[논문 리뷰] Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
RAG
목록 보기
9/12

NAACL 2024
Summary
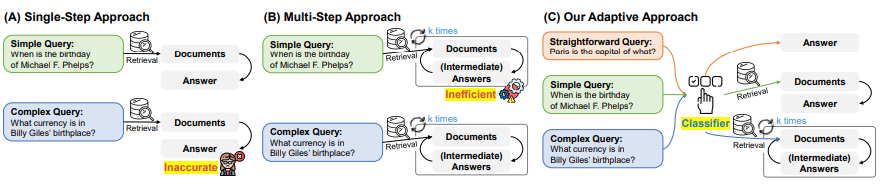
질의의 복잡도를 평가할 수 있는 분류기를 통해 반복적 검색 증강, 단일 단계 검색 증강, 검색을 사용하지 않은 방법 적용
Related Work
Adaptive Retrieval
단일 모델에 의존한 적응형 검색 방식은 다양한 복잡도를 가진 질의를 효과적으로 처리하는 데 최적이 아닐 수 있음
→ 모든 질의에 대해 지나치게 단순하거나 복잡한 방식을 적용하는 경향이 있기 때문
Method
Adaptive-RAG: Adaptive Retrieval-Augmented Generation
Adapting Retrieval-Augmented LLMs
LLM과 Retriever의 작동 방식은 입력과 관계 없이 일정하게 유지됨
즉, 내부 모델 아키텍처나 파라미터를 변경하지 않고도 다양한 복잡도의 질의 사이를 원활하게 오갈수 있음
Query Complexity Assessment
- 분류기
- 생성 모델보다 작은 언어 모델
- 분류 레이블
- A
- 검색 없이 LLM 스스로 답할 수 있음을 의미
- B
- 단일 단계 검색이 필요함을 의미
- C
- 다단계 검색이 필요함을 의미
- A
Training Strategy
- 데이터셋 형성 방법
- 정답을 맞춘 더 단순한 방법으로 레이블을 할당
예를 들어, 가장 단순한 비검색 기반 접근법이 정답을 올바르게 생성한다면, 해당 질의에 대한 레이블은 A로 할당
- 질의에 대한 레이블을 할당하는 과정에서 다수의 모델이 정답을 맞춘다면, 더 단순한 모델에 우선순위 부여
예를 들어, 단일 단계 검색 접근법과 다단계 검색 접근법이 동일한 정답을 생성하는 반면, 비검색 기반 접근법이 실패하는 경우, 해당 질의에는 B 레이블 할당 - 하지만, 세 접근법 모두 다 정답을 생성하지 못하는 경우, 레이블이 할당 X
첫 번째 레이블링 단계 이후에도 정답을 생성하지 못한다면, single-hop 데이터셋의 질의에는 B 레이블을, multi-hop 데이터셋 질의에는 C 레이블 할당
- 정답을 맞춘 더 단순한 방법으로 레이블을 할당
→ 이후, Cross-Entropy Loss를 바탕으로 질의의 복잡도 학습
Experimental Settings
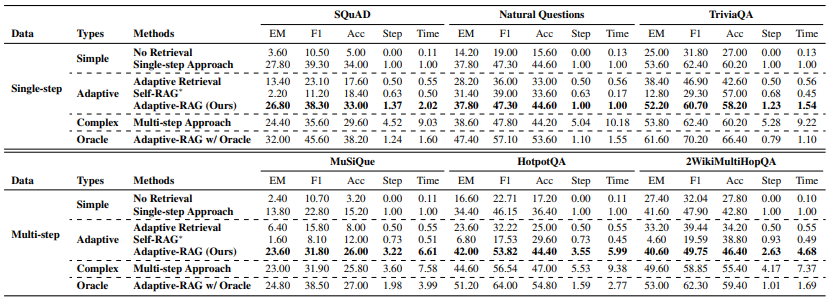
Datasets
Single-hop QA
SQuAD v1.1, NQ, TriviaQA
Multihop-QA
MuSiQue, HotpotQA, 2WikiMultiHopQA
Models
- Simple
- No-Retrieval
- Single-step Approach
- Adaptive
- Adaptive Retrieval(Mallen et al., 2023)
- Self-RAG
- Adaptive-RAG (ours)
- Complex
- 반복적으로 Retriever와 LLM을 호출 및 CoT 방법론을 적용한 방법(Trivedi et al., 2023)
서로 다른 범주의 모델들은 직접적으로 비교할 수 없지만, Adaptive 접근법이 Simple 범주의 모델들보다 더 효과적이면서 Complex 모델들보다는 더 효율적이어야 함. 그래서, Adaptive-RAG Oracle 버전도 있음
그러니까, 실제 환경에서는 사용할 수는 없지만, 질의의 복잡도를 100% 정확하게 예측하는 분류기가 있을 경우, Adaptive-RAG의 최대 성능이 어느 정도인지 평가하기 위함
Evaluation Metrics
- 효과성
- F1, EM, ACC
- 효율성
- 검색-생성 횟수
- 첫 번째 검색-생성에서 질의에 답변하는 데 걸리는 평균적인 시간
Implementation Details
- 검색 모델
- BM25
- 생성 모델
- gpt-3.5-turbo-instruct
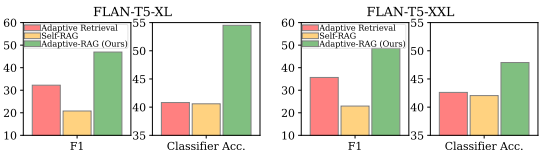
- FLAN-T5-XL, XXL
- 분류 모델
- T5-Large
- 외부 지식 소스
- single-hop
- DPR에서 전처리한 위키피디아 덤프
- multi-hop
- IRCoT에서 전처리한 위키피디아 덤프
- single-hop
Experimental Results and Analyses

stick-to-it-iveness