[논문 리뷰] Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
RAG
목록 보기
3/12
BackGrouond
- RAG의 한계점
- retrieve해오는 passage의 수가 늘어도 성능 개선 폭이 크지 않거나 오히려 성능이 감소하는 문제가 발생
- 이는 RAG의 decoding에서의 복잡한 aggregation 과정으로 인해 passage 수에 quadratic하게 비례하여 연산량이 증가하기 때문 (자세한 내용은 해당 포스팅 참조)
- retrieve해오는 passage의 수가 늘어도 성능 개선 폭이 크지 않거나 오히려 성능이 감소하는 문제가 발생
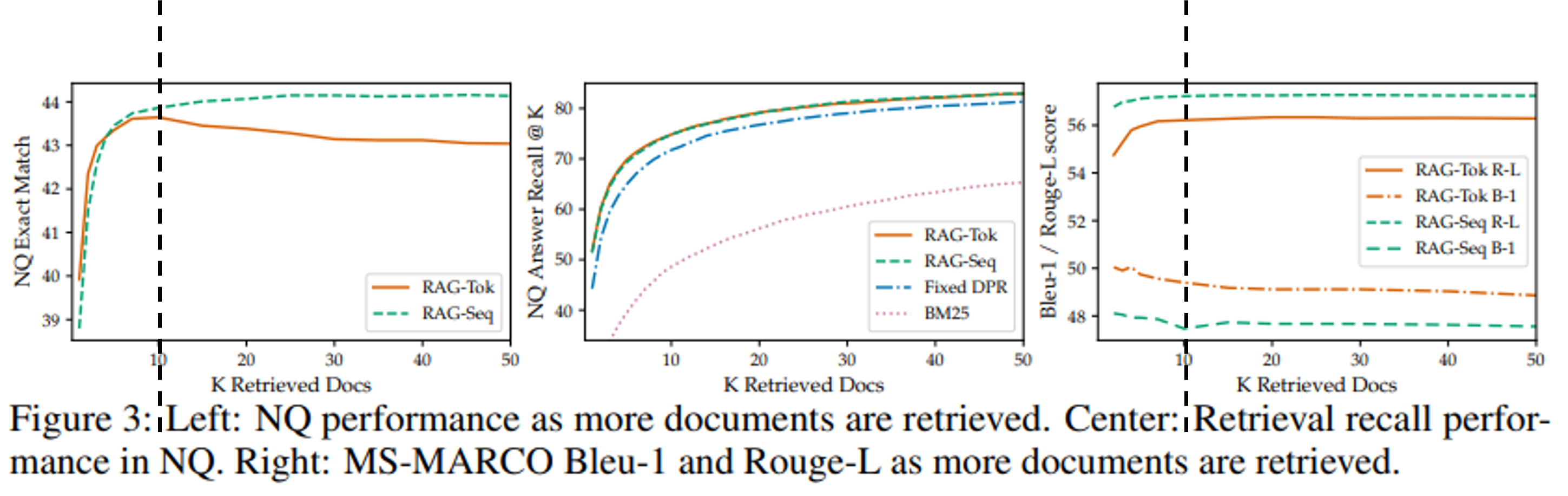
Fusion in Decoder(FiD)
- 여러 입력 단락(문맥)을 인코더에서 개별적으로 처리한 후 디코더에서 결합하는 방식
- Retriever는 학습 X
- DPR, BM25를 사용
-
Encoder
- passage와 query과 concat되어 독립적으로 입력됨 (process passages indepdently)
- question, title, context라는 special token 사용
- 한 번에 하나의 문맥에 대해서만 self-attention 수행
- 때문에 많은 수의 문맥으로 확장 가능함
- 해당 구조는 RAG와 같음
- passage와 query과 concat되어 독립적으로 입력됨 (process passages indepdently)
-
Decoder
- concat된 인코더의 hidden representation들에 cross-attention 수행하여 answer 생성
(process passages jointly)
- concat된 인코더의 hidden representation들에 cross-attention 수행하여 answer 생성
-
RAG와는 달리 디코딩 구조가 단순하며 연산량이 linear하게 증가함
Experiments
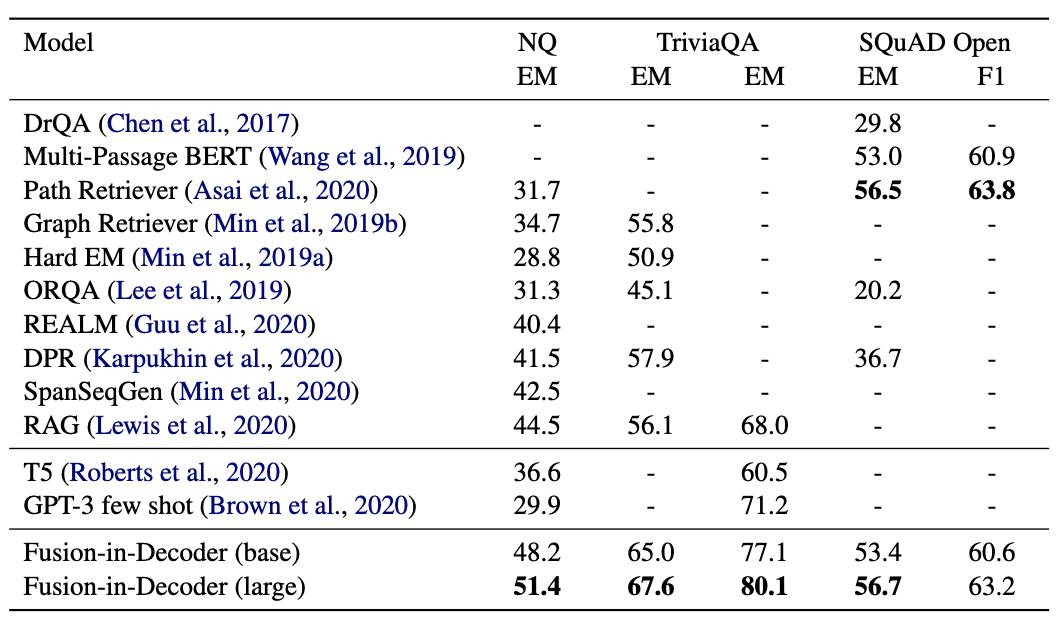
- 더 많은 수의 passage를 검색해서 process하는 과정이 성능 개선에 기여
- NQ 데이터셋에서 closed book T5 모델의 경우 11B의 크기로 36.6%의 성능을 기록했지만, FiD는 770M의 pretrained T5-large 모델 + Wikipedia BM25 retrieval은 44.1%의 성능을 기록
(... 아마 표에서 말하는 Fusion-in-Decoder(large)의 51.4% 기록은 retrieval 방식이 BM25가 아니라 DPR인 경우에 말하는 거 같음)
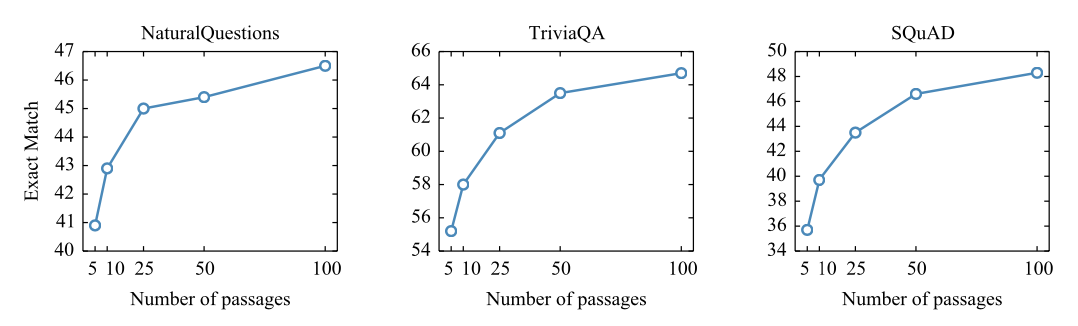
- # of passage ↑ - EM ↑
- 많은 passage를 효과적으로 사용
- FiD 기법을 적용한 seq2seq 모델들이 다수의 passage로부터 정보를 잘 조합하는 거 같다!
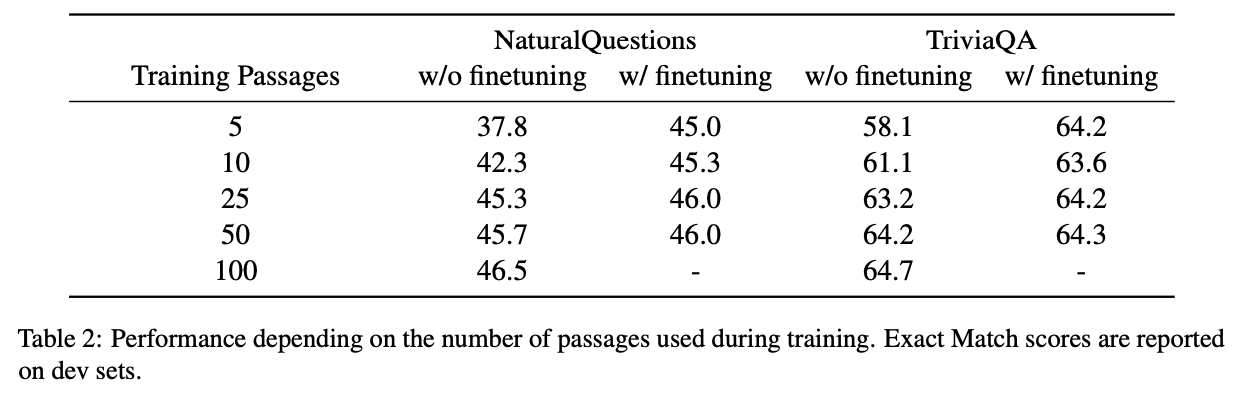
- # training passage ↓ - EM ↓
- 하지만, 100개의 passage로 학습하는 것은 computation cost ↑
- 때문에 이전에 학습한 모델을 100개의 passage * 1000번의 step으로 fine-tuning하는 것을 제안
- 적은 수의 training passage로 학습해도 fine-tuning을 거치게 되면 100개의 passage로 학습한 것과 비슷한 성능을 갖게 됨
Exact Match(EM)
생성된 답변이 (정규화 후) 허용 가능한 답변 목록 중 하나와 일치하면 정답으로 간주

stick-to-it-iveness