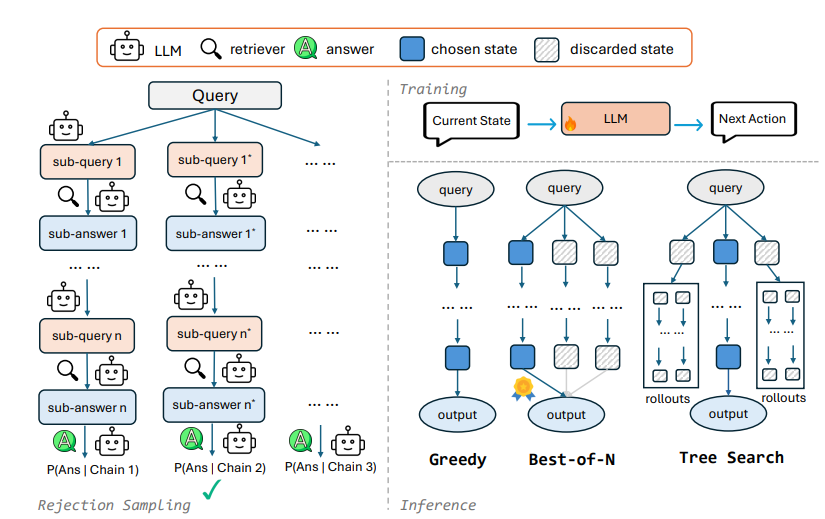
문제 정의
- Retrieval-Augmented Generation(RAG)
- 외부 지식 소스에서 질문과 관련된 정보를 검색하여 맥락으로써 결합
→ LLM이 학습 당시 보지 못한 질문에 답변할 수 있게 만듦 - 하지만, 생성 프로세스 전에 단 한 번의 검색만 수행
→ 복잡한 질의에 효과적으로 대응하는 데 한계
- 외부 지식 소스에서 질문과 관련된 정보를 검색하여 맥락으로써 결합
CoRAG
중간 검색 체인을 통해 LLM의 반복적인 검색과 추론을 수행하는 프레임워크
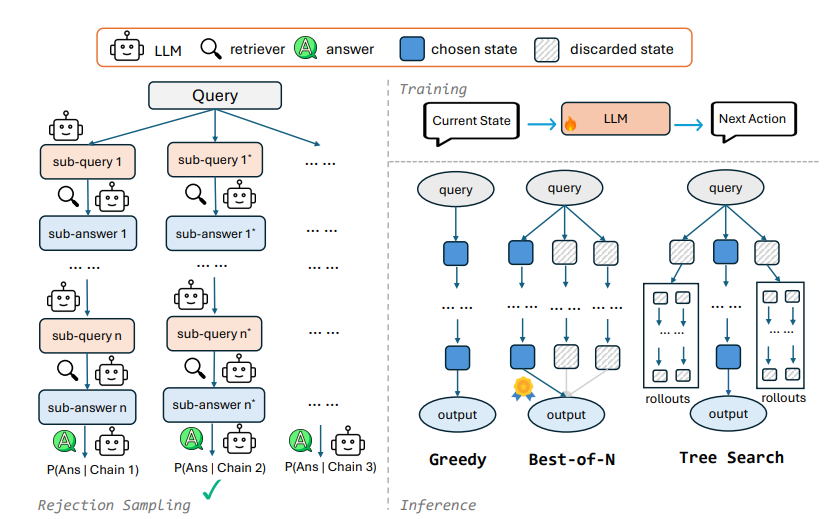
1. 거부 샘플링(rejection sampling)을 통해 검색 체인 자동 생성
-
검색 체인 생성 과정
사전에 정해둔 체인 길이 에 도달하거나, 서브 답변 가 정답 와 일치할 때까지 반복- LLM으로 쿼리를 해결하기 위해 가장 먼저 물어봐야 할 서브 쿼리 생성
- 생성된 로 top-k 문서 검색한 후, 검색 증강 생성을 통해 생성
- + →
- 생성된 를 바탕으로 다음 질문 생성
-
거부 샘플링을 통한 데이터셋 구축
- LLM으로 위와 같은 과정을 반복적으로 거쳐 체인을 여러 개 생성하고, 품질이 가장 괜찮은 체인을 하나 고름
- 모델 훈련
- 구축된 데이터셋을 바탕으로 모델이 하위 질의, 답변, 그리고 최종 답변 생성하는 법을 학습
- 독점 모델로부터의 지식 증류나, few-shot 프롬프팅에 의존 X
- 다양한 디코딩 전략
계산량과 모델 성능 간의 trade-off를 고려하여 선택
- Greedy Decoding
- 매 단계에서 가장 그럴 듯한 질문과 답변을 뽑아서 바로바로 진행
- 속도 上, 정확도 下
- 매 단계에서 가장 그럴 듯한 질문과 답변을 뽑아서 바로바로 진행
- Best-of-N Sampling
- 매 순간 서로 다른 N개의 검색 체인을 만들어보고, 그 중 가장 좋아보이는 걸 골라서 답 생성
- 속도 中, 정확도 中
- 매 순간 서로 다른 N개의 검색 체인을 만들어보고, 그 중 가장 좋아보이는 걸 골라서 답 생성
- Tree Search
- 각 단계마다 여러 가지 질문들을 뽑아보고, 여러 갈래로 펼쳐서 탐색 ... (BFS)
- 속도 下, 정확도 上
- 각 단계마다 여러 가지 질문들을 뽑아보고, 여러 갈래로 펼쳐서 탐색 ... (BFS)
Experiment Settings
-
태스크, 데이터셋, 메트릭
- 멀티홉 QA
- 2WikiMultihopQA, HotpotQA, Bamboogle, MuSiQue가 통합
- EM, F1
- KIT(Knowledge-Intensive Task)
- KILT 벤치마크 서브 샘플링
- 모델의 예측 결과를 공식 평가 서버에 제출한 후, 숨겨진 테스트 세트에서 다운스트림 지표 보고
- 멀티홉 QA
-
생성 모델
- Llama3.1-8B-Instruct
- 각 데이터셋에 맞게 각각 따로 훈련
- Llama3.1-8B-Instruct
-
검색 모델
- E5-large
- KILT 벤치마크의 경우, 검색기도 이에 맞춰 미세 조정
- E5-large
-
검색 문서
- KILT에서 제공하는 위키피디아 덤프
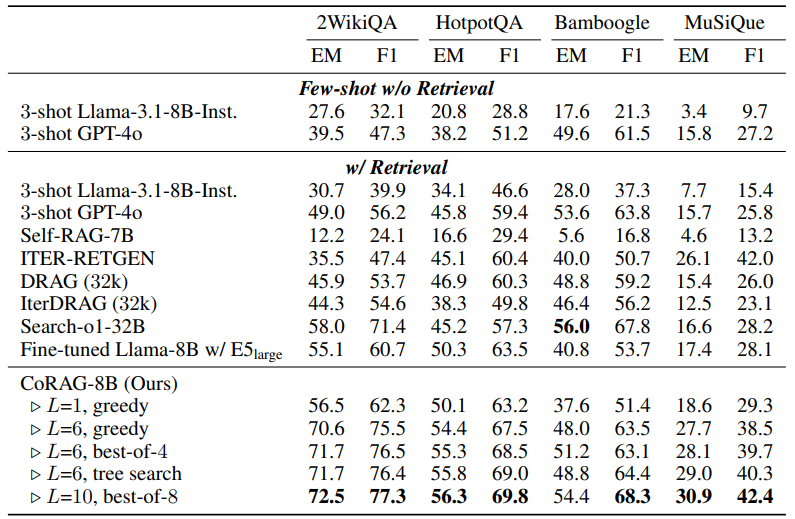
멀티홉 QA
Bamboogle를 제외한 모든 데이터셋에서 모든 베이스라인 모델들을 상당히 능가
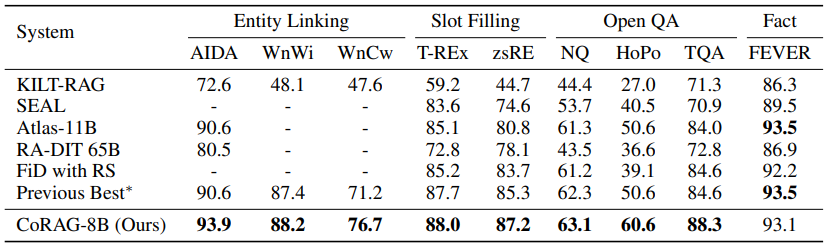
KIT
FEVER를 제외하고는 SOTA의 성능을 찍음
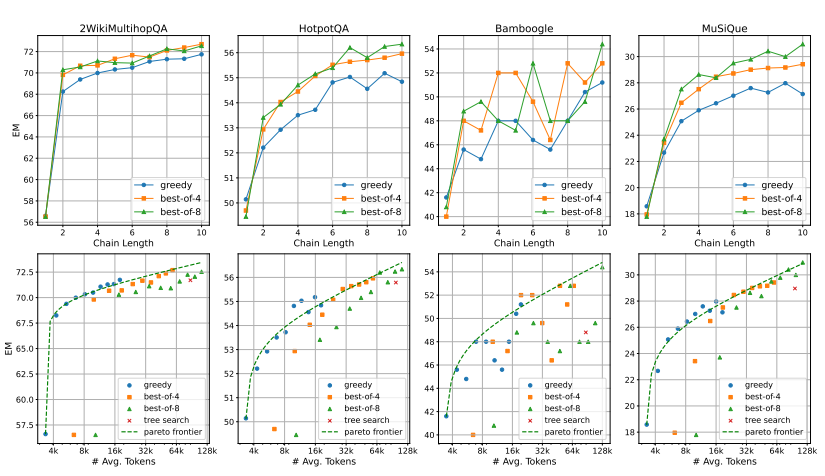
Scaling Test-Time Compute
OpenAI o1과 유사하게 모델 가중치를 업데이트하지 않고도 테스트 시점에 계산량을 확장하여 더 나은 성능을 달성할 수 있도록 설계
이 커질수록 성능 향상이 둔해지며, N을 증가시키는 효과는 데이터셋마다 상이함
- : 검색 체인의 길이
- : Best-of-N에서 샘플링할 체인의 개수
즉, 토큰을 더 쓰고, 검색을 더 쓴다고 해서 무조건 성능이 오르지 않음
태스크, 데이터셋마다 상이함

stick-to-it-iveness