eDiscovery
먼저 eDiscovery의 개념입니다.
eDiscovery, 즉 Electronic Discovery란 소송이나 조사, 규제 대응 과정에서 전자적으로 저장된 정보, 이른바 ESI를 식별하고 보존하여 수집·처리·검토·분석한 뒤 상대방이나 법원에 제출하는 일련의 법적 절차를 말합니다.
eDiscovery
미국 민사소송절차에는 소송이 제기되면 공판이 이루어지기 전에 당사자들이 소송에 관련된 정보와 증거를 소송 상대방으로부터 요구해서 얻을 수 있도록 하는 증거개시제도(Discovery 제도)가 있다. 이는 공판 전에 당사자들이 서로 소송에 관련된 정보와 증거를 공유함으로써 사건의 쟁점을 명확히 하여 소송의 효율성을 높이고 올바른 판결을 내리고자 하는 것.
지식재산권 분쟁에서 미국의 전자증거개시제도를 활용할 가능성이 대두됨.
최근 체결된 FTA는 지식재산권에 관한 분쟁해결을 위해 영업 비밀을 포함한 정보의 일반적 제공의무를 규정하고 있고, 이는 영미법상의 증거개시 제도에 국내 특성을 반영한 e-Discovery 대응절차 대한 대응과 맞물려 있다. 이 체결의 영향으로 미국과의 지식재산권 분쟁은 증가할 것이고, 이런 지식재산권 분쟁에서 미국의 전자증거개시제도를 활용할 가능성이 대두되고 있다.
우리나라의 많은 기업이 미국과 같은 선진국들과 국제교류를 하고 해외사업을 확장함에 따라 국제적 분쟁에 대한 대비가 필요한 실정이며 이에 대해 체계적으로 대응할 수 있도록 e-Discovery에 대한 준비가 필요함.
여기서 ESI란 이메일, 메신저 대화, 서버 파일, 데이터베이스, 클라우드 문서, 모바일 데이터 등 디지털 형태로 존재하는 모든 정보를 포괄합니다. 종이 문서 중심의 전통적 Discovery와 달리, 현대 분쟁에서는 ESI가 핵심 증거의 대부분을 차지합니다.
eDiscovery가 왜 중요한지로 넘어가게 되면, 우선 법적 의무의 문제입니다.
미국의 FRCP나 EU의 GDPR 등 각국의 규제가 전자증거의 적절한 관리를 의무화하고 있습니다.
이를 제대로 이행하지 못하면 증거인멸 제재, 소송 패소 등 심각한 법적 불이익이 발생합니다.
비용 측면에서도 전체 소송 비용의 상당 부분이 eDiscovery 단계에서 발생하기 때문에,
eDiscovery를 얼마나 효율적으로 수행하느냐가 곧 기업의 법적 리스크 관리 수준을 결정합니다.
또한 eDiscovery가 필요한 상황으로 소송에만 국한되지 않습니다.
기업 부정조사, 내부감사, M&A 실사 등으로 활용 범위가 계속 확대되고 있습니다.
국내에서도 민사소송법 개정 등으로 전자문서의 증거능력 인정 범위가 넓어지고 있어 국내 기업의 대응 필요성도 높아지고 있습니다.
EDRM
eDiscovery를 체계적으로 수행하기 위한 국제 표준 프레임워크가
바로 EDRM, Electronic Discovery Reference Model입니다.
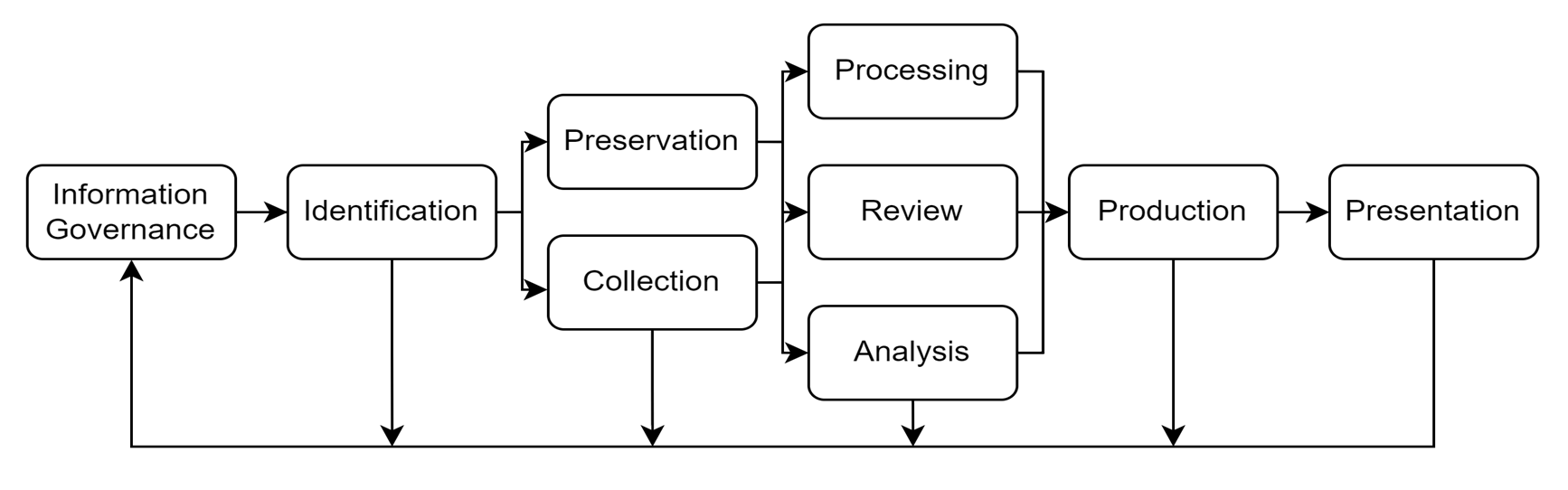
2005년, e-Discovery에 대한 표준과 가이드라인을 제공하기 위해서 EDRM 프로젝트가 착수되었으며, 현재 EDRM은 미국의 다양한 e-Discovery 모델 중 가장 대표적이며 e-Discovery 제품과 서비스를 개발, 선택, 평가하고 사용하기 위해 실행 가능한 프레임워크로 인정받고 있습니다.
총 9단계로 구성되어 있으며, Information Governance에서 시작하여 Presentation까지 이어지는 흐름입니다.
여기서 가장 중요하게 이해해야 할 점은, 이 모델이 단순한 선형 프로세스가 아니라는 것입니다.
반복적이고 재귀적인 구조로, 프로젝트 상황에 따라 반복되거나 병행될 수 있다는 것입니다.
예를 들어 Collection 단계에서 새로운 Custodian 이 발견되면 Identification 단계로 돌아가야 하고,
Processing 단계에서 데이터 오류가 확인되면 수집을 다시 진행해야 하는 경우도 생깁니다.
이때에 두 가지 핵심 원칙이 전체 절차를 관통합니다.
첫째는 법적 방어성, Defensibility입니다.
어떤 방법으로 데이터를 수집하고 보존했느냐가 최종 결과물의 증거 능력을 결정합니다.
둘째는 비례성, Proportionality입니다.
수집 범위는 사건의 중요성·분쟁 금액·당사자 자원·발견의 부담과 이익 등을 종합적으로 고려한 비례성 원칙을 충족해야 하며, 과도한 수집은 오히려 비용과 리스크를 높입니다.
1단계 Information Govenance는 소송이 발생하기 전, 평상시의 데이터 관리 체계를 말합니다.
기업이 어떤 데이터를 어디에 얼마나 보관하고, 언제 폐기할 것인지에 대한 정책입니다.
데이터 보존 정책, 삭제 일정, 데이터 맵을 사전에 갖추고 있어야 eDiscovery가 시작되었을 때 어디서 무엇을 찾아야 하는지 즉시 파악할 수 있습니다.
이 단계가 잘 되어 있으면 나중에 소송이 터졌을 때 대응 시간과 비용이 크게 줄어듭니다.
2단계 Identification은 소송이나 조사가 시작되면, 관련된 데이터가 어디에 있는지 파악합니다.
누구의 이메일인지, 어떤 서버에 있는지, 기간은 언제부터 언제까지인지.
이 단계에서 Custodian, 즉 데이터 보유자를 특정하고 데이터의 범위를 정합니다.
기업 내부 시스템, 클라우드, 모바일, 제3자 데이터까지 범위를 확정해야 합니다.
보유자 인터뷰와 IT 데이터 맵이 핵심 도구입니다.
3단계 Preservation은 소송이 합리적으로 예상되는 시점부터 즉각 발동되어야 합니다.
Legal Hold 통지를 발행하여 관련자들에게 '이 데이터를 절대 삭제하지 마십시오'라고 알립니다.
이를 이행하지 않으면 Spoliation, 즉 증거인멸로 간주되어 법적 제재를 받을 수 있습니다.
Spoliation 제재는 데이터를 고의로 삭제한 경우뿐 아니라 보존 의무를 소홀히 한 해태 및 과실에도 적용되기 때문입니다.
4단계 Collection은 실제로 데이터를 수집하는 단계입니다.
여기서 디지털 포렌식 기술이 핵심적으로 사용됩니다.
EnCase나 FTK 같은 도구로 디스크 이미지를 떠서 원본과 동일한 사본을 만들고, 해시값을 생성하여 무결성을 증명합니다.
Chain of Custody 문서를 작성하여 증거의 이동 경로를 모두 기록합니다.
5단계 Processing는 수집된 데이터를 리뷰 가능한 형태로 가공합니다.
구체적으로는 압축 해제, 텍스트 추출, 중복 제거(De-duplication), 메타데이터 인덱싱,
그리고 날짜·키워드·파일 유형 기반 필터링(Culling)을 수행합니다.
이 단계에서는 Nuix라는 프로세싱 도구를 활용합니다.
테라바이트 단위의 데이터도 효율적으로 처리할 수 있습니다.
6단계 Review는 전체 프로세스 중 가장 시간과 비용이 많이 드는 단계입니다.
리뷰어들이 문서 하나하나를 보면서 관련성이 있는지, 변호사-의뢰인 특권(Privilege)에 해당하는지 판단합니다.
이때에 Relativity 플랫폼을 활용하며,
최근에는 TAR, 즉 Technology Assisted Review를 도입하여 AI가 관련 문서를 자동 분류함으로써 리뷰 속도와 정확도를 동시에 높이고 있습니다.
7단계 Analysis는 단순 분류를 넘어 커뮤니케이션 패턴, 타임라인, 인물 관계도 등을 분석합니다.
키워드 분석, 이메일 스레드 재구성, 타임라인 작성을 통해 데이터 속에서 사실관계를 도출합니다.
기업 부정조사에서는 커뮤니케이션 패턴과 데이터 흐름에서 은폐 행위를 찾아내는 것이 핵심입니다.
이 단계에서 사건의 전체 그림이 드러나며, 소송 전략 수립에 직접 기여합니다.
8단계 Production은 최종적으로 상대방이나 법원에 제출할 형식으로 문서를 생산합니다.
TIFF 이미지나 PDF 형태로 변환하고, 베이츠 넘버링을 부여하며,
특권 문서는 제외하고 로그를 작성합니다.
9단계 Presentation은 법정이나 청문회에서 수집·분석한 증거를 효과적으로 제시하는 단계입니다.
시각화 자료와 타임라인을 활용하여 복잡한 사실관계를 이해하기 쉽게 전달합니다.
다음은 eDiscovery 실무에서 활용되는 핵심 도구와 기술을 정리해 보았습니다.
Collection 단계에서는 EnCase, FTK와 같은 포렌식 이미징 도구가 사용되고, 모바일 기기의 경우 Cellebrite UFED 등이 활용됩니다.
Proessing 단계에서는 Nuix Workstation이 대표적입니다. 수백 가지 파일 포맷을 처리하고 인덱싱할 수 있습니다.
Review, Analysis 단계에서는 Relativity가 업계 표준입니다. 여기에 TAR/Predictive Coding 기능을 결합하면 수백만 건의 문서도 효율적으로 분류할 수 있습니다.
그리고 이러한 도구들을 보완하기 위해 Python이나 SQL을 활용한 커스텀 데이터 분석, 자동화 스크립트 개발도 실무에서 중요한 역할을 합니다.
현재 글로벌 eDiscovery 시장은 빠르게 성장하고 있습니다. The Business Research Company의 2026년 3월 보고서에 따르면, 2025년 약 151억 달러에서 2026년 약 167억 달러로 높은 성장률을 기록하고 있으며, 2030년에는 250억 달러를 넘을 것으로 전망됩니다.
2026년의 핵심 트렌드 세 가지는 다음과 같습니다.
첫째, 생성형 AI와 TAR의 고도화입니다.
단순히 문서 분류를 넘어, NavigAite를 통해 수백만 건의 데이터를 신속하게 요약하고 핵심 리스크를 식별합니다.
둘째, 컴플라이언스와 효율성을 동시에 충족하는 클라우드 기반 하이브리드 아키텍처의 도입입니다.
eDiscovery 대상인 ESI(전자저장정보)의 볼륨이 페타바이트급으로 폭증하고 있습니다. 이에 따라, 데이터 주권과 엄격한 보안 규제를 적용받는 민감 데이터는 온프레미스에서 안전하게 통제하고, 대규모 텍스트 분석 및 생성형 AI 모델 구동은 클라우드의 탄력적 인프라를 활용해 고속 처리하는 하이브리드 대응 능력이 포렌식 실무자의 핵심 역량으로 자리 잡고 있습니다.
셋째, Cross-border 규제 복잡성 증가입니다.
GDPR 시행 이후 각국의 데이터 현지화 요구가 강화되면서, 글로벌 네트워크를 갖춘 펌의 경쟁력이 더욱 부각됩니다.
Reference
- The Consilio Guide to eDiscovery_Digital Copy_6-23-25_Compressed.pdf
- https://www.lextrado.com/2022/04/13/the-edrm-model-and-why-it-is-important/
- 그 외 다수 기업의 공식 홈페이지
- 생성형 AI 등
취준하면서 공부한 내용을 정리했습니다.
