항해99-17기 2일차 TIL
- leetcode 234. 팰린드롬 연결 리스트 - https://leetcode.com/problems/palindrome-linked-list/
( 과제는 아니고, 강의 내용에 포함된 문제이다. )
- leetcode 206. 역순 연결 리스트 - https://leetcode.com/problems/reverse-linked-list/
- leetcode 21. 두 정렬 리스트의 병합 - https://leetcode.com/problems/merge-two-sorted-lists/
- leetcode 328. 홀짝 연결 리스트 - https://leetcode.com/problems/odd-even-linked-list/
오늘 발표를 맡은 과제는 1. leetcode 206. 역순 연결 리스트 이다.
오늘은 강의 내용도 문제도 모두 연결 리스트(linked list)에 관한 내용이다.
어제의 난이도와는 달리 다행히 오늘은 모든 문제를 풀긴 풀었다.
하지만 제출한 답이 연결 리스트의 구조를 활용하지 않고 배열로 값을 풀어서 다시 대입해서 풀었다.
연결 리스트 문제 풀이에 맞지 않은 접근법이라 생각해서 책이나 블로그 글을 찾아 볼 필요를 느낀다.
공부할 내용이 어제보단 적어서 조금 더 여유롭게 공부하고 충분히 생각하고 찾아보고 기록할 수 있어 좋다.
다만 연결 리스트라는 내용 자체를 처음 접했는데, 생각보다 이해하는 데 꽤 시간을 소비했다.
연결 리스트의 기본적인 구성도 백지에 쓸 정도가 되어야 한다고 강의에 나와 있는데 아직 익숙지 않아 긁어 오는 편이다.
추가적인 부분을 찾아 보니 기입할 수 있는 정보나 기능이 다양해 활용성 측면에서 좋을 것 같지만 내용을 기억할 수 있을지는 모르겠다.
이런 것들을 할 수 있구나~ 싶은 정도가 되면 딱 좋겠다 싶다.
# 연결 리스트 (Linked List)
연결 리스트는,
배열과 함께 기본이 되는 대표 선형 자료구조 중 하나로, 다양한 추상 자료형(Abstract Data Type) 구현의 기반이 된다.
동적으로 새로운 노드를 삽입하거나 삭제하기가 간편하고, 연결 구조를 통해 물리 메모리의 연속적 사용을 하지 않아도 되기에 관리가 쉽다.
데이터를 구조체로 묶어, 포인터로 연결하는 개념은 활용성이 여러 가지로 다양하다.
1(p1), 2(p3), 6(p4), 5(p2) ... ...(pn)은 포인터의 예시이다. 실제로 이렇게 표기하지는 않는다.
노드로 구성한 데이터에 값을 가지고 포인터를 이용해 다음 노드와 이어지는 구조를 가지고 있다.
따라서 연결 리스트 탐색의 경우, 원하는 값을 찾을 때 순서대로 읽어가며 진행이 되기 때문에 O(n)이 소요된다. (리스트는 O(1))
또한 시작이나 끝 지점에 아이템을 추가하거나 삭제, 추출하는 작업은 O(1)이 가능하다. (리스트는 O(n))
234. Palindrome Linked List
from. leetcode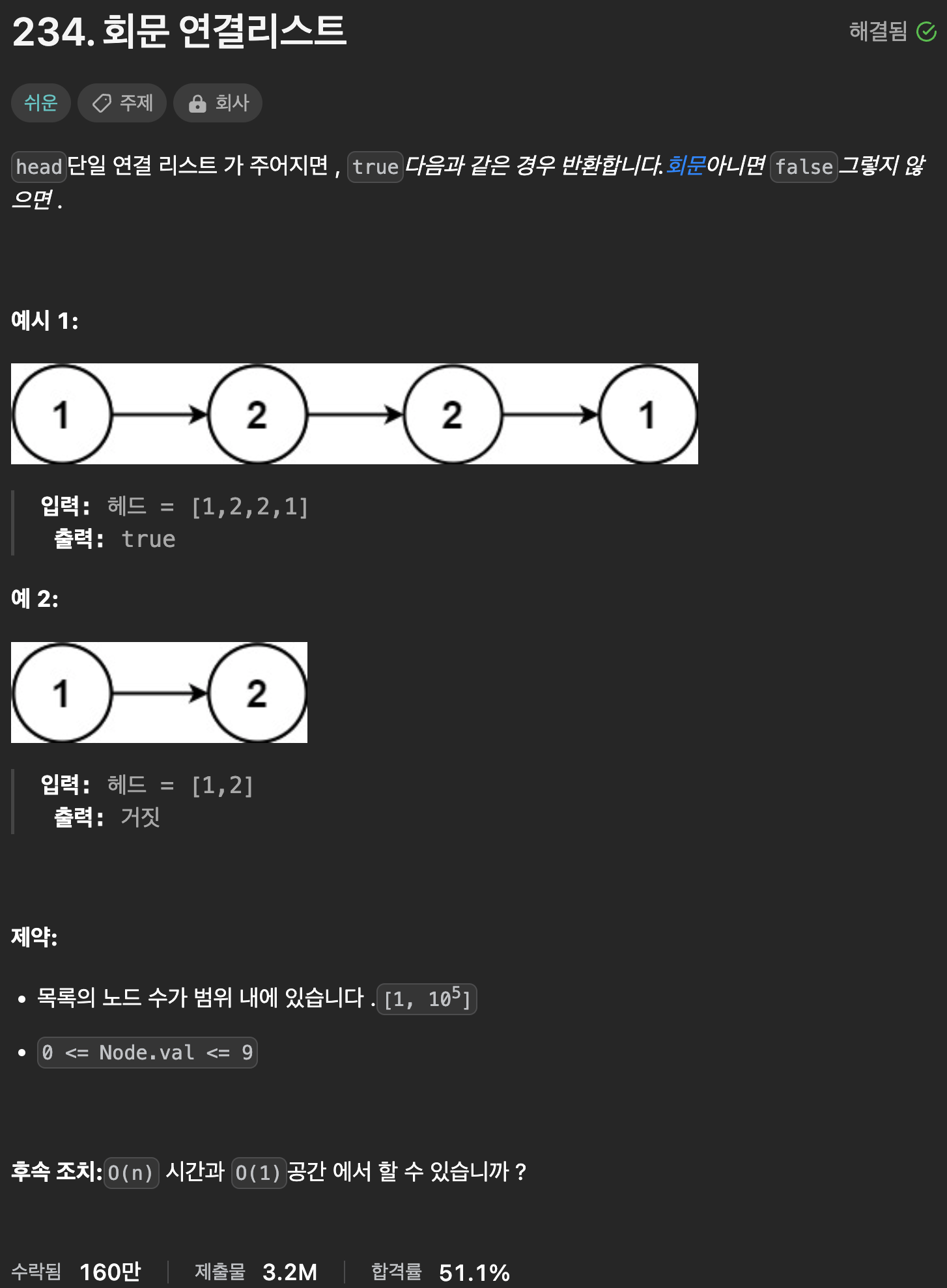
크롬에 내장된 영한 번역을 사용했다.
내가 수강한 강의의 '연결 리스트' 부분에 나온 문제이다.
연결 리스트 개념 정리에 허덕이다가 문제를 읽었지만 풀지는 못 했다.
풀이는 못해도 알고리즘 접근은 해 보았는데,
1. 연결 리스트의 노드(헤드)의 값을, 노드.next의 값을 읽는 방식으로 값이 None이 나올 때까지 읽어 배열에 담는다.
2. 배열의 맨 앞과 맨 뒤를 비교한다. index를 더하고/빼면서 비교 확인을 하여, 끝까지 일치하면 True를 리턴하고 else False를 리턴한다.
고민하다가 다가간 내용인데 처음엔 도저히 어떻게 코드를 짜야 할지 몰랐다.
강의를 듣고서도 바로 이해가 되지 않은 건 오랜만이었다... 여러 번 반복해서 듣고
수강한 강의로 모자라서, youtube에 파이썬 연결 리스트를 검색해 내용을 추가로 참고했다.
다행히 어느 정도 강의 내용을 이해하게 되고, 오늘의 과제 문제들도 풀어 볼 수 있었다.
아래는 위 문제의 풀이이다. 수강한 강의에서 나온 풀이를 가지고 왔다.
234. 풀이
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
def isPalindrome(self, head: Optional[ListNode]) -> bool:
arr = []
if not head:
return True
node = head
while node:
arr.append(node.val)
node = node.next
while len(arr) > 1:
if arr.pop(0) != arr.pop():
return False
return Trueclass ListNode를 통해, 연결 리스트와 노드를 구성한 부분을 이용할 수 있었다. 이 부분은 기본으로 기입되어 있다.
arr 배열을 생성하고,
head가 없는 경우도 True로 반환하는 조건문이 쓰여 있다. (문제에 명시된 부분)
node에 head를 부여하고,
arr에 각 node의 값을 대입한다.
( node = node.next는 마치 리스트 반복문의 인덱스를 활용한 증감문 n += 1 과 같은 용도의 느낌이다. )
arr의 길이가 1이 초과할 때까지만
arr의 첫 인덱스와 마지막 인덱스가 같지 않을 때, (대칭이 아님 -> Palindrome 조건 불충족) False를 리턴한다.
그 외에(전부 대칭 -> Palindrome 조건 충족) True를 리턴한다.
마지막 while문은 인상 깊었다. len(arr) > 1: 의 조건 범위가, '1 초과의 길이를 가질 때까지'이고
아래 if 문이 arr.pop(인덱스 번호)을 활용하여 비교 및 삭제를 실행해 나감으로 가운데 문자 또는 마지막 대칭 문자를 확인하게끔 짜였다.
0번 인덱스와 끝자리의 값을 계속 비교해나가며, 깔끔하고 정확하게 마지막 비교까지 진행된다.
앞으로 앞뒤의 대칭을 비교하는 Palindrome과 같은 문제를 풀 때 도움이 되는 풀이를 하나 알게 된 것 같다.
206 - Reverse Linked List
from. leetcode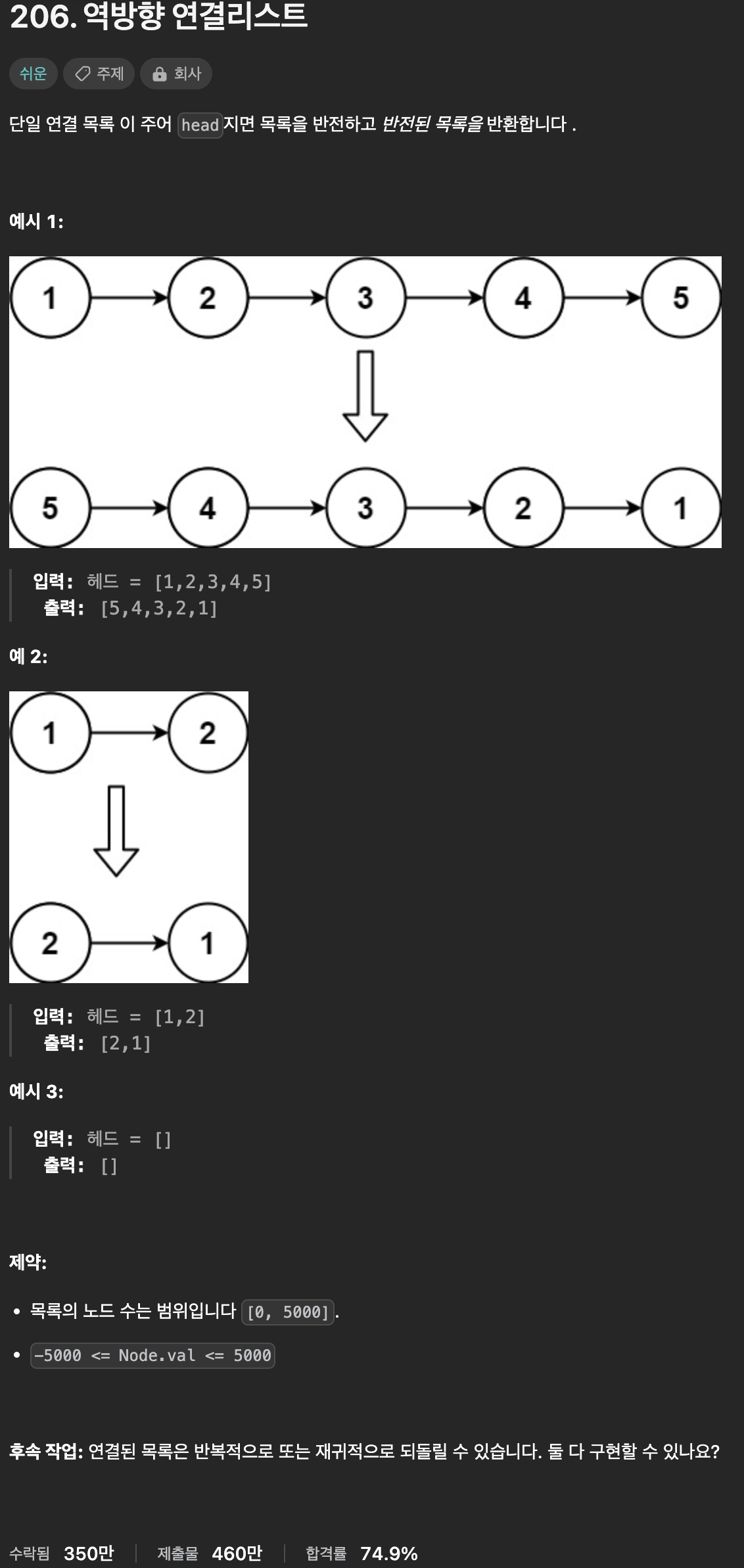
크롬에 내장된 영한 번역을 사용했다.
206. 풀이
아래는 나의 풀이이다.
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
self.head = None
def append(self, val):
if not self.head:
self.head = ListNode(val, None)
return
node = self.head
while node.next:
node = node.next
node.next = ListNode(val, None)
class Solution:
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
arr = []
newList = ListNode()
node = head
i = 1
while node:
arr.append(node.val)
node = node.next
while i <= len(arr):
newList.append(arr[-i])
i += 1
return newList.headappend의 경우, 강의 내용에 있는 부분을 긁어 왔다.
보다시피, 빈 배열에 노드를 할당해서, 역순 인덱스를 이용해 연결 리스트에 할당하는 방식으로 풀었다.
이는 연결 리스트의 구조를 사용하지 않고 단순 반복문을 활용한 답변이라고 할 수 있다.
풀긴 풀었지만, 길고 지저분하고, 연결 리스트를 이해하고 쓰지 못했다. 빅오의 제한이 있었다면 시간 초과가 나왔어도 할 말 없을 풀이이다.
따라서 다른 풀이를 참고했다. 아래는 그 코드이다.
class Solution:
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
prev = None # 이전 노드를 저장할 변수
current = head # 현재 노드를 가리키는 포인터
while current:
next_node = current.next # 다음 노드를 임시로 저장
current.next = prev # 현재 노드의 다음 노드를 이전 노드로 바꿈
prev = current # prev를 현재 노드로 업데이트
current = next_node # 현재 노드를 다음 노드로 업데이트
print(prev)
return prevprev라는 이전 노드의 방향을 만들어, 노드를 전환하는 방식으로 접근한 풀이이다.
이 풀이를 보고서야 연결 리스트의 이해도가 높아졌다. 아, 노드의 방향은 이렇게 활용하는 것이구나.
책의 풀이도 궁금하여 가지고 왔다.
책의 경우, 문제에 나와 있는 재귀(recursive)와 반복(iterative)을 활용한 두 가지의 풀이가 있다.
# 1. 재귀(Recursive)
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
def reverse(node: ListNode, prev: ListNode = None):
if not node:
return prev
next, node.next = node.next, prev
return reverse(next, node)
return reverse(head)
재귀의 경우, next와 node를 파라미터로 지정한 함수를 계속해서 재귀 호출한다.
node.next에 prev 리스트를 계속 연결해주면서 node가 None이 될 때까지 재귀 호출하면
마지막에 백트래킹되면서 연결 리스트가 거꾸로 연결된다. 맨 처음 리턴된 prev는 뒤집힌 연결 리스트의 첫 번째 노드가 된다.
재귀는 함수의 적층이다보니 반복문보다 효율이나 시간 복잡도가 떨어지는 편이기도 하다.
(시간 복잡도는 그래도 큰 차이 안 나는데 공간 복잡도는 반복이 효율적이다.)
그리고 여기 재귀는 한 눈에 보일 정도로 깔끔하진 않은 듯하다.
기술매니저님께서 말씀하시길, 재귀 함수의 경우는 많은 부분에서 반복문 보다 직관적이라고 하셨으나,
이 문제는 반복문이 더 눈에 잘 들어 오는 예시라고 볼 수 있을 거 같다.
아래는 반복을 통해 풀이한 과정이다.
# 2. 반복(Iterative) - 제일 빠름
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
node, prev = head, None
while node:
next, node.next = node.next, prev
prev, node = node, next
return prev확실히 깔끔하다.
재귀와 마찬가지로 node.next를 prev 리스트로 계속 연결하면서 끝날 때까지 반복한다.
이하는 위와 동일하다.
반복 풀이의 경우, prev에 node를, node에 next를 별도로 셋팅하며,
node가 None이 될 때까지 계속 반복문을 돌게 된다.
이외에 푼 두 문제 역시, 내가 좀 더 연결 리스트의 이해도가 생기기 전에 풀었던 문제이다 보니,
이와 같이 배열로 풀어서 다시 반환하는 과정을 거친 부분이 아쉽다.
# 연결 리스트에 관해.
연결 리스트의 경우, class에 함수를 만들어 len()이나 pop(), find() 등이 구현 가능하다.
다만 그만큼 노드에 필요한 정보를 추가하여야 사용할 수 있는 부분도 있다.
필요한 만큼의 정보와 함수만 만들어서 사용하면 나름 효율적일 것 같다.
또, 삽입(값의 추가가 아님, 포인터로 짚는 것뿐)과 제외가 쉽기에, 이와 같은 기능을 자주 쓰는
선형 자료형으로 활용하기에도 용이한 듯하다.
다만 값이 눈에 쉽게 들어오지 않는 부분은 아무래도 아쉽다.
꼭 연결 리스트를 사용해야 할 정도의 효율이 필요한 부분이 아니라면 잘 안 쓰지 않을까 싶다.
연결 리스트는 그 포인트에 따라,
- 단일 연결 리스트 - 일방향
- 이중 연결 리스트 - 양방향
- 원형 연결 리스트 - tail.next == head
- 연결 리스트의 확장 - head나 tail의 다음 값이 더미 노드를 추가하여 사용.
으로 나눌 수도 있다.
