항해99-17기 3일차 TIL
- leetcode 20. 유용한 괄호 - https://leetcode.com/problems/valid-parentheses/
(강의 내용에 포함된 문제이다. ) - <파이썬 알고리즘 인터뷰>(이하 책) 245p.
- leetcode 739. 일일 온도 - https://leetcode.com/problems/daily-temperatures/ - 책 252p.
- leetcode 21. 중복 문자 제거 - https://leetcode.com/problems/remove-duplicate-letters/ - 책 247p.
- 백준 9012. 괄호 - https://www.acmicpc.net/problem/9012
- 백준 1874. 수열 스택 - https://www.acmicpc.net/problem/1874
오늘 발표를 맡은 과제는 leetcode 739. 일일 온도 이다.
오늘의 강의 내용과 문제는 스택에 관한 내용이다.
스택의 강의를 들어 보니, 어제 공부한 연결 리스트와 굉장히 흡사하게 구성한다.
node의 값과 포인터를 구성해서 형성하고, 스택의 시작과 끝이 알맞게 되어 있는지 확인하거나 한다.
어제 문제를 풀 때와는 다르게, 연결 리스트를 어느 정도 이해한 상태에서 스택을 보니 이해가 잘 된다.
이번에는 문제를 풀지 않은 상태에서 들어가는 글을 간단히 작성해 보았다.
어쨌든 이번엔 출제자의 의도에 맞게끔 문제를 푸는 것이 목표이다. 전부 풀지는 못 해도 상관 없다.
그 경우, 답을 확인하고서 이해하는 방향으로 공부를 진행하겠다.
# 스택 (Stack)
스택(Stack)은,
프로그래밍이라는 개념이 만들어지는 순간부터 사용된 자료구조 중 하나로, 거의 모든 애플리케이션에 사용된다.
LIFO(후입선출)로 처리되며, 같이 언급되는 큐(Queue)의 경우 FIFO로 처리된다.
파이썬은 스택 자료형을 별도로 제공하지 않지만, 사실상 리스트가 스택 연산을 지원한다.
큐의 경우도 마찬가지로 리스트로 사용이 가능한데, 성능이 중요한 경우에는 데크라는 자료형을 사용한다고 한다.
자세한 건 내일 큐를 공부하면서 다시 언급하겠다.
스택은 LIFO로 처리되는 만큼, push()와 pop()을 주요 연산으로 지원하는 요소의 컬렉션으로 사용되는 추상 자료형이라고 한다.
push를 통해서 A, B, C 순으로 넣으면 pop을 이용해서 C, B, A 순으로 꺼내는 LIFO의 처리 형태라고 간단히 말할 수 있겠다.
스택은 콜 스택(Call Stack)이라고, 프로그램의 서브루틴 정보를 저장하는 자료구조에도 활용된다고 한다. (JS의 실행 컨텍스트가 떠오른다.)
# 연결 리스트를 통한 스택 ADT 구현
어제 공부한 연결 리스트로, Node 클래스를 정의해서 포인터로 연결하여 스택을 구현할 수 있다.
아래는 이해하고서 적어 본 스택의 연결 리스트 코드이다.
class Node:
def __init__(self, item):
self.item = item
class Stack:
def __init__(self, top):
self.top = None
def push(self, val):
self.top = Node(val, self.top)
def pop(self):
if self.top is None:
return None
node = self.top
self.top = self.top.next
return node.item
def is_empty(self):
return self.top is None간단히 메모를 하자면, 우선 Node 클래스를 생성해 이용하는 부분은 동일하다.
그리고 top을 이용해서 연결 리스트를 만들고,
push를 이용해 top으로 연결하고, pop을 이용해 현재의 top의 값을 꺼내고 next로 포인터를 한 칸 옮긴다.(이전 값으로 포인팅)
is_empty는 다 꺼낸다면 true가 나올 것이다.
아래는 스택의 LIFO 처리 구조를 활용하는 문제이다.
20. Valid Parentheses
from. leetcode
크롬에 내장된 영한 번역을 사용했다.
깨진 부분이 조금 보인다.
간단히 말하면, s에 입력된 괄호가 열고 닫힘에 있어 올바르게 처리되고, 남는 것이 없다 ? true : false 이다.
# 20. 풀이
아래는 강의 내용에 나온 풀이 코드이다.
class Solution:
def isValid(self, s: str) -> bool:
pair = {
']': '[',
'}': '{',
')': '(',
}
opener = '[{('
stack = []
for char in s:
if char in opener:
stack.append(char)
else:
if not stack:
return False
top = stack.pop()
if pair[char] != top:
return False
return not stack리스트를 이용하여 스택의 구조를 활용해 처리한 것으로 보인다.
리스트의 이름도 stack이다.
반복문을 이용해
char가 opener인 경우 stack에 할당하고,
(else문에서의 not stack은 리트코드의 비정상적인 테스트 케이스의 경우를 보완한 것이라고 하셨다.)
pair 딕셔너리로, closer를 key로 하여
closer를 순서대로 pair의 key에 넣어, stack의 pop과 비교한다.
{}[] 의 경우나, {[]}의 경우나 마찬가지로 깔끔하게 비교할 수 있다.
마지막에 not stack을 return 하는 이유는 혹시 오프너가 많아서 stack에 남거나 하는,
{{[]} 이와 같은 경우에 false를 반환하기 위해서이다.
pair와 같이 딕셔너리를 만들어 반복문을 돌리는 게 흥미로웠다.
생각보다 유용하게 여기 저기 사용할 수 있어 보인다.
739. - Daily Temperatures
from. leetcode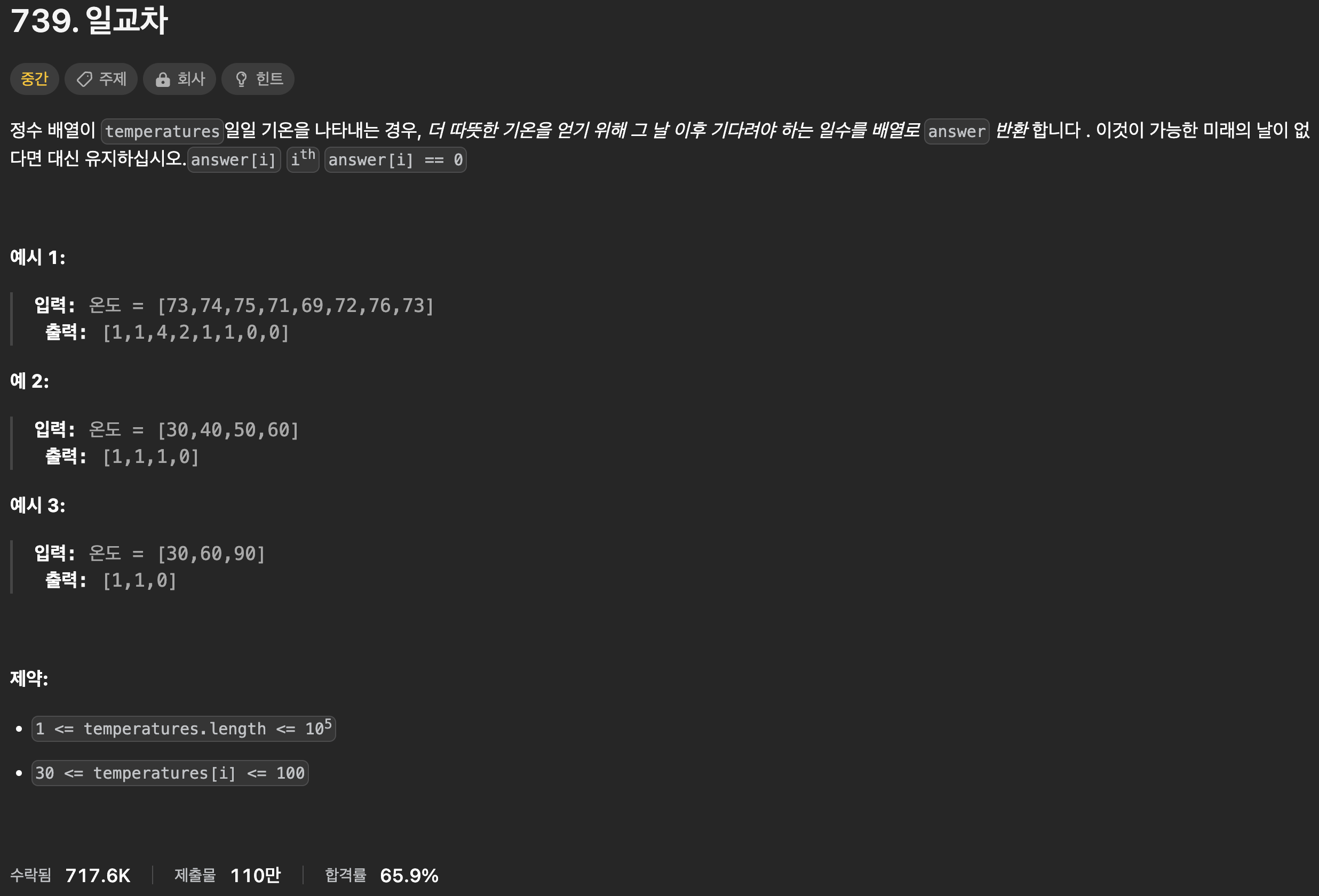
크롬에 내장된 영한 번역을 사용했다.
오역이 다소 있다.
일교차라니, 내용을 읽으면 맞지 않은 제목이란 걸 알 수 있다.
(사실 온도의 범위도 좀 이상하다)
아무튼 요는, 일일 기온을 나열하고, 더 따뜻한 기온이 나오는 날까지 며칠이 남았는지를
새 배열에 할당해 출력하는 방식이다.
목록 안에 돌아 오는 날이 없거나, 날 중에 더 따뜻한 날이 없으면 0으로 출력한다.
# 739. 풀이
아래는 나의 풀이이다.
class Solution:
def dailyTemperatures(self, temperatures: List[int]) -> List[int]:
answer = []
for i in range(len(temperatures)):
for j in range(i+1, len(temperatures)+1):
if j == len(temperatures):
answer.append(0)
break
elif temperatures[i] < temperatures[j]:
answer.append(j-i)
break
return answer참 부끄러운 풀이다.
예제를 실행했을 때는 답이 맞다고 나오지만
제출을 날리면 제한 시간 초과로 나온다. (이중 반복문 O(n^2))
케이스가 엄청난 게 들어가서 오류가 나오는 것 같기도 하다.
리트 코드에 있다는 그 엄청난 테스트 케이스인지도 모르겠다.
리스트로 LIFO를 활용해 append(push 대체)와 pop을 활용하는 방향으로
한 번 더 풀어 보거나 리팩토링 해 봐야겠다.
리팩토링에 도전했지만 장렬히 실패했다.
결국 책에 쓰인 답을 가지고 왔다. 아래가 그 풀이이다.
# 739. 책 - 풀이
class Solution:
def dailyTemperatures(self, temperatures: List[int]) -> List[int]:
T = temperatures
answer = [0] * len(T)
stack = []
for i, cur in enumerate(T):
# 현재 온도가 스택 값보다 높다면 정답 처리
while stack and cur > T[stack[-1]]:
last = stack.pop()
answer[last] = i - last
stack.append(i)
return answer일단 기나긴 temperatures를 T로 아예 바꿔 쓴 것을 봤는데
내 경우, 문제에서 주어진 매개변수명을 그대로 가져 오고 싶어서 T = temperatures 를 기입했다.
처음에 코드를 읽고 잘 이해가 안 됐다.
이유가 두 가지 정도 있었는데, 하나는 enumerate() 함수이며,
또 하나는 while stack and cur > T[stack[-1]]: 이 한 줄이었다.
enumerate(iterable, startIdx) 함수는,
해당 함수는 iterable(순환 가능한 객체), 시작 index를 인자로 가진다. (시작 인덱스 생략 시 0)
['A', 'B', 'C']라는 리스트를 인자로 넣으면 (0, 'A') (1, 'B') (2, 'C') 와 같이
(인덱스, 해당 인덱스의 값)을 짝지어 튜플로 출력한다.
따라서 for문의 i는 튜플 0, 1, 2, ... ... T의 인덱스를 값으로 가지고, cur는 T의 값을 갖게 된다.
while문은 stack이 값이 있을 때 cur > T[stack[-1]] 을 기준으로 하는데
stack의 초기값이 빈 리스트라서, 바로 stack.append(i)가 실행된다.
그리고 다시 while문을 도는 게 처음에 이해가 안 됐는데, 밖에 for문이 있기 때문이었다.
for문과 내부의 while문도 아직 한눈에 알아보긴 힘든데 팀원 분의 조언을 받아 시각화 해 보았다.
