Summary
Search-R1 이후, 여러 강화학습 기반 RAG 프레임워크가 등장했지만,
대부분 최종 정답만을 기반으로 보상을 주는 한계 (sparse reward의 문제)
이후로는 process-based reward를 도입하는 연구가 많이 등장
StepSearch
EMNLP 2025
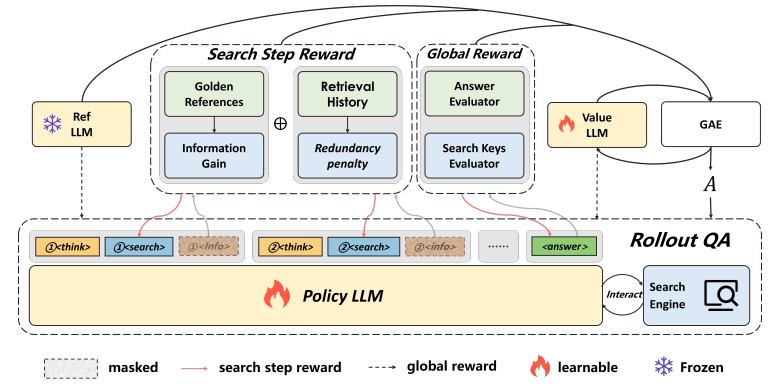
모델이 단순히 답만 맞히는 것이 아니라, 검색 전략 자체를 잘 설계하고 실행하도록 학습
→ 정교한 보상 설계 + 토큰 단위 과정 감독 (보통 PPO는 에피소드 단위, 즉 출력 전체에 보상)
방법론
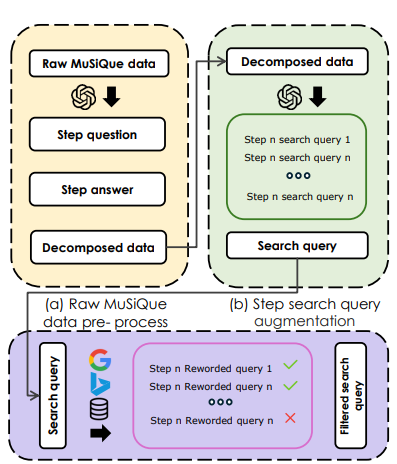
Data Augmentation
-
질문 분해 및 확장
GPT-4o를 활용하여 MusiQue 데이터의 복합 질문을 하위 질문-답변 쌍으로 변환
-
검색 쿼리 생성
각 하위 질문을 기반으로 N개의 검색 쿼리를 만들어 정보 검색에 활용
→ 서로 다른 표현이나 키워드를 사용하여 검색 다양성을 확보할 수 있음 -
검색 및 필터링
생성된 질문을 바탕으로 M개의 검색 엔진으로 검색 실행
→ 절반 이상의 검색 엔진으로부터 유효한 결과가 나오는 검색 쿼리만 유지
Train LLM with Search Actions
-
프롬프트 설계
→ 생각-검색-정보-답변이라는 일관된 절차를 따르게 함

-
롤아웃 과정
- <think></think>: 내부 추론 단계
- <search></search>: 검색 쿼리 생성
- <information></information>: 검색 결과 입력
- LLM이 <answer></answer>를 출력하거나, 액션 예산이 소진되면 중단
- 마스킹을 통한 학습 집중
늘 그렇듯, <information></information> 구간은 그레디언트 계산에서 제외
보상 설계
-
Type 1 Reward: Global Signal
-
형식 요구사항
- <search></search> 쌍 안의 검색 쿼리만 추출되어 검색 도구 호출에 사용되며, 정답은 <answer></answer> 쌍 안에 위치해야 함
- 최소 한 번 이상의 think 및 search 동작을 포함해야 함
- 질문에 대한 답변은 오직 하나의 <answer></answer> 태그 쌍으로 작성하며, 반드시 마지막에 위치
-
Answer Reward
-
-
Search Keys Reward
- 모델이 만든 쿼리와 아까 만들었던 검색 쿼리들과의 F1 점수 계산
- 가장 높은 F1 점수를 선택
(하위 질문에 대해 모델이 만든 최고의 쿼리 품질) - 롤아웃을 하며 만들어진 모든 하위 질문에 대해 평균 계산하여 보상 로 줌
-
-
Type 2 Reward: Search Step
(정보 이득 - 중복 패널티)
-
정보 이득
- 개의 문서 검색
- 각 골드 문서와 검색된 문서들의 코사인 유사도 계산
- 이번 턴에서 가장 유사한 문서를 찾고, 이전 턴까지의 최고 유사도와 비교
- 이전보다 더 높아진 부분만 정보 이득으로 기록
-
중복 패널티
- 이전에 본 문서를 또 가져오면 그만큼 점수를 깎아서, 모델이 새로운 정보를 찾게 만듦
-
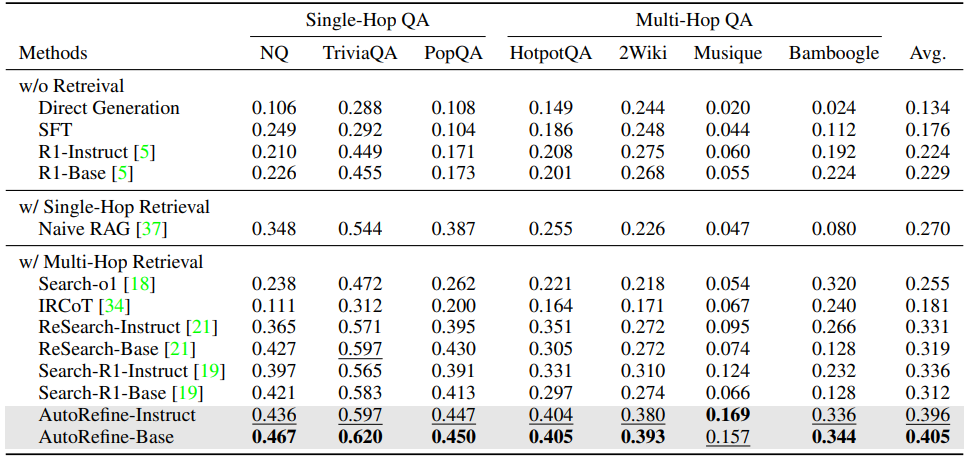
Main Results
R3-RAG
EMNLP 2025 (Findings)
방법론
단계별 학습
-
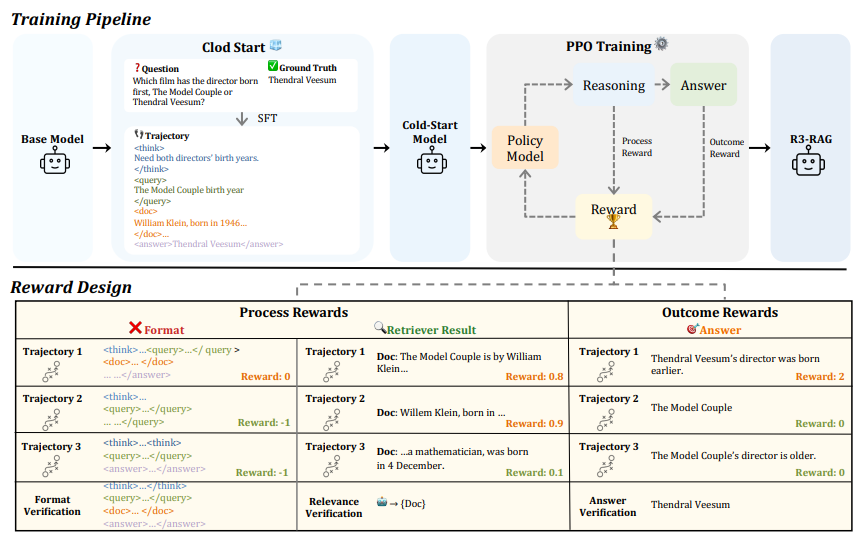
Cold Start (SFT)
모델이 단계별 추론 + 검색을 하는 습관을 먼저 가르치는 예열 단계
질문 하나당, 추론과 검색이 오가는 과정 + 예측 정답이 세트로 기록되며, 틀린 정답으로 끝나는 경로는 제거
→ 잘못된 추론 습관이 학습 데이터에 들어가지 않게 하기 위함 -
RL
하지만, Cold Start는 모델이 외부 검색 환경을 충분히 탐색하기 어렵기 하므로, 강화학습을 통해 관련성 높은 외부 지식을 더 잘 검색하는 능력 강화
보상 방식
Answer Correctness + Document Relevance + Format Correctness
-
Answer Correctness
→ 모델의 추론 경로가 정답에 도달했는지 평가하는 결과 보상 함수
(단순 문자열 매칭 외에도 모델 기반 판단도 도입) -
Document Relevance
→ 모델이 사용자 질문과 관련성 높은 문서를 검색하도록 유도하는 과정 보상 함수
-
Format Correctness
늘 그렇듯, 포맷 맞았냐 안 맞았냐로 점수 준다고 생각 -
과정 보상 조정
→ 다른 보상들로 인해 정답 정확도 기반 보상의 효과가 약해지지 않도록 함
- 정답이 올바른 경로의 경우:
- 정답이 틀리거나, 과도한 사고로 답변 생성에 실패한 경우:
- 형식 오류가 있는 경로의 경우:
→ 형식 오류는 특정 스텝에서만 발생하는 단발성 문제이기 때문에, 경로 전체에 영향을 주지 않기 위함
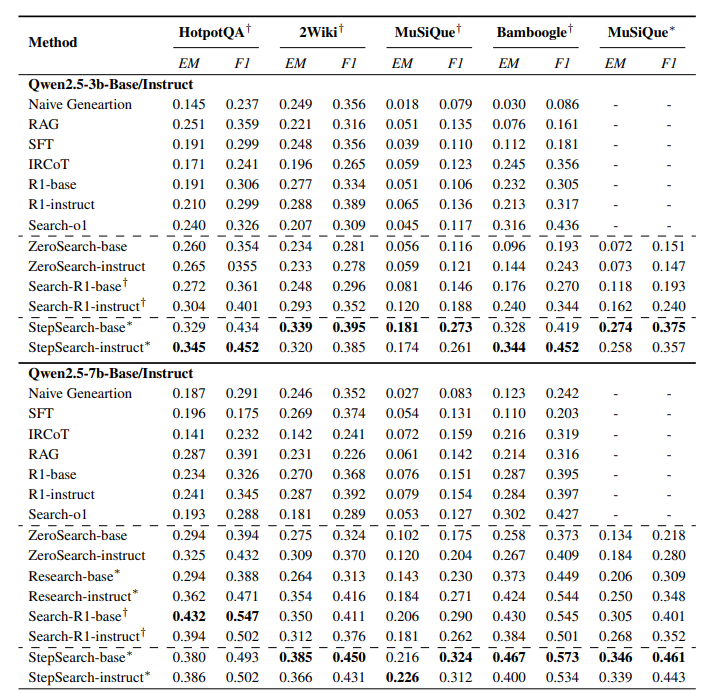
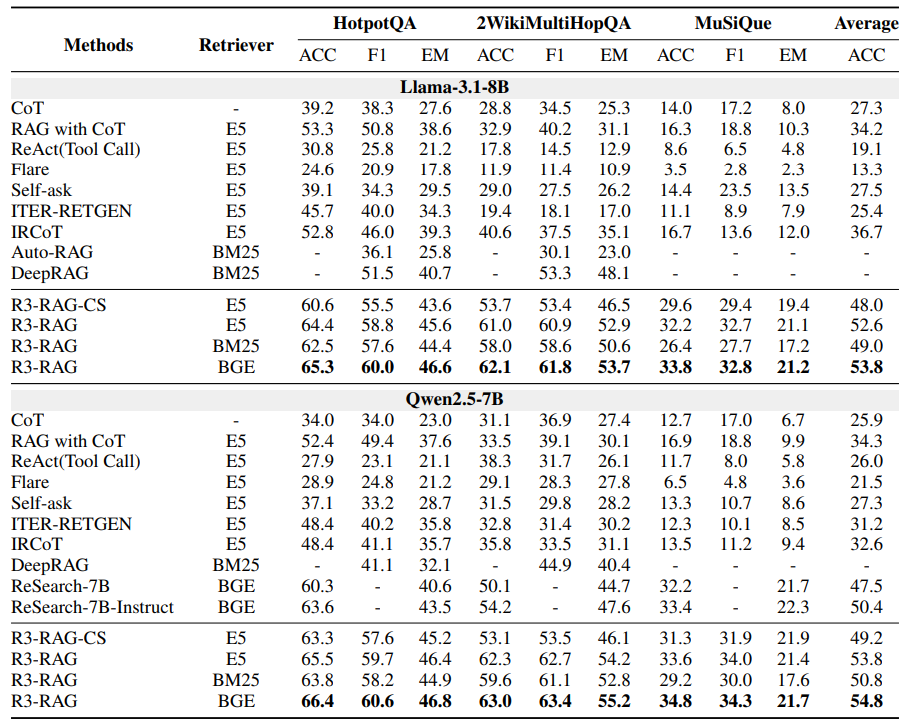
Main Results
AutoRefine
NeurIPS 2025
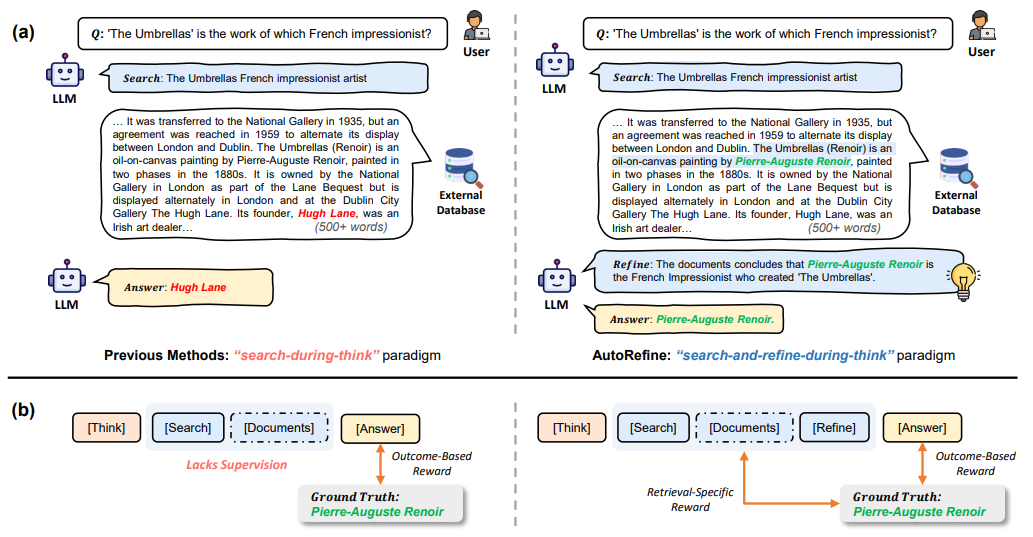
search-and-refine-during-think 패러다임을 활용한 강화학습 기반 RAG 프레임워크
1. <refine></refine>: 검색된 문서의 핵심적인 정보 추출 및 무관한 정보 제외
2. 결과 기반 보상과 검색 특화 보상을 결합한 공동 리워드 설계 + GRPO 학습
→ 모델이 추론 전반에 걸쳐 세밀한 지식을 추출, 조직, 활용할 수 있게 도와줌
방법론
Rollout Generation

- <think></think>: 검색 행동에 대한 전반적인 계획
- <search></search>: 검색 쿼리 생성
- <document></document>: 검색된 문서 반환
- <refine></refine>: 검색된 내용에서 관련 정보 추출
- <answer></answer>: 최종 답변 생성
보상 함수 설계
결과 기반 보상
흔히 볼 수 있는 생성 답변과 정답과의 F1 점수
검색 특화 보상
- : 모든 블록 내 문서를 수집하여 하나의 텍스트 시퀀스로 만듦
즉, 정답 에 포함된 모든 요소(핵심 단어, 문구 등)가 에 모두 들어있으면 1, 아니면 0
최종 보상 형태
Main Results