
PreRequisite
- RAG(Retrieval-Augmented Generation)
- retriever과 generator를 결합한 프레임워크
- 질문에 답하기 위해 모델의 내부 지식만을 바탕으로 답을 하는 것이 아니라 외부 지식 소스를 이용하여 답 가능
- hallucination ↓
- Personalized-dialogue Generation
- 대화형 AI 모델이 사용자의 성격, 취향, 과거 대화 등을 반영한 개인 맞춤형 응답을 생성하는 task
Research Background
ConvAI2 Dataset
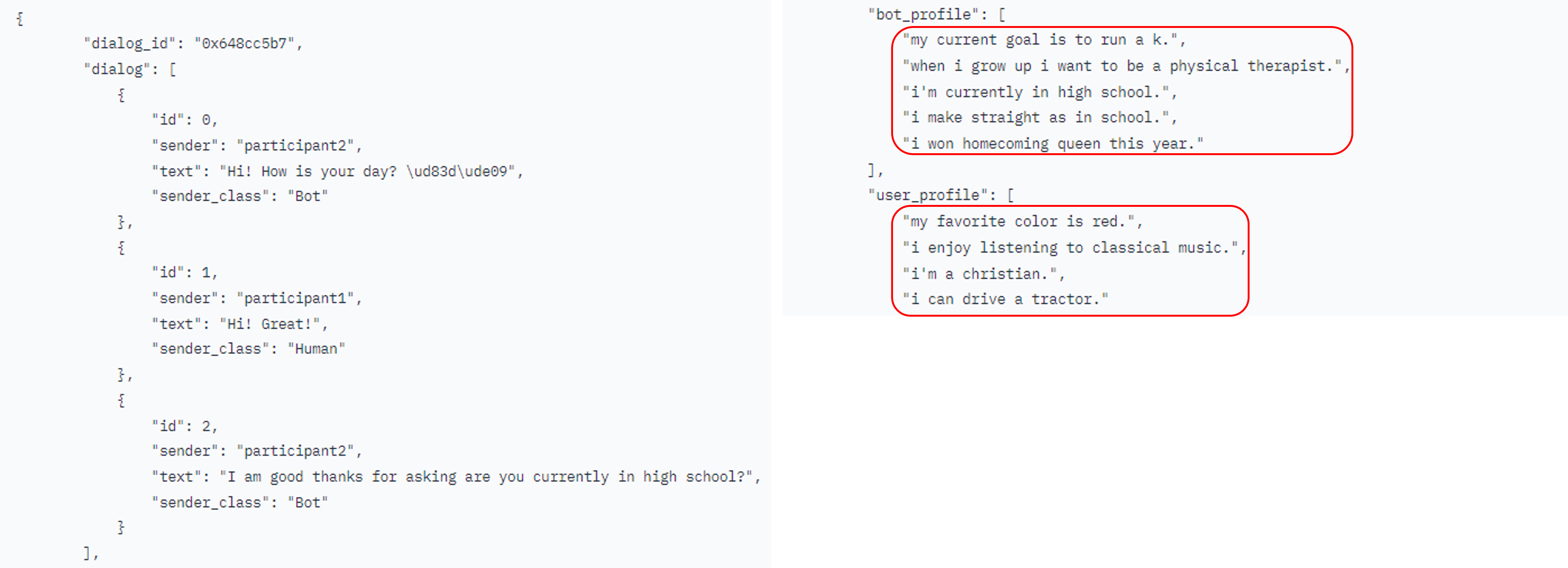
- personalized dialogue generation의 경우, historical context와 pre-defined persona를 바탕으로 일관된 응답의 생성을 목표로 함
- 하지만, ConvAI2 데이터셋의 경우 persona를 담고 있는 문장이 4~5개밖에 안됨
→ 다양하고 풍부한 답변의 생성이 어려움
ROCStory

- ROCStory는 title에 대한 story가 주어져있는 데이터셋으로 저자는 해당 데이터셋을 통해 persona profile을 풍부하게 만들 수 있을 것이라고 생각
- 그럼에도 불구하고 ROCStory라는 외부지식을 어떻게 주입할 수 있을지가 문제
1) 검색해오기 위한 명시적 주석 부족
2) story 검색 성능 평가의 어려움
3) dense retriever 자체의 문제점
: dense retriever의 경우 예측된 확률분포가 기반이 됨
→ 주어진 query에 대한 검색해오는 문서가 대체로 비슷하기 때문에 다양한 문서를 긁어올 수 없게 됨
Model Architecture
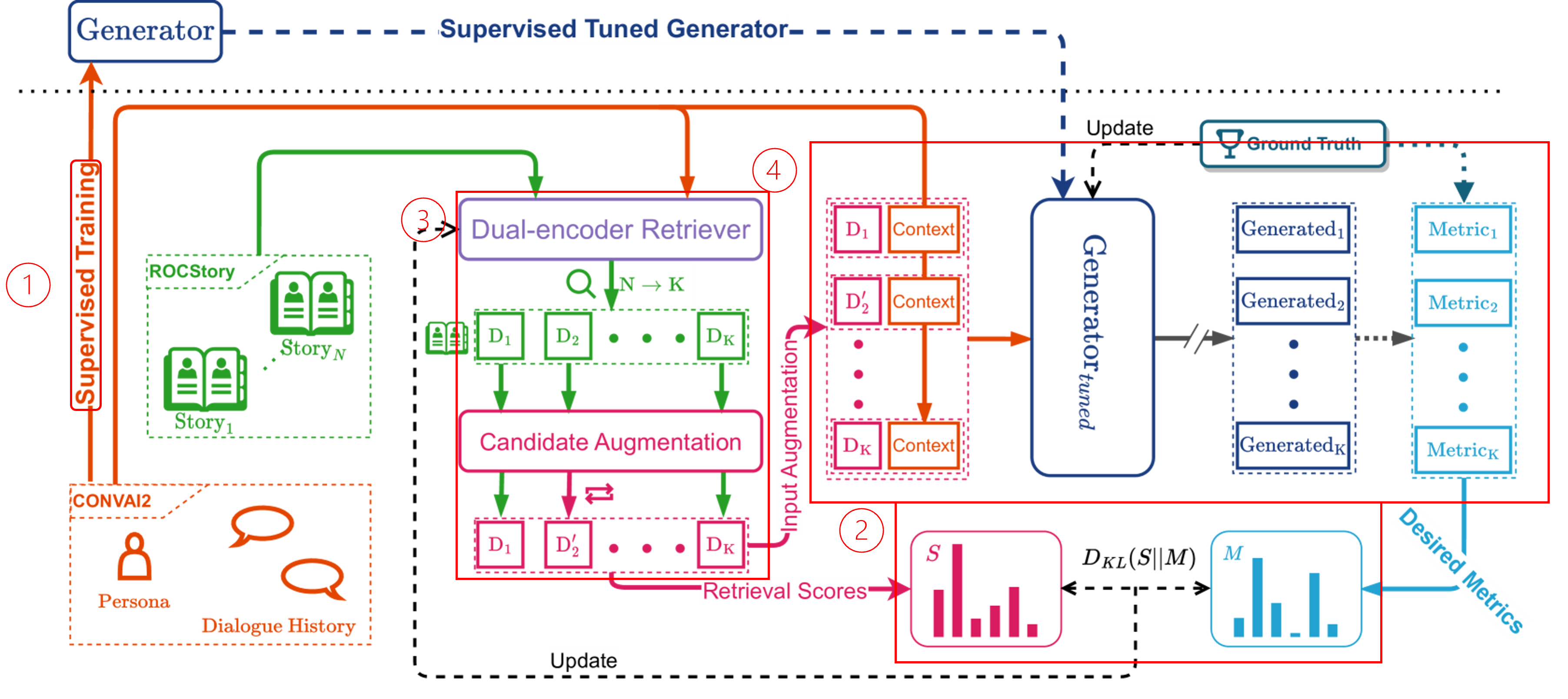
Two-stage training process
: training generator → tune the retriever + learn the retrieval augmentation
1. Train the Generator
- generator를 supervised training
- NLL(Negative Log-Likelihood)를 minimize하는 방향으로 generator를 supervised fine-tuning
- architecture 그림 ①에 해당함

2. Learning Retrieval Augmentation
- retriever를 tuning하는 단계
- retriever를 업데이트하기 위해서는 retrieved content(=story)와 최종 생성된 response와의 직접적인 연결관계 필요
- supervised generator를 evaluator로 설정
- metric은 BLUE, ROUGE-L, F1의 총합
- metric 계산이 미분 불가능하기 때문에 확률 분포로 변환
- evaluator 입장에서 검색된 문서가 유용하다고 판단되면 높은 rank를 가지도록 또한 크게 만듦
- retriever에 의해서 반환된 유사도 점수 와 간의 KL Divergence를 최소화하는 방향으로 학습이 진행
- 은 metric의 확률 분포들의 값
- architecture 그림 ②에 해당함
- retriever를 업데이트하기 위해서는 retrieved content(=story)와 최종 생성된 response와의 직접적인 연결관계 필요
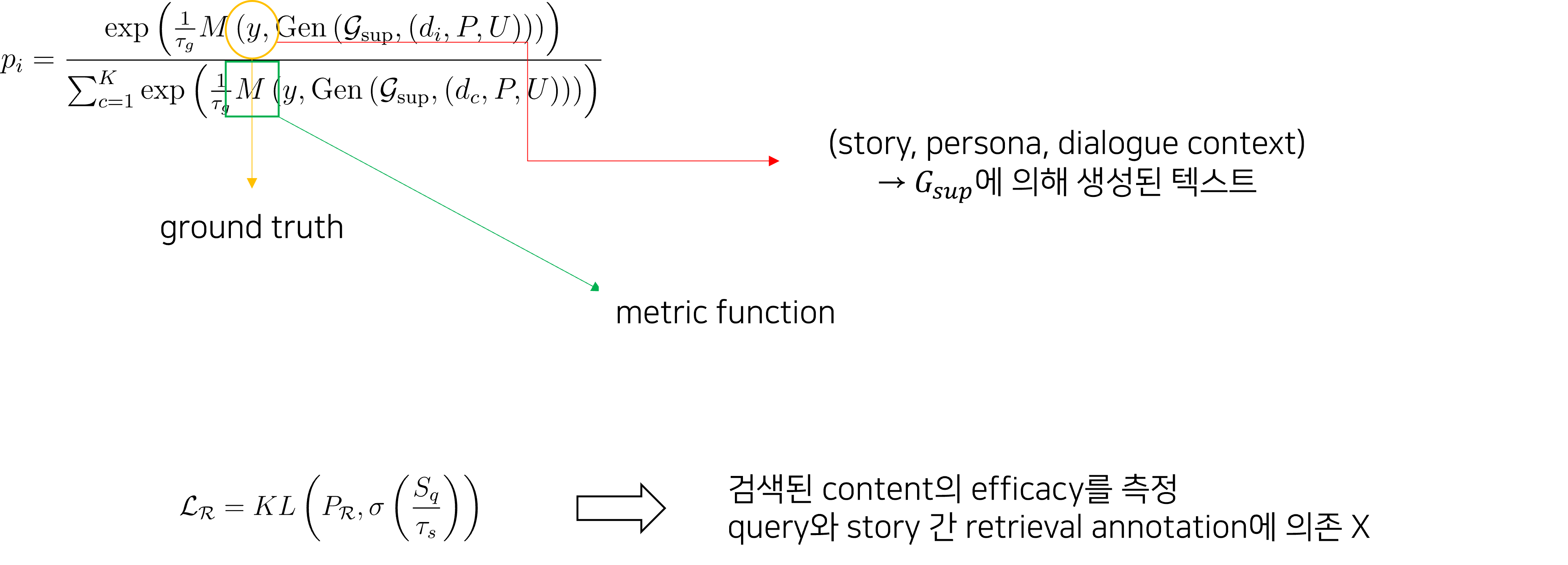
3. Retrieval Candidate Augmentation
- 정해진 문서 후보에만 국한되지 않도록 문서의 다양성을 높이기 위한 방법
- 확률 에 따라 각 문서를 무작위로 대체
- 실제 학습에서는 값이 0.5로 사용됨
- 대체된 문서 집합 와 쿼리의 유사도인 구함
- 2단계에서와 마찬가지로 검색 증강 학습 적용
- 3단계는 검색 증강 학습이 이루어지는 2단계에서 jointly하게 일어남
- 확률 에 따라 각 문서를 무작위로 대체

4. Training Retrieval-Augmented Generator
- 1단계에서 generator를 supervised training하는 것과 큰 차이는 없음
- 다만, input에 검색된 문서가 결합된다는 점이 주요한 차이점
- 해당 단계 이후, retriever와 generator를 jointly하게 학습
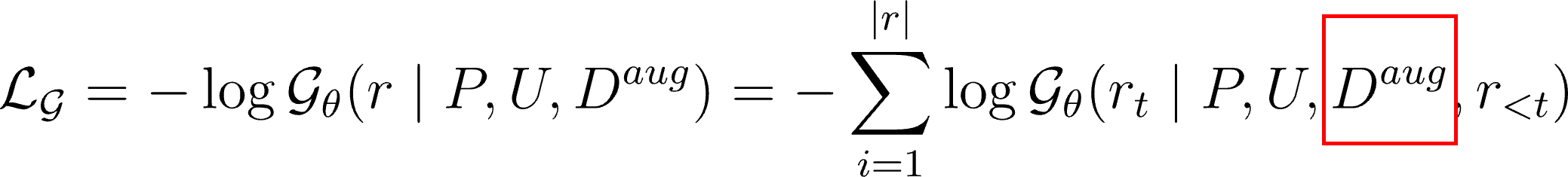
Experiment
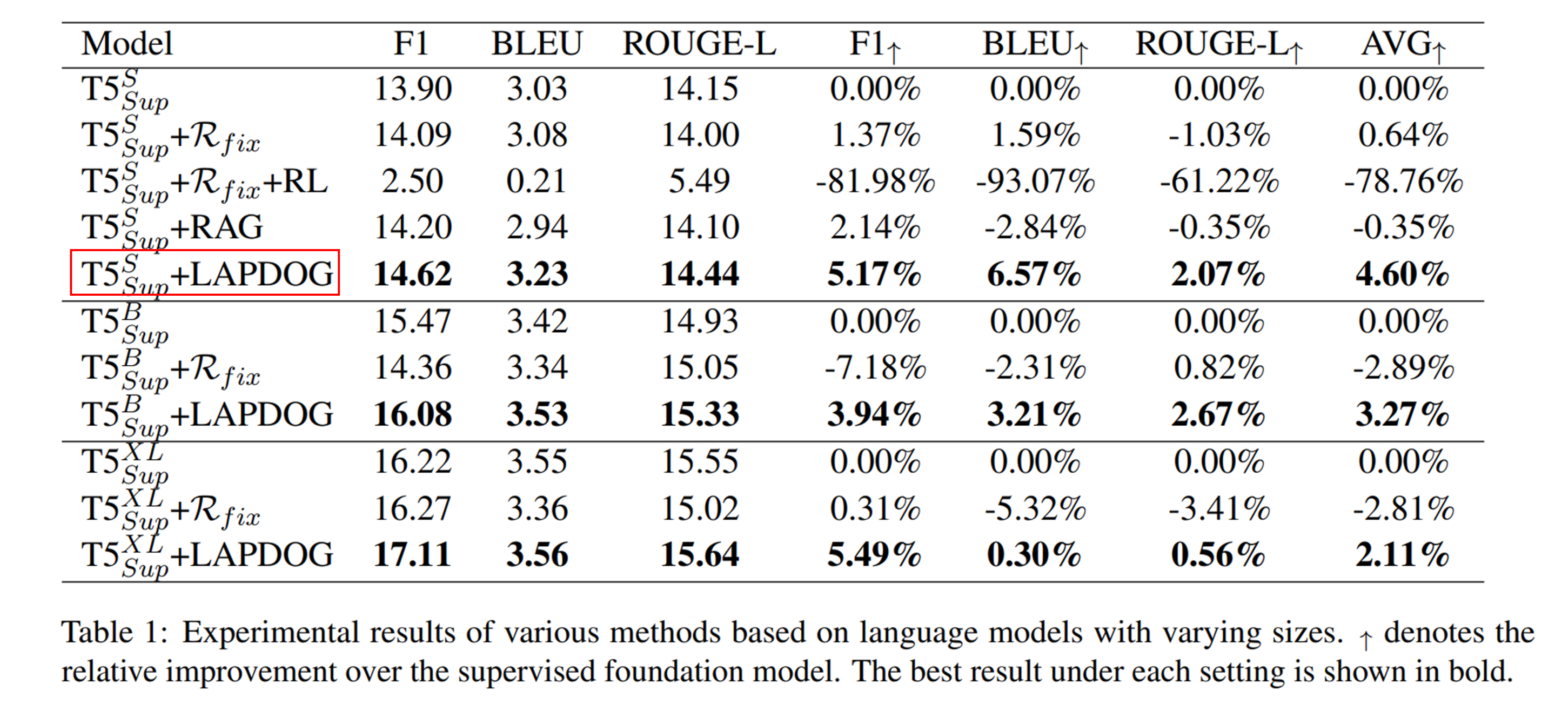
- 모든 지표에서 LAPDOG을 결합한 모델이 제일 성능이 좋음
- 모델 사이즈와 상관없이 일관적으로 향상됨
- retriever : Contriever
- BERT와 유사한 dual-encoder retriever
- generator : T5
- retriever : Contriever
Ablation Studies
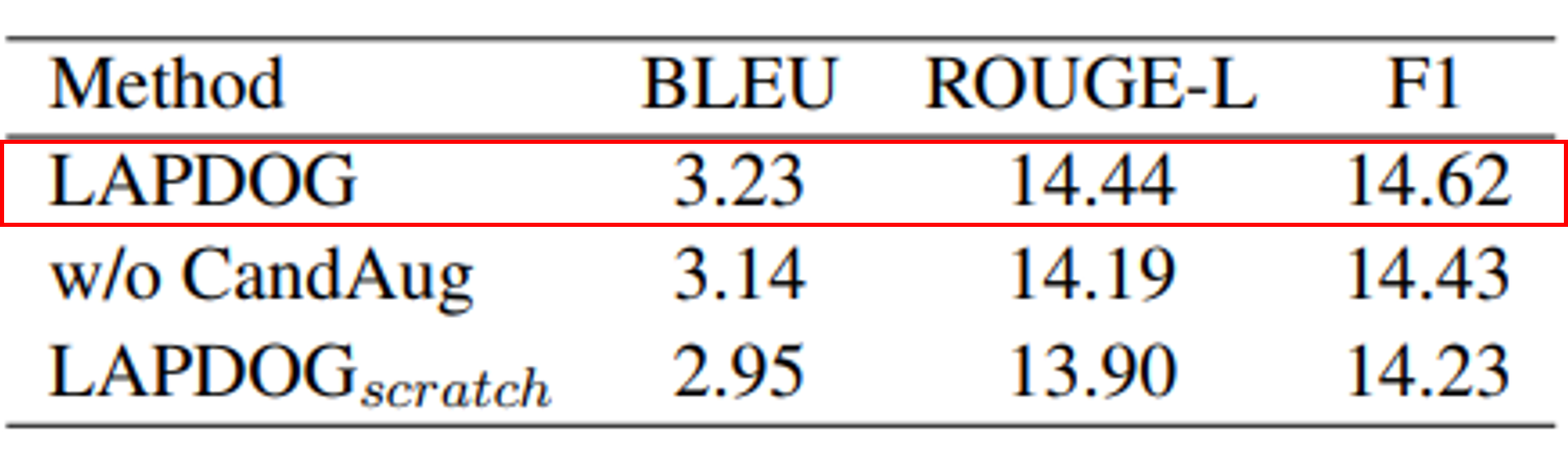
- CandAug가 없을 경우 성능이 전반적으로 하락
- LAPDOG는 첫 번째 단계(Train the Generator) 생략한 경우
→ 마찬가지로 성능이 하락
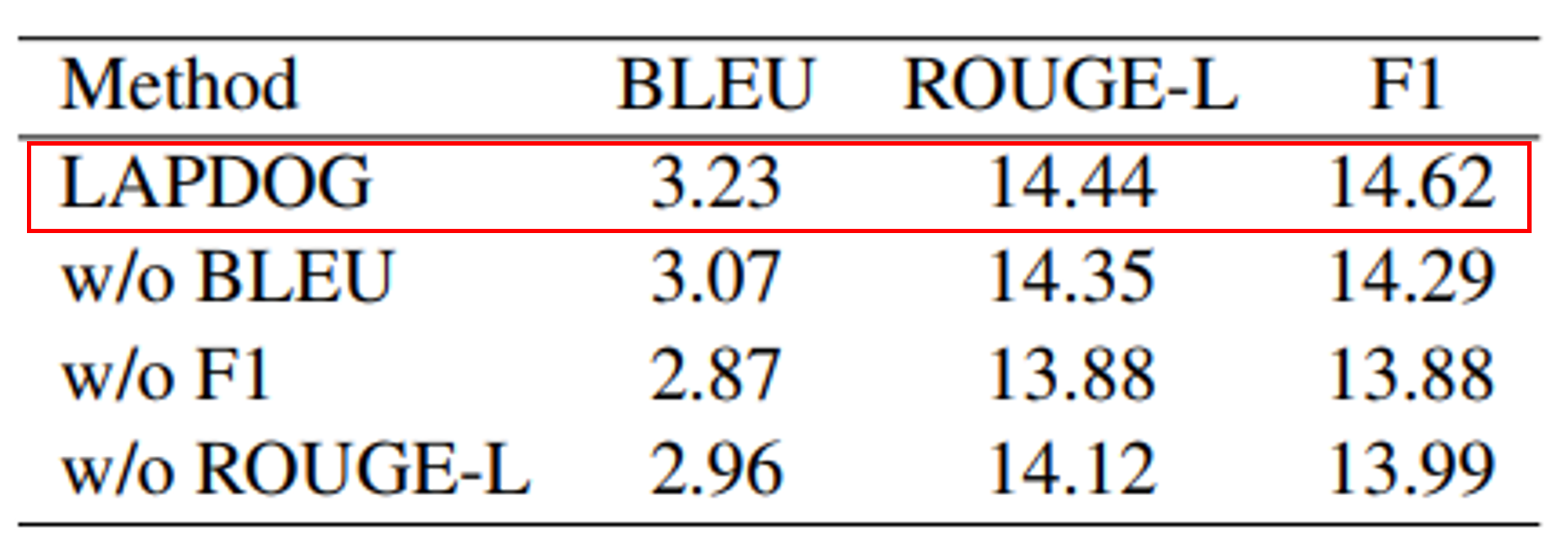
- metric에서 BLEU, F1, ROUGE-L을 각각 하나씩 제거하며 모델 성능 측정
- BLEU가 없을 경우 : 성능이 전반적으로 다 떨어짐
- BLEU가 응답 생성의 정확한 일치에 기여함
- F1이 없을 경우 : BLEU에 비해 성능이 더 크게 떨어짐
- F1이 생성된 응답과 실제 정답 간의 단어 중첩을 보장하는 데 기여함
- ROUGE-L이 없을 경우 : 성능이 전반적으로 다 떨어짐
- 생성된 대화의 일관성을 평가함에 있어서 ROUGLE-L의 중요성 확인
- BLEU가 없을 경우 : 성능이 전반적으로 다 떨어짐
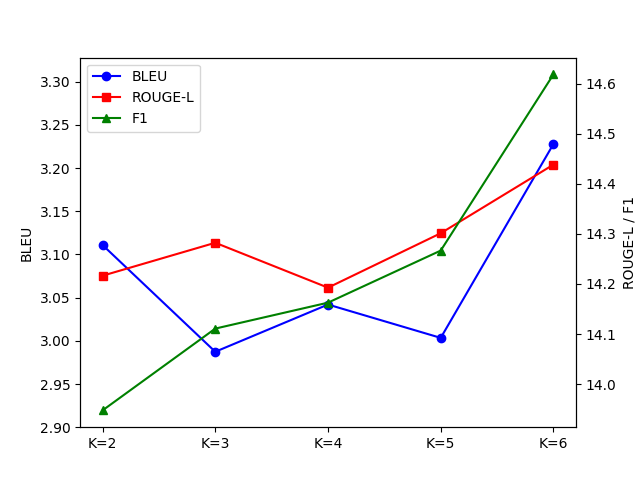
- 문서 candidate의 수가 증가하면 성능이 늘어나기는 하지만 단조 증가 X
- 때문에 적절한 수의 문서를 선택하는 것이 중요함
- 너무 적은 수의 candidate는 충분한 정보를 제공하지 못함
- 너무 많은 수의 candidate는 무관한 정보를 제공함으로써 오히려 성능을 저하시킬 수 있음
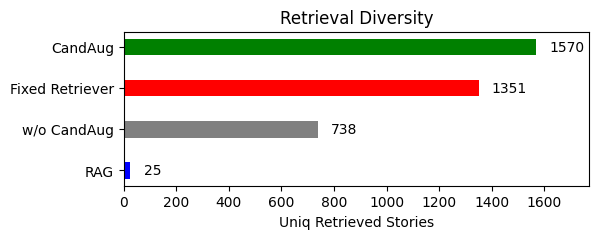
- candidate augmentation을 하는 것이 다양한 검색을 해오는 데 도움
→ 이는 더 개인화되고 문맥적으로 풍부한 답변을 생성할 수 있게끔 함

stick-to-it-iveness