
Search-R1
COLM 2025
논문 링크
DeepSeek-R1의 확장 모델로,
강화학습만을 통해 LLM이 단계적으로 reasoning을 수행하면서 다수의 검색 쿼리를 자율적으로 생성하고, 실시간 검색 결과를 활용할 수 있는 프레임워크
배경
Search-and-Reasoning 시나리오에 강화학습을 적용할 때 다음과 같은 도전들이 존재
- RL Framework and Stability
강화학습이 안정적으로 최적화될 수 있는가? - Multi-Turn Interleaved Reasoning and Search
multi-turn 상황에서 어떻게 동적으로 검색 전략을 수정 및 수행할 것인가? - Reward Design
보상 함수를 어떻게 효과적으로 설계할 것인가?
방법
-
검색 엔진을 환경의 일부로 모델링
검색 토큰을 마스킹함으로써 강화학습 훈련을 최적화(PPO, GRPO의 경우, 기본적으로 LLM에서는 토큰 별로 loss가 계산된다고 함. 그런데, LLM이 생성하지 않은 검색 결과에 대해 loss를 적용하면 의도치 않게 학습이 수행될 수 있어 검색 결과에 대해서는 loss masking을 통해 loss를 계산하지 않는 듯)
-
multi-turn retrieval/reasoning
- <search></search>: 검색 호출
- <information></information>: 검색 결과 삽입
- <think></think>: LLM의 추론 과정
- <answer></answer>: 최종 정답
-
process-based reward가 아닌, outcome-based reward 사용
최소한의 보상 설계를 바탕으로 검색 기반 추론 시나리오에서 효과적임을 보여줌
(실제로 최근 연구에서는 강화학습을 통해 LLM이 결과 기반 보상만으로도 고도화된 추론 능력을 학습할 수 있음을 보여주었지만, 이러한 접근 방식이 검색 엔진 호출 시나리오에 적용될 수 있는 가능성은 아직 충분히 탐구되지 않음)
Reward Modeling
Deepseek-R1에서 format reward를 주었지만, 본 논문에서는 주지 않았음
→ 모델이 이미 구조적인 형식을 충분히 잘 따르고 있기 때문에, 보다 복잡한 형식 보상의 탐색은 향후 과제로 남겨둠
작동 과정

Main Results
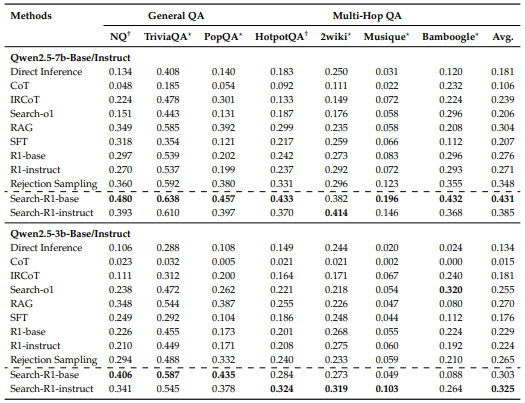
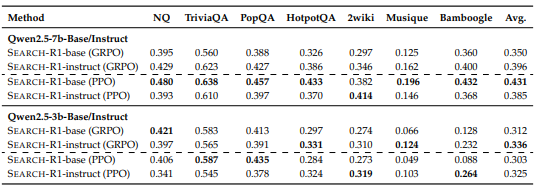
- GRPO > PPO
- Instruct Model에 강화학습을 적용하는 것이 그냥 base model을 훈련하는 것보다 더 빨리 최적화됨
(하지만, 최종 성능은 유사함) - 검색 결과에 마스킹을 적용한 것이 그렇지 않은 것보다 성능이 좋음
R1-Searcher
arXiv 2025.03.07
논문 링크
훈련 과정 중 외부 검색 환경과 직접 상호작용하도록 하여,
LLM이 검색을 학습하고 활용할 수 있도록 2단계 결과 기반 강화학습 방식을 적용한 프레임워크
해당 프레임워크가 적용한 2단계 결과 기반 강화학습 방식은 다음과 같음:
- 1단계: 검색 보상 사용
최종 정답의 정확도는 고려하지 않고, 검색 행위를 유도하기 위한 보상 사용
- 2단계: 정답 보상 사용
모델이 외부 검색 시스템을 효과적으로 활용하여 문제를 정확히 해결하는 능력 학습
배경
기존 LRM의 한계
강화학습을 통해 언어 모델의 추론 능력 향상에 기여했지만, 주로 내부 지식에 의존하기 때문에,
시의성이 요구되거나 지식 집약적인 질문을 마주치는 상황에는 매우 취약함
기존 RAG 연구의 한계
- 프롬프트 기반 접근: 주로 폐쇄형 모델에 의존해 실용성이 떨어짐
- SFT 기반 증류: 해결 경로를 암기하게 만들어 일반화 성능이 떨어짐
- MCTS 기반 추론 확장 방식: 효과적이지만, 추론 속도 저하로 인해 실제 적용이 어려움
방법
Data Selection
검색 환경은 독립적이기 때문에, 모든 질문에 대한 적절한 정보를 포함하고 있지 않을 수 있음
→ 롤아웃 횟수, 즉 난이도에 따라 검색 시스템이 처리 가능한 질문을 선별
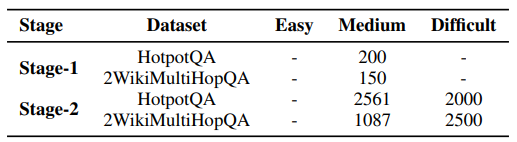

Two-Stage Outcome-based Reinforcement Learning
Reward Design
1단계: Retrieve Reward
검색하는 방법부터 익히자!
여기서 은 검색 호출 횟수
2단계: Answer Reward
검색하는 방법 익혔으니, 이걸 바탕으로 문제 해결 능력을 키워보자!
정답과 예측의 F1 점수라고 생각하면 됨
- : 예측 답변의 단어 수
- : 정답 답변의 단어 수
- : 정답 답변과 예측 답변의 공통되는 단어 수
Training Algorithm
Reinforce++ 알고리즘 기반
RAG 시나리오에 해당 알고리즘을 맞춤 적용하기 위해, 아래와 같은 두 가지 변형 방법들을 적용
-
RAG-based Rollout
<end_of_query>를 생성하면, 생성이 일시 중단
<begin_of_query><end_of_query> 태그를 사용하여 검색 도구 호출을 명시검색된 문서는 <begin_of_documents><end_of_documents> 태그로 감싸져 모델의 추론 과정에 통합

-
Retrieval Mask-based Loss Calculation
<begin_of_documents><end_of_documents> 에 해당하는 부분은 학습하는 동안 마스킹
→ 환경 효과를 줄이기 위함
Main Results
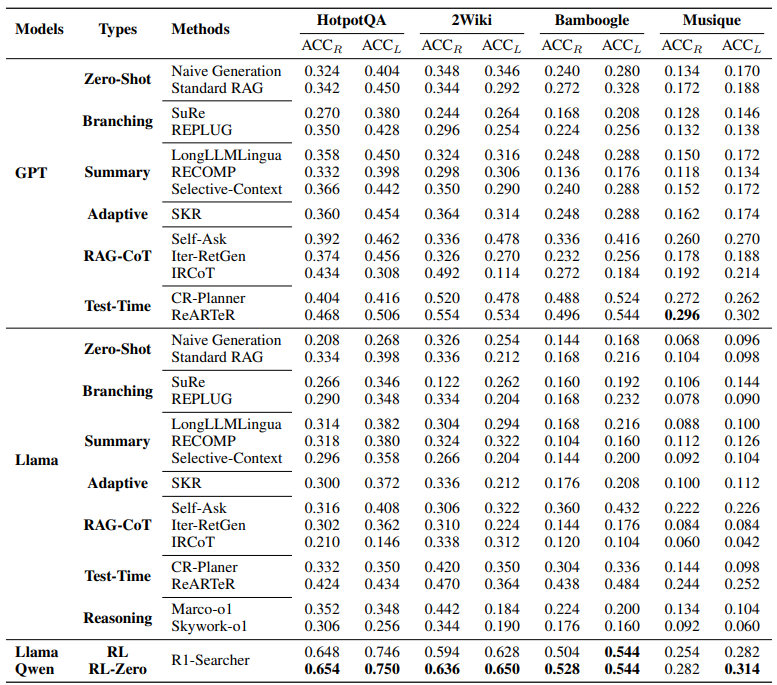
1. SFT 없이 강화학습만으로 멀티홉 QA에서 좋은 성능
2. 좋은 일반화 성능
→ 학습은 HotpotQA, 2Wiki에서 추출한 8천여개의 데이터로 진행했음에도, 다른 벤치마크 데이터셋에서도 좋은 성능을 보여주고 있음
ReSearch
arXiv 2025.03.25
논문 링크
강화학습을 통해 추론과 검색 간 상호작용을 학습
추론 단계에 대한 지도 학습 데이터 없이도 가능
연구 배경
Deepseek-R1과 같이, 규칙 기반 보상 함수가 LLM의 정교한 추론 패턴을 자율적으로 발전시키는 데 효과적으로 작용할 수 있음을 보여주었지만, 현재 접근 방식은 내부 추론 능력 향상에 초점을 맞추고 있으며, 이 추론 과정을 외부 지식 검색과 효과적으로 결합하는 방법에 대한 탐색은 제한적
방법
Reinforcement Learning
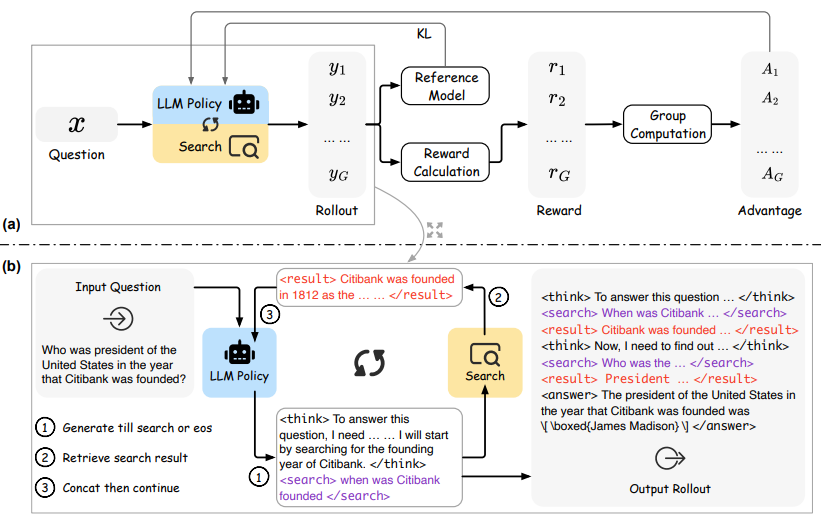
(a)와 (b)는 GRPO 파이프라인, 롤아웃 생성 과정을 각각 보여줌
여기서,
<search></search>: 검색 쿼리
<result></result>: 검색 결과
→ eos 토큰이 나올 때까지 concat
Training Template

Reward Modeling
Experiments
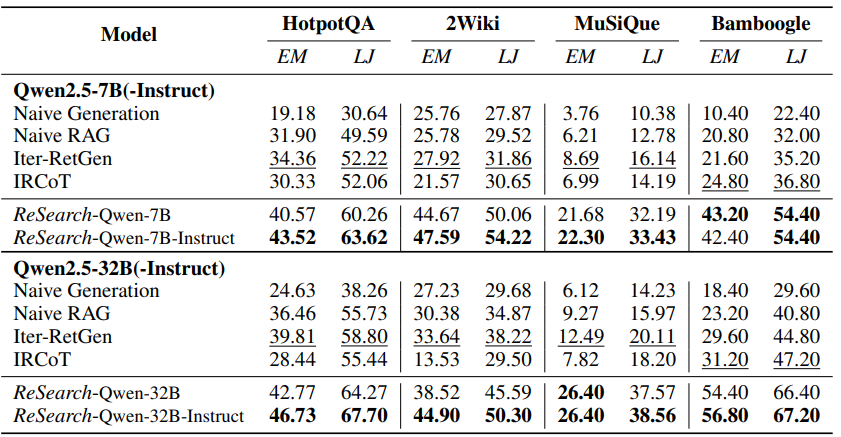
1. ReSearch가 전반적으로 모든 벤치마크에서 성능 향상을 보임
→ 심지어, MuSiQue 데이터셋에서만 학습이 진행됐지만, 다른 벤치마크에서도 성능이 좋았음
2. 베이스 모델보다는 instruct 모델이 성능이 더 좋음
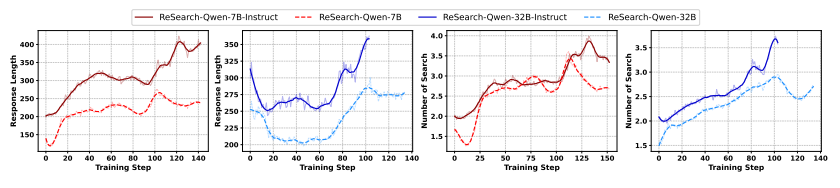 → 학습 단계에서의 응답 횟수 변화
→ 학습 단계에서의 응답 횟수 변화
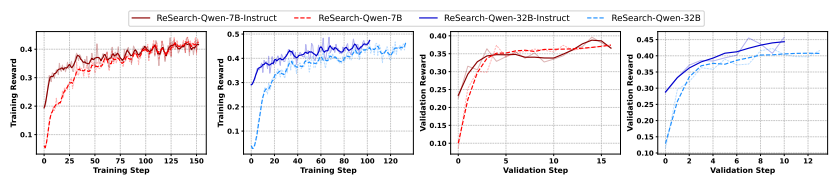 → 학습 및 검증 단계에서의 보상 변화
→ 학습 및 검증 단계에서의 보상 변화
ZeroSearch: Incentivize the Search Capability of LLMs without Searching
arXiv 2025.05.07
논문 링크
훈련 중 실제 검색 엔진과의 상호작용 없이도,
LLM이 검색 엔진을 활용하는 능력을 유도할 수 있는 프레임워크
문제
최근 연구들은 강화학습을 활용하여 LLM의 검색 능력을 향상
하지만,
- 통제 불가능한 문서 품질
검색 엔진이 반환하는 문서에 노이즈가 낄 수도 있어 문서의 품질이 예측 불가능
→ 학습 과정에 불안정성 유발 - 과도하게 높은 API 비용
강화학습 훈련은 반복적인 롤아웃을 필요로 하며, 이는 수십만 건에 이르는 검색 요청 수반 가능
→ 막대한 API 비용 초래 및 확장성 제한
방법
Reinforcement Learning without a Search Engine
- : 정책 모델
- : 참조 모델
- : 시뮬레이션 LLM(학습 중에는 고정된 상태로 유지됨)
- : 보상 함수
Training Template

Search Simulation Tuning

LLM에게 검색 결과처럼 쓰도록 지도학습
- 실제 검색 엔진 사용해서 학습 데이터 수집
LLM이 실제 검색 엔진을 통해 여러 번 검색하는 멀티턴 상호작용 로그 수집
예: 쿼리 → 검색 → 문서 → 답변 - 질의-문서 쌍 추출
로그에서 질의와 거기에 대해 검색된 문서들을 분리해서 쌍을 만듦 - 문서가 쿼리에 유용했는지 판단
LLM을 판별자로 써서, 각 문서가 질의에 답할 수 있을 정도로 충분한 정보를 담고 있는지 평가/라벨링- 답변 가능 → useful
- 답변 불가능 → noisy
- 경량 지도 학습 (SFT)
수집된 데이터를 바탕으로 LLM 학습
Rollout with Curriculum Search Simulation
훈련 난이도를 점진적으로 높이기 위해 생성되는 문서의 품질을 시간에 따라 점차 저하
구체적으로,
확률 함수 를 활용하여 노이즈 문서가 생성될 확률 조절
- : 초기 노이즈 확률
- : 최종 노이즈 확률
- : 현재 훈련 단계 수
- : 전체 훈련 단계 수
- : 기본적으로 4를 줌
즉, 훈련이 진행되면서 비율이 증가하고, 이는 의 증가를 야기하며,
이는 곧 노이즈 문서가 생성될 확률을 증가시킴
→ 정책 모델이 처음에는 기본 출력 형식과 작업 요구 사항 학습
→ 점차 더 어렵고, 노이즈가 더 많은 검색 상황에 적응할 수 있게 됨
Reward Design
- 정답 정확도만을 중점으로 둔 규칙 기반 보상 함수 설정
(EM의 경우, 정책 모델이 정답을 포함할 확률을 높이기 위해 불필요하게 긴 답변을 생성하는 경향을 보이는 일종의 리워드 해킹 발생)
- 즉, 그냥 F1 점수라고 생각하면 됨
- : 예측과 정답 사이의 겹치는 단어 수
- : 예측 응답 내 단어 수
- : 정답 응답 내 단어 수
- 즉, 그냥 F1 점수라고 생각하면 됨
- 출력 형식에 대한 보상은 부여하지 않았음 (별도의 감독 없이도 모델이 일관되게 잘 생성)
→ 논문 읽다 보니, 확실한 건 Qwen 모델 계열이 별도의 감독 없이도 그냥 잘 생성한다는 느낌을 받음
Training Algorithm
문서 토큰은 마스킹을 함으로써, 정책 모델이 직접 생성한 토큰에 대해서만 그레디언트 계산
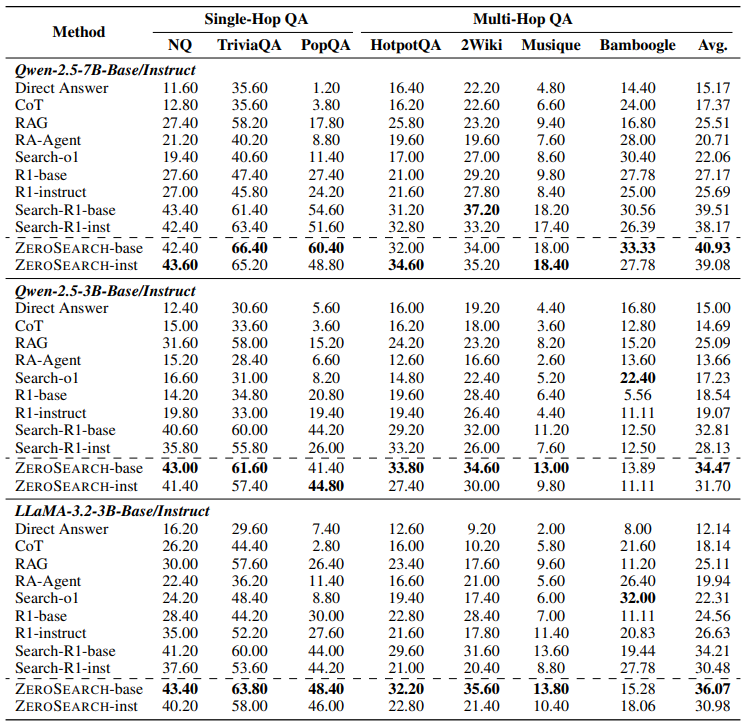
Main Results
Base Model
- Qwen-2.5-7B, Qwen-2.5-3B(Base/Instruct)
- LLaMA-3.2-3B
느낀 점
- 결과 기반으로 보상을 1~2개로 단순하게 줌
- 규칙 기반 보상 함수가 주를 이룸
- 이는 DeepSeek-R1 때문일 것으로 생각됨
- 하지만, 과정 기반으로 보상을 주는 RAG 프레임워크도 있을텐데,, 서베이가 필요함
- 규칙 기반 보상 함수가 주를 이룸
- 생각보다 학습 데이터의 양이 많지 않음
- R1-Searcher: HotpotQA, 2wikimultihopqa에서만 학습했는데도, 다른 벤치마크에서도 성능이 일괄적으로 상승
- ReSearch: MusiQue 데이터셋에서만 학습했는데도, 다른 벤치마크에서도 성능이 일괄적으로 상승
