[논문 리뷰] DRAGIN: Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language Models
RAG
목록 보기
10/12
2024 acl-long
Backgrounds
- Dynamic RAG
텍스트 생성 과정에서 검색 시점과, 검색 내용을 능동적으로 결정 단일 검색에 의존하는 것이 아닌 보통 여러 차례 검색을 수행- 한계
- 검색 시점을 결정하는 전략은 종종 고정된 규칙에 의존
a. 불필요한 검색 증강이 LLM에 관련 없는 데이터나 노이즈를 추가하여 검색 품질 저하
b. LLM 추론 과정에서 연산 비용이 증강 - 검색 내용을 결정하는 전략은 일반적으로 가장 최근 문장이나 마지막 몇 개의 토큰에만 한정됨 (LLM의 정보 요구는 전체 문맥에 걸쳐 있을 수 있음)
- 검색 시점을 결정하는 전략은 종종 고정된 규칙에 의존
- 관련 연구
- IRCoT: 생성되는 각 문장마다 검색을 수행하는 전역 증강 방식. 최신 생성 문장을 검색 질의로 설정함
- RETRO, IC-RALM: 슬라이딩 윈도우를 정의하고, 일정 개수의 토큰이 처리되었을 때 검색 모듈을 활성화하여, 마지막 N개의 토큰을 질의로 사용함
- 한계
DRAGIN
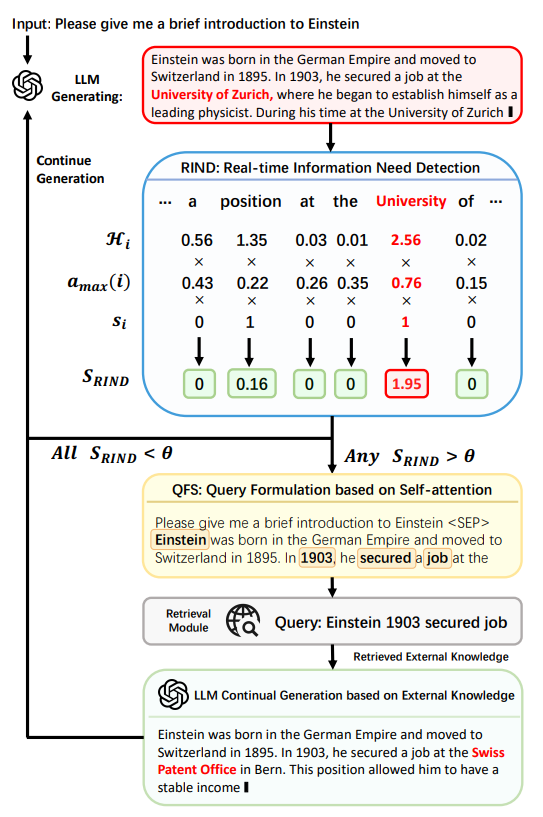
LLM의 정보 요구에 따라 검색 시점과 검색 내용을 결정
별도의 추가 학습이나, 파인튜닝, 프롬프트 엔지니어링 없이도 모든 트랜스포머 기반 LLM에 쉽게 적용할 수 있는 경량의 RAG 프레임워크
- 검색 시점 결정
- RIND(Real-time Information Needs Detection)
- LLM이 스스로 생성한 내용에 대한 불확실성, 각 토큰이 후속 토큰에 미치는 영향력, 그리고 각 토큰의 의미적 중요성을 종합적으로 고려
- 검색 쿼리 구성(=검색 내용 결정)
- QFS(Query Formulation based on Self-Attention)
- 전체 문맥에 걸친 LLM의 self-attention을 활용하여 쿼리 구성을 혁신적으로 개선
Methodology
RIND
각 토큰의 불확실성, 의미적 기여도, 이후 문맥에 미치는 영향을 종합적으로 평가하여 검색 활성화 여부를 결정
- 각 토큰의 불확실성 정량화
-
- 출력 시퀀스 집합
- 특정 토큰 에 대한 엔트로피로서, 는 위치 에서 LLM이 단어 집합 V 내의 토큰 를 생성할 확률을 의미함
- 이후 문맥에 미치는 영향력 정량화
- Attention Matrix 계산
- : 쿼리 행렬
- : key 행렬
- : key 벡터의 차원 수
- Maximum Attention Value 계산
→ 특정 토큰 가 이후 문맥에 미치는 상대적인 영향력을 측정
- 각 토큰의 의미적 기여도 정량화
- 불용어를 필터링하여 의미적으로 중요한 토큰에 집중
- : 불용어 집합
- 불용어를 필터링하여 의미적으로 중요한 토큰에 집중
QFS
RIND에 의해 검색 위치가 결정되면, 해당 위치에서 검색을 위한 쿼리 재구성
Self-Attention 정보를 활용하여 모델이 가장 중요하게 여긴 부분을 자동으로 추출하여 검색 쿼리를 구성함
- 마지막 트랜스포머 레이어에서 Attention Score 추출
- 특정 토큰 를 생성할 때, 이전 토큰 중 어떤 것이 중요했는지를 Attention Weight를 분석함으로써 파악 가능
- Attention Score 정렬
- 를 내림차순으로 정렬하고, 가장 높은 점수를 받은 토큰 N개 선택
- 를 생성하는 데 가장 중요한 역할을 한 토큰들을 선별 및 추출
- 최종 검색 쿼리 구성
- 선택된 단어들을 원래 텍스트 순서대로 배치하여 검색 쿼리 생성
⇒ 단순히 마지막 문장이나 몇 개의 토큰을 쓰는 방식보다 전체 문맥을 고려하는 방식이 LLM이 실제로 필요로 하는 정보를 더 정확하게 검색할 수 있음
Continue Generation after Retrieval
- LLM이 생성하는 도중 외부 정보가 필요하면 RIND 모듈이 감지하여 검색을 수행
- QFS 모듈이 검색 쿼리를 생성하고, 검색 모델이 외부 데이터베이스에서 관련 문서를 가져옴
- LLM의 기존 생성 결과를 검색이 감지된 위치에서 잘라내고(truncate), 검색된 정보를 반영하여 생성 다시 시작
- 이후에도 필요할 때마다 반복적으로 검색 및 생성이 진행

Experimental Setup
Datasets
- 멀티홉 추론
- 2WikiMultihopQA
- 메트릭: EM, F1, Precision
- HotpotQA
- 메트릭: EM, F1, Precision
- 2WikiMultihopQA
- 읽기 이해
- IIRC
- 메트릭: EM, F1, Precision
- IIRC
- 일반 상식 추론
- StrategyQA
- 메트릭: EM
- StrategyQA
Baselines
- wo-RAG(without RAG)
- SG-RAG(Single Round RAG)
- FL-RAG(Fix Length RAG)
- N개의 토큰이 생성될 때마다 검색 수행
- FS-RAG(Fix Sentence RAG)
- 고정된 문장 단위로 검색 수행
- FLARE
- 불확실한 토큰을 감지할 때마다 검색 수행
- 검색 모듈이 활성화되면, 생성된 문장에서 불확실한 토큰을 제외한 마지막 문장을 쿼리로 정의
- 불확실한 토큰을 감지할 때마다 검색 수행
Selected LLMs
- LLaMA2-chat-7B, 13B
- Vicuna-13B-v1.5
Implementation Details
- 하이퍼파라미터
- Appendix E 참조
- Retriever
- BM25
- 일부 밀집 검색 모델보다 더 우수한 성능을 보였다는 연구 결과
- SGPT(Muennighoff, 2022)
- SOTA 밀집 검색 모델
- BM25
- 불용어 처리
- Spacy 라이브러리 en_core_web_sm 언어 모델 활용
- 외부 지식 코퍼스
- Wikipedia
- 100개 토큰 단위로 분할하여 검색에 활용
- Wikipedia
Results
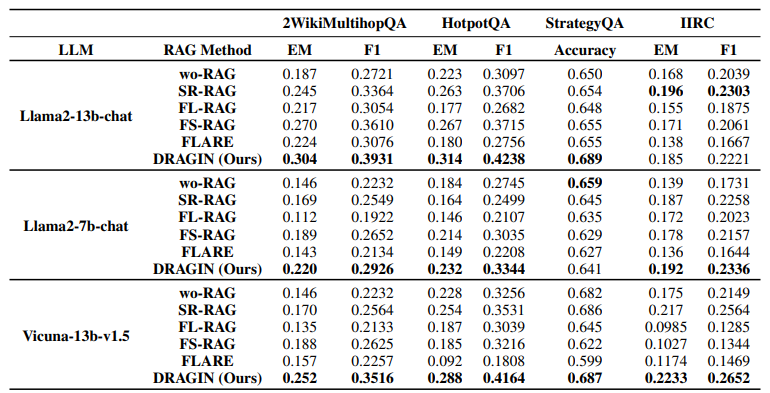
- wo-RAG < SR-RAG
- FL-RAG, FS-RAG 방식이 항상 SR-RAG 방식보다 뛰어나지는 않음
즉, 잘못된 시점에 검색 증강이 이루어질 경우, LLM의 출력 품질 향상에 기여하지 못할 수도 있음을 보여줌
- FLARE는 데이터셋에 따라 성능 편차가 큼
FLARE의 검색 증강 시점 결정 방식이 최적과는 거리가 멀다는 것을 의미함
- DRAGIN이 대부분 LLM 및 데이터셋에서 뛰어난 성능을 보임
심지어, 멀티홉 QA에서 더욱 더 큰 향상

stick-to-it-iveness