Case study - News Categorization
문자를 vector로 - One-hot Encoding
- 하나의 단어를 Vector의 Index로 인식한다.
- 단어가 존재할 시 1, 없으면 0
벡터 스페이스?
각각의 글자들이 어떤 인덱스에 포함하는지 정해놓은 공간이다.
단어가 n개가 있다면, n size를 가진 list를 만들어 준다.
각 문서마다 각 인덱스 번호에 해당하는 단어들이 얼마나 있는지 판단한다.
Bag of words
하나의 문자에 있는 단어들의 표현 방법은 Bag of words라는 기법이다.
- 단어별로 인덱스를 부여해서 한 문장 또는 문서의 단어의 개수를 Vector로 표현한다.
the dog is on the table
0 0 1 1 0 1 1 1
are cat dog is now on table the
[0] [1] [2] [3] [4] [5] [6] [7] -> index유사성 판단 - Euclidian distance
- 피타고라스 정리, 두 점 사이의 직선 거리를 활용
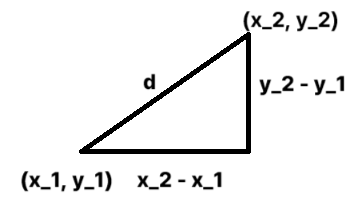
Cosine distance
- 두 점 사이의 각도
문서의 similarity를 구할 때는 cosine similarity를 많이 사용한다.
Dataset이 적은 경우 Euclidian distance를 써도 괜찮게 나오지만, Dataset이 크면 클수록 cosine distance가 더 잘 나온다.
예를 들어, Love, hate라는 글자가 들어있는 문서 3개가 있다.
어느 점이 가장 가까운가?
- A : (5, 0)
- B : (4, 0)
- C : (5, 1)
A는 Love만 5번 나왔고, B는 Love만 4번, C는 Love 5번과 hate 1번이 나왔다.
위와 같은 경우에서는 A에서 B, C의 거리가 똑같이 1만큼의 거리 차이가 나지만, 유사성으로 따졌을 때는 B와 조금 더 유사하다고 판단할 수 있을 것이다.
Process
- 파일을 불러오기
- 파일 읽어서 단어사전(corpus) 만들기
- 단어별로 Index 만들기
- 만들어진 인덱스로 문서별 Bag of words vector 생성
- 비교하고자 하는 문서 비교하기
- 얼마나 맞는지 측정하기
def get_file_list(dir_name):
return os.listdir(dir_name)
if __name__=="__main__":
dir_name = "news_data"
file_list = get_file_list(dir_name)
file_list = [os.path.join(dir_name, file_name) for file_name in file_list]
get_file_list: 이 안에 폴더명을 입력을 해주면, 해당 폴더 안에 있는 파일들을 가져오는 함수- 파이썬은 상대경로로 입력해주어야 해서, 폴더명과 파일명을
os.path.join이렇게 join해주어야 함.
폴더끼리 연결을 해줄 때, os 별로 \일수도, /일수도 있기 때문에 os.path.join을 사용하게 되면 os에 맞춰 join을 해준다.
파일별로 내용읽기
def get_contents(file_list):
y_class = []
X_text = []
# 0은 야구, 1은 축구
class_dict = {
1: "0", 2: "0", 3:"0", 4:"0", 5:"1", 6:"1", 7:"1", 8:"1"}
for file_name in file_list:
try:
f = open(file_name, "r", encoding="cp949")
# os.sep : 파일 슬래시/역슬래시를 말함
category = int(file_name.split(os.sep)[1].split("_")[0])
y_class.append(class_dict[category])
X_text.append(f.read())
f.close()
except UnicodeDecodeError as e:
print(e)
print(file_name)
return X_text, y_classCorpus 만들기 + 단어별 index 생성하기
def get_cleaned_text(text):
import re
# 의미없는 문장부호 제거, 전처리 해주는 것
text = re.sub('\W+', '', text.lower())
return text
def get_corpus_dict(text):
text = [sentence.split() for sentence in text]
# 이중 for 문 : two-demension list
# 2-demension을 1-demension으로 바꿔줌
cleaned_words = [get_cleaned_text(word) for words in text for word in words]
from collections import OrderedDict
corpus_dict = OrderedDict()
for i, v in enumerate(set(cleaned_words)):
corpus_dict[v] = i
return corpus_dictget_cleaned_text: 의미없는 문장보호 등은 제거set: 전체 단어에서 같은 단어들은 빼버리기
문서별로 Bag of words vector 생성
def get_count_vector(text, corpus):
text= [sentence.split() for sentence in text]
word_number_list = [[corpus[get_cleaned_text(word)] for word in words] for words in text]
X_vector = [[0 for _ in range(len(corpus))] for x in range(len(text))]
for i, text in enumerate(word_number_list):
for word_number in text:
X_vector[i][word_number] += 1
return X_vector- 2-demension 형태로 만들어주고, word를 뽑아주게 된다.
get_cleaned_text(word): 앞에서와 같은 방법으로 전처리를 동일하게 해준다.word_number_list: 각 문서들마다 어떤 단어가 연속적으로 나열되는지 보여주는 리스트
비교하기
import math
def get_cosine_similarity(v1, v2):
"comput cosine similarity of v1 to v2: (v1 dot v2)/{||v1||*}}v2||)"
sumxx, sumxy, sumyy = 0, 0, 0
for i in range(len(v1)):
x = v1[i]; y=v2[i]
sumxx += x*x
sumyy += y*y
sumxy += x*y
return sumxy/math.sqrt(sumxx*sumyy)- 수식을 코드로 적은 것이다.
- v1, v2는 하나의 문서에 대한 벡터 표현인 4302개의 벡터
- 얼마의 similarity score를 가지는지 보여준다.
비교결과 정리하기
def get_similarity_score(X_vector, source):
source_vector = X_vector[source]
similarity_list = []
for target_vector in X_vector:
similarity_list.append(get_cosine_similarity(source_vector, target_vector))
return similarity_list
def get_top_n_similarity_news(similarity_score, n):
x = {i: v for i, v in enumerate(similarity_score)}
sorted_x = sorted(x.items(), key=operator.itemgetter(1))
return list(reversed(sorted_x))[1:n+1]similarity_list에는 유사도 비교 리스트similarity_score: 80개의 문서들에 대해 유사도 점수가 나온다.get_top_n_similarity_news: key값으로 정렬을 해서 value 값 중 가장 큰 값의 인덱스 값을 같이 반환해준다. 가장 유사한 값 10개를 뽑아준다.- 0부터 80까지 각각 비교를 해서 결과값을 출력해준다.
News Categorization using sklearn
- scikit-learn이라는 파이썬 머신러닝 모듈이 존재하는데
CountVectorizer()라는 클래스를 사용할 수 있다.
하나의 문서 set에서 feature를 뽑아서 벡터화하는 역할을 쉽게 할 수 있다.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
X = vectorizer.fit_transform(corpus)
X.toarray()
# 결과
array([[0, 1, 1, 1, 0, 0, 1, 0, 1],
[0, 1, 0, 1, 0, 2, 1, 0, 1],
[1, 0, 0, 0, 1, 0, 1, 1, 0],
[0, 1, 1, 1, 0, 0, 1, 0, 1]])
vectorizer.get_feature_names_out()
# 결과
array(['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third',
'this'], dtype=object)X.toarray(): 벡터화 결과

Whatever I want | Interested in DFIR, Security, Infra, Cloud