Problem Defintion
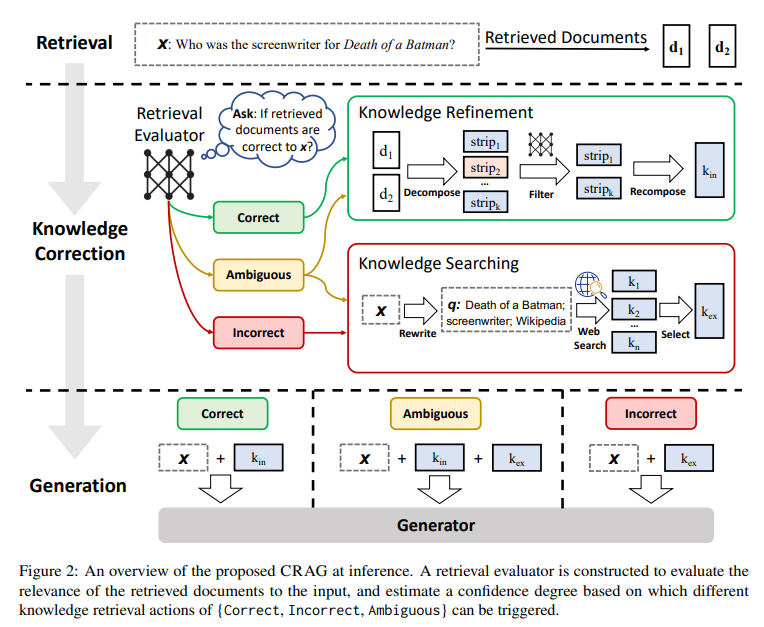
LLM 응답의 정확성은 내재하고 있는 지식만으로는 보장할 수 없기 때문에 환각 현상이 발생
이를 해결하기 위해 RAG가 등장했지만, RAG의 효과는 검색된 문서의 관련성 및 정확성에 달려있음
(검색된 지식에 대한 과도한 의존)
하지만, 전통적인 RAG 기법들은 관련성 검사 없이 고정된 수의 문서들을 무차별적으로 검색
→ "검색이 잘못됐다면 어떡할 건데?"
CRAG
검색 모델의 결과를 스스로 고치고, 문서 활용도를 개선하여 생성 품질을 향상시킬 수 있는 구조
기존 다른 RAG 구조에 비해 검색의 성능이 떨어지더라도 비교적 성능이 덜 떨어짐 (생성의 견고함)
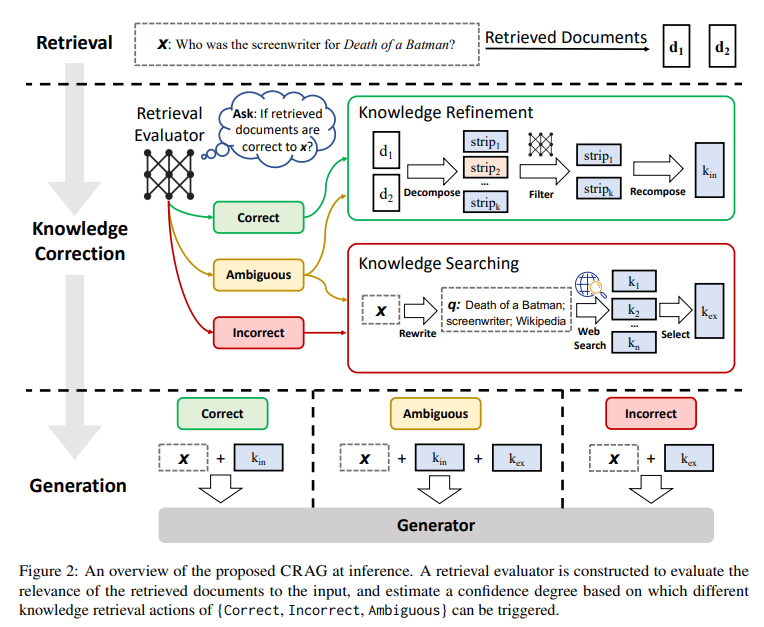
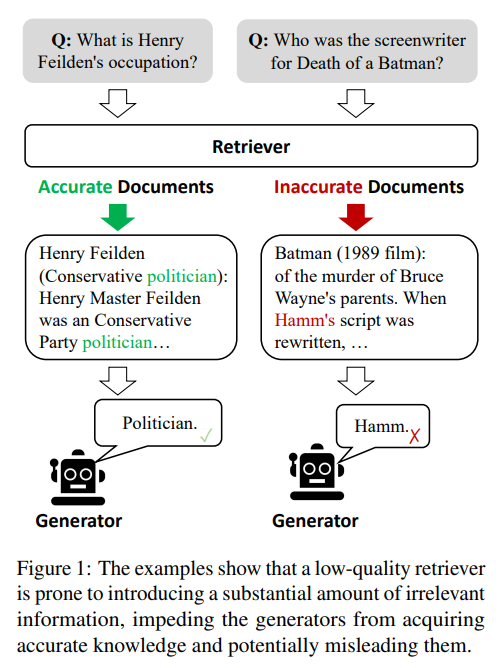
- 가벼운 검색 평가 모델(lightweight retrieval evaluator)
T5-large(0.77B)로 초기화 및 미세 조정
무관한 문서를 검색해올 경우 고치는 것이 주된 목표
문서의 관련성 점수를 매겨서 점수에 따라 {Correct, Incorrect, Ambiguous} 작업을 트리거
- Correct
- 지식 정제(Knowledge Refinement)
- 분해 후 결합(decompose-then-recompose): 지식 분해(decompose), 걸러내기(filter), 재구성(recompose) 과정을 거쳐 불필요한 정보는 제거하고 가장 중요한 정보만을 남김
- 지식 정제(Knowledge Refinement)
- Incorrect
- 지식 검색(Knowledge Searching)
- 질의 재작성(rewrite): ChatGPT를 활용해 키워드로 구성된 질의로 재작성
- 웹 검색(web search): 상용 웹 검색 API(e.g. 구글 API)를 사용해 각 질의에 대해 일련의 url 링크를 생성해 콘텐츠를 가져옴 (top-5)
- 선택(select): Correct에서의 지식 정제 과정을 거쳐 중요한 정보만을 가져옴
- 지식 검색(Knowledge Searching)
- Ambiguous
- Correct, Incorrect 작업들의 혼합
-
플러그 앤 플레이(plug-and-play) 방식
다양한 RAG 기반 접근 방식과 매끄럽게 결합될 수 있음 -
단문/장문 생성 작업 전반에서의 일반성 입증
실험 및 결과
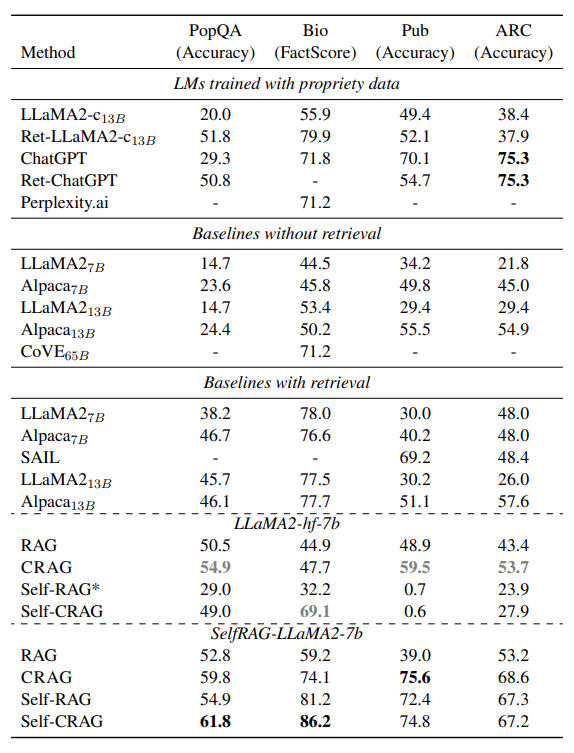
- 단문 생성
- 데이터셋: PopQA
- 평가지표: accuracy
- 장문 생성
- 데이터셋: Biography
- 평가지표: FactScore
- 진위 판단
- 데이터셋: PubHealth
- 평가지표: accuracy
- 다지선다 추론
- 데이터셋: Arc-Challenge
- 평가지표: accuracy
한계점
외부적인 평가 모델을 도입해야하며, 검색 평가 모델을 미세조정하는 것이 불가피함

stick-to-it-iveness