 ODQA과 KIT를 처음 통합
- 또한, Retriever-Reader 구조가 아닌 Retriever-Generator 구조를 처음 사용
Model Architecture
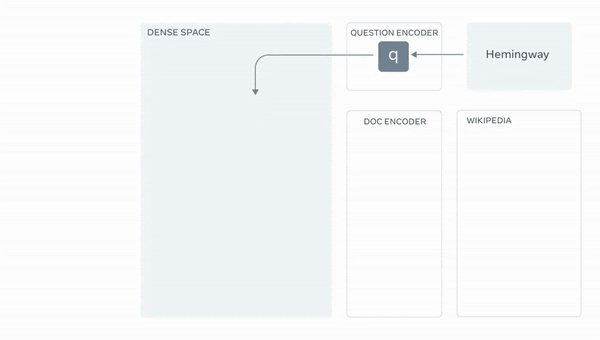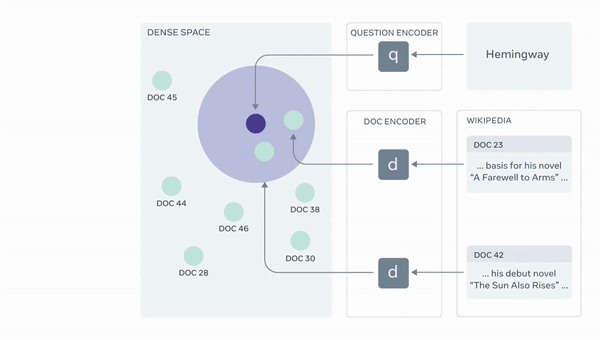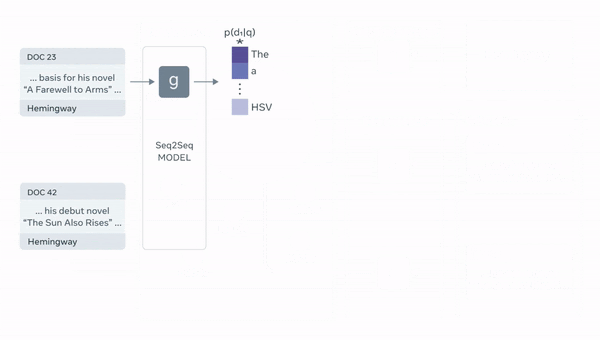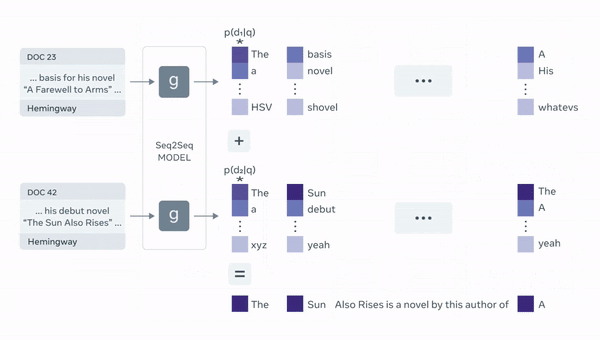
- 위 그림은 Facebook AI Research에서 공식으로 업로드한 RAG의 model architecture
- 구체적으로 얘기하면
1) Task에 맞게 query가 입력되면 DPR Query Encoder를 통과하여 representation vector인 생성
2) MIPS(Maximum Inner Product Search)를 바탕으로 q(x)와 가장 가까운 5개 혹은 10개의 passage를 탐색
이 때,document encoder, 즉 passage encoder 또한 DPR 인코더 사용
3) passage를 기존 query와 concat하여 generator input으로 사용
4) 각 passage별 생성결과를 marginalize하여 최종 결과물 도출
이 때, generator는 BART-large를 사용
: 인코더-디코더 기반의 모델 어떤 것을 사용해도 무방함
- 구체적으로 얘기하면
위 그림을 보고 이해가 되지 않는다면 아래 그림을 봐도 괜찮을 거 같다
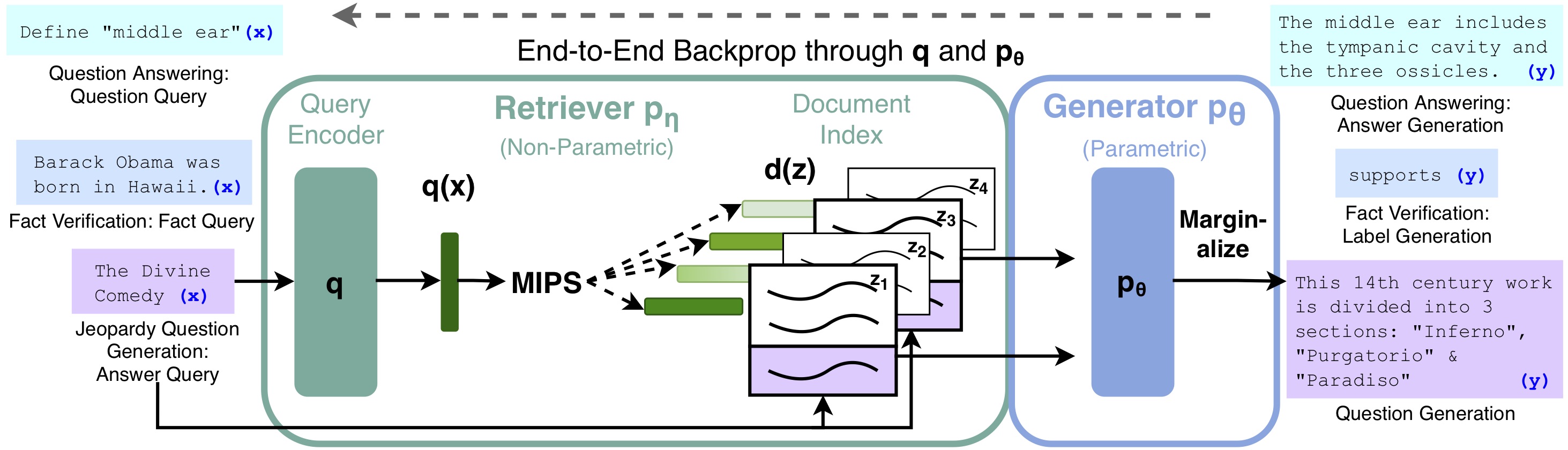
Models
-
marginalization 방법에 따라 RAG-S, RAG-T 두 가지의 모델이 있음
- RAG-S
- 맨 처음에 question과 유사한 document를 뽑고 각 document와 question을 concat하여 총 k개의 forwarding을 진행 후 marginalize하는 방법
- 쉽게 말하면 같은 문서를 사용하여 각 타겟 토큰을 예측하는 방식
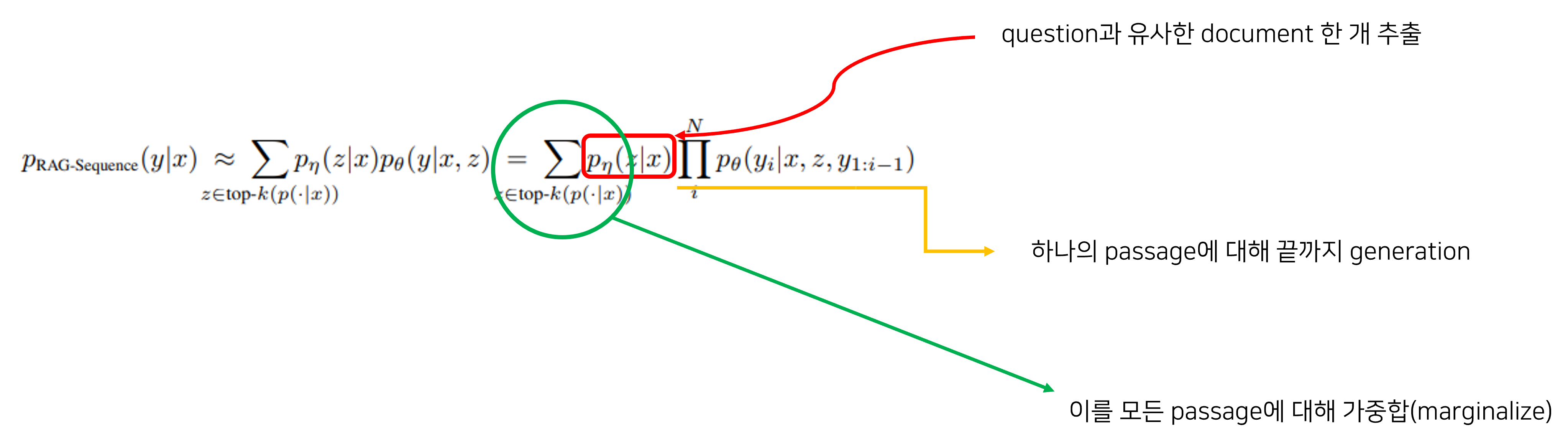
- RAG-T
- 매 target token 마다 다른 document를 retrieve하면서 answer를 생성하는 방법
- 쉽게 말하면 각기 다른 문서에서 타겟 토큰을 예측하는 방식

- RAG-S
-
model 훈련 시 document encoder(BERT_q)는 학습하지 않고, query encoder(BERT_d)와 generator인 BART를 jointly하게 학습
- question과 answer를 간단한 input-output text pair (x, y)로 취급
- answer의 negative log-likelihood를 최소화하면서 RAG를 훈련
Experiments
- ODQA
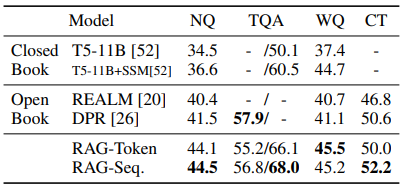
- Natural Questions(NQ), TriviaQA(TQA), WebQuestions(WQ), CuratedTrec(CT)를 대상으로 ODQA task에서의 성능 확인
- CT와 WQ는 크기가 작기 때문에 NQ RAG model로 CT와 WQ를 초기화
- NQ에서 학습된 모델을 기반으로 CT와 WQ에서 추가 학습을 진행(일종의 전이학습 개념)
- metric은 EM(Exact Match)
- Reader를 사용한 DPR보다 좋은 성능
Retrieval-Reader 구조를 택한 REALM보다도 좋은 성능
외부지식을 참조하지 않는 Closed-Book Model인 T5보다도 좋은 성능
(RAG는 BART의 paramteric 지식 + DPR의 non-parametric 지식)
- KIT
-
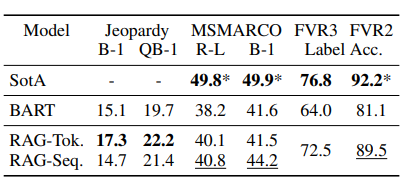
MSMacro NLG task를 이용해서 abstractive QA의 성능을 테스트함.
-
RAG의 성능이 SOTA와 비슷함
-
하지만, RAG는 단순한 extractive QA model이 아닌 abstractive한 QA model이기 때문에 해당 task를 진행할 때, gold passage 없이 질문과 답변을 갖고서만 답변함
-
그럼에도 불구하고 RAG의 성능이 SOTA와 비슷하다는 의미는 RAG는 단순히 정보를 추출만하는 것이 아닌 모델에 내재된 파라미터 지식을 활용할 수 있음을 보여줌.
-
-
Jeopardy Question
- RAG-T의 성능이 매우 좋은 것을 확인할 수 있음
-
Fact Verification
- RAG는 문서 검색을 위한 중간 감독이 필요하지 않음. (SOTA 모델은 필요함) 그럼에도 SOTA 모델과 큰 차이가 나지 않음.
- gold passage가 없어도 스스로 증거를 잘 찾아냄
- RAG가 찾은 문서 중 gold article과 일치하는 비율 test
- top-1의 경우 71%, top-10의 경우 90%
- RAG가 자동으로 증거를 찾는 능력이 매우 뛰어남을 보여줌
-
MSMacro NLG task
질문과 그에 대한 골드 패시지(답변에 필요한 중요한 정보가 담긴 패시지) 그리고 완전한 문장 형태로 구성.
골드 패시지 없이 답변하기 힘든 문제로 이루어짐
(심지어 일부 질문은 위키피디아에서 정보를 검색해도 답을 찾기 어려움)
Jeopardy Question Generation
단순히 question에 대해 answer를 생성하는 것이 아닌 특정 사실을 통해 엔티티를 추측하는 형식.
예를 들어, World Cup이라는 답변으로부터 In 1986 Mexico scored as the first country to host this international sports competition twice와 같은 질문을 생성하게끔 하는 것.
자유 형식으로 생성하고, 정확성과 관련성이 매우 높아야하기 때문에 질문 생성이 매우 어려움
FEVER3
참, 거짓, 정보 부족의 레이블
FEVER2
참, 거짓의 레이블
-
Ablation Study
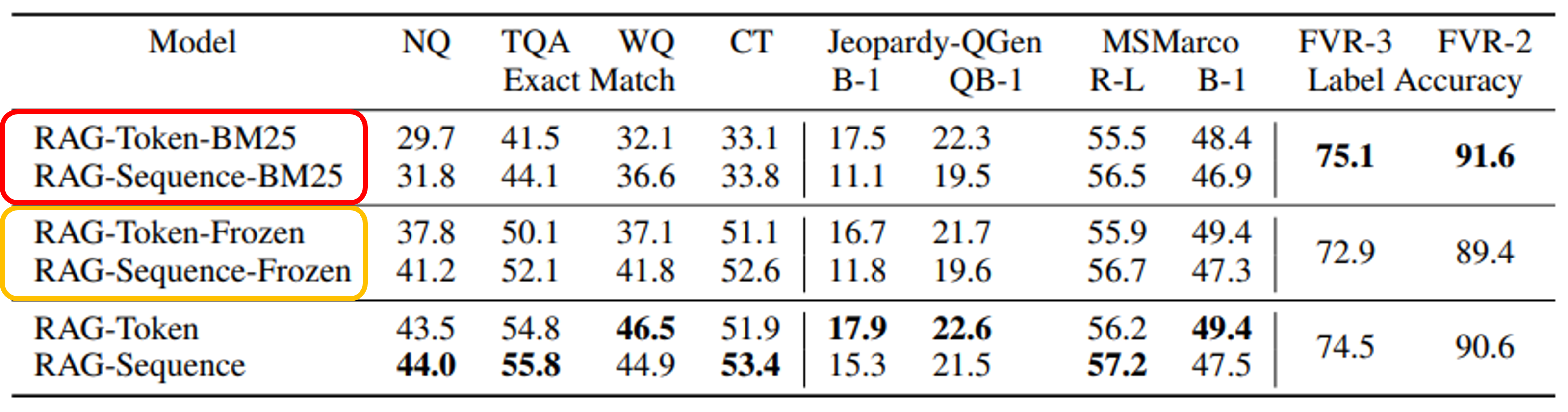
- 빨간색 : retriver를 BM25로 교체한 경우
- 대부분은 성능이 하락, but FEVER에서는 높은 성능을 보임
- fact verification은 의미 정보가 중요한 것이 아니라 실제 문서에서 중요 토큰의 등장 여부가 중요함
- 주황색 : retriver를 freeze한 경우. 즉, generator만 학습
- 대부분에서 성능이 떨어지는 것을 확인할 수 있다. 즉, retriever 또한 학습하는 것이 좋다!
- 빨간색 : retriver를 BM25로 교체한 경우
-
# Retrieved Passages
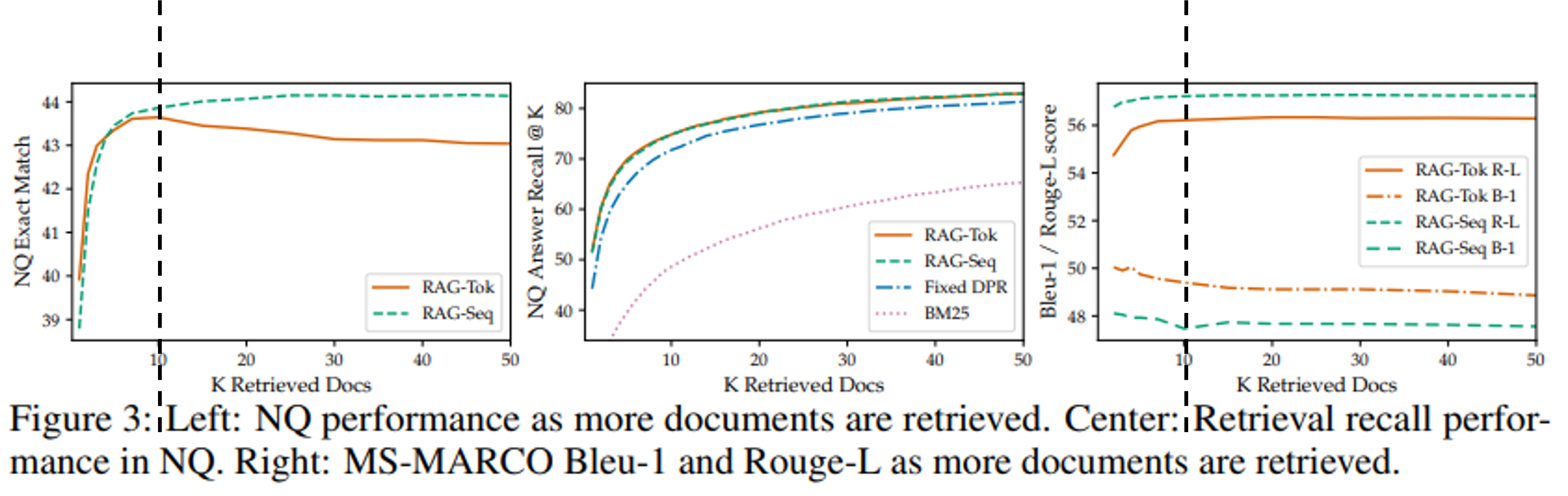
- 왼쪽 및 가운데 그림
- RAG-S의 경우, 검색되는 문서의 수 ↑ - 성능 ↑
(하지만, saturation 현상이 보임) - RAG-T의 경우, 검색되는 문서의 수가 일정 수준 이상이 되면 성능 저하 발생
- 검색되는 문서의 수가 일정 수준 이상으로 늘릴 수 없는 scaling 제한 문제가 있음
(추후, FiD에서 어느 정도 해결된다고 한다)
- 검색되는 문서의 수가 일정 수준 이상으로 늘릴 수 없는 scaling 제한 문제가 있음
- RAG-S의 경우, 검색되는 문서의 수 ↑ - 성능 ↑
- 오른쪽 그림
- RAG-T, RAG-S 모두 검색되는 문서의 수가 증가하면 Rouge-L은 증가, Blue-1은 감소
- abstractive answer generation의 경우 많은 passage가 필요하지 않음을 의미
- 논문에서는 제한된 외부 지식을 효과적으로 이용하는 것이라고 말하지만, 뒤집어서 생각하면 사실 그냥 많은 외부 지식을 활용하지 못하는 거 같다,,
- RAG-T, RAG-S 모두 검색되는 문서의 수가 증가하면 Rouge-L은 증가, Blue-1은 감소
- 왼쪽 및 가운데 그림
Conclusion
-
Retriever-Reader 구조에서 Retriver-Generator로 진화
- retriever를 통해 non-parametric memory에 접근할 수 있고, generator를 통해 parametric memory에 접근할 수 있는 hybrid 구조
- 그 결과 생성된 답변의 diversity↑, hallucination↓
- task-agnostic
- ODQA → KIT
-
외부 지식의 사용
- 언어 모델의 생성 결과에 더 많은 해석 및 통제 가능
- 하지만, 위키피디아 또는 다른 외부 지식 출처는 완전히 사실적, 비편견적임을 보장할 수 없음
