
1. Introduction to Collections
Collection
- 정의 : 객체 그룹을 저장하고 조작할 수 있는 아키텍쳐를 제공하는 Java의 프레임워크
- Java Standard Library에서 제공해주는 기능. 미리 구현이 되어 있음
- 장점
- Standardization : 같은 컬렉션 안에 있는 구조들은 비슷한 Operation을 구현
- Reusability : 재사용 가능한 자료구조와 알고리즘 제공
Key Components
- Interface
- 구현하는 기능들에 대한 설명
- ex)
List: 중복이 허용되는 순서가 있는 구조Set: 중복이 허용되지 않는 구조Map: key, value 쌍이 있고, key 값이 중복되지 않는 구조
- Implementations
- 인터페이스가 실제로 구현된 클래스들. 실제 기능을 제공
- ex)
ArrayList: List를 implement 하는 크기 조정 가능한 배열HashSet: Set을 implement 하는 순서를 저장하지 않는 해시 테이블HashMap: Map을 implement 하는 null key 와 null value를 허용하는 해시 테이블
- Algorithms
- 컬렉션들에서 공통적인 operation을 수행하는 메소드
- Sort, Search, Shuffle 등등.
2. Interfaces
List Interface
- 요소간 중복이 허용되는 순서 있는 구조
ArrayList
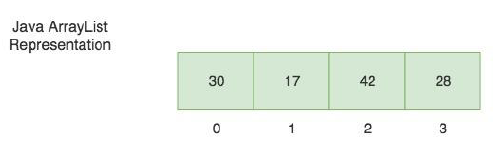
- 크기 조정 가능한 배열, 필요한 만큼 크기를 늘릴 수 있다.
- index를 통한 접근 속도가 빠르다 → O(1)
- 데이터 추가 / 삭제 속도가 느리다 → O(n)
- 중복 허용, null value 허용
→ 잘 변하지 않는 list에 사용한다.
LinkedList
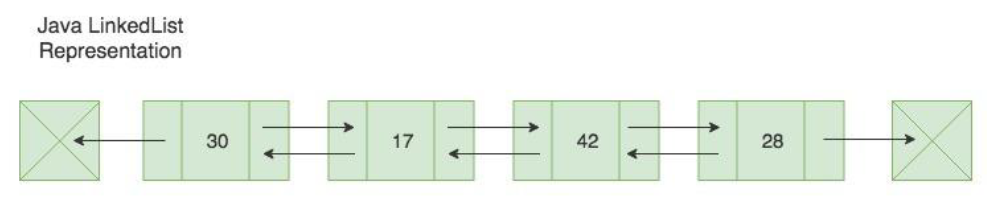
List와Deque를 모두 implement 하는 구조- index를 통한 접근 속도가 느리다 → O(n)
- 데이터 추가 / 삭제 속도가 빠르다 → O(1)
- 중복 허용, null value 허용
- Queue(FIFO) 나 Stack(LIFO) 로 사용 가능
→ 데이터의 추가 & 삭제가 빈번한 list에 사용한다.
import java.util.LinkedList;
public class Example {
public static void main(String args[]) {
LinkedList<Integer> numbers = new LinkedList<>();
// Adding elements
numbers.add(10);
numbers.add(20);
numbers.add(30);
// Accessing elements
System.out.println("First element: " + numbers.getFisrt());
// Removing elements
numbers.removeFirst();
// Size of the list
System.out.println("Size of list: " + numbers.size());
// Iterating over the list
for (Integer number : numbers) {
System.out.println(number);
}
}
}Set Interface
- 요소간 중복이 허용되지 않는 순서 없는 구조
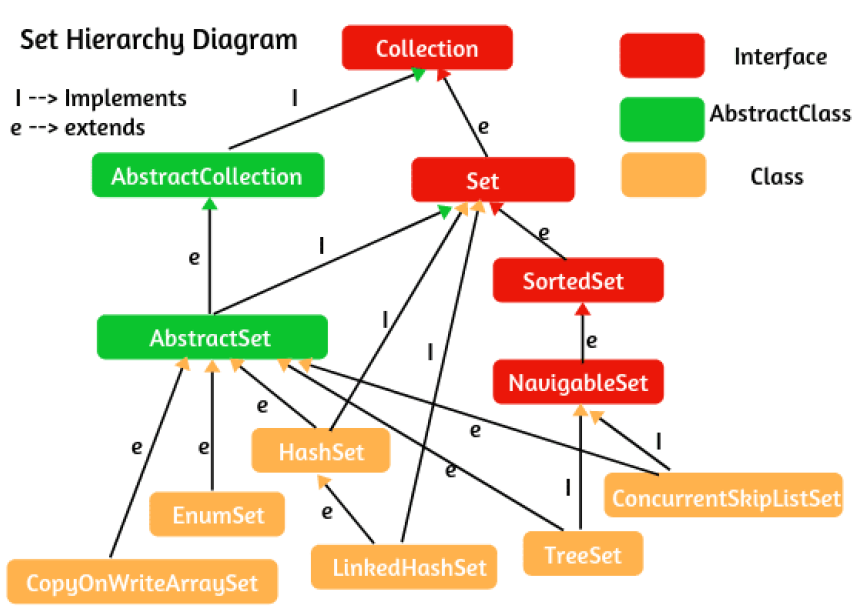
HashSet
Set을 구현, hash table의 백업을 받음- null 값을 허용
- add(), remove(), contains() 에 대한 시간 복잡도 O(1)
→ 순서가 상관 없고, 빠른 접근이 필요할 때 사용
import java.util.HashSet;
public class Example {
public static void main(String args[]) {
HashSet<String> set = new HashSet<>();
// Adding elements
set.add("Dog");
set.add("Cat");
set.add("Bird");
set.add("Dog"); // 중복 요소, 추가되지 않음
// Checking if an element exists
System.out.println("Contains 'Cat': " + set.contains("Cat"));
// Size of the set
System.out.println("Size of set: " + set.size());
// Iterating over the set
for (String animal : set) {
System.out.println(animal);
}
}
}LinkedHashSet
Set을 구현, hash table 과 linked list의 백업을 받음HashSet을 상속 받음. Double Linked List 유지- 요소의 삽입 순서를 유지한다
- 기본적 Operation에 대한 시간 복잡도 O(1)
- null 값 허용
→ 중복 불가 & 삽입 순서 유지가 필요할 때 사용
TreeSet
SortedSet을 상속하는NavigableSet을 구현- red-black tree 의 백업을 받음
- 요소들을 key 기준으로 정렬 (오름차순 / 커스텀 가능)
- null 값 허용 X
- add(), remove(), contains() 에 대한 시간 복잡도 O(log n)
→ 정렬된 Set 이 필요할 때 사용
Map<integer, String> treeMap = new TreeMap<>();
treeMap.put(3, "Three");
treeMap.put(1, "One");
treeMap.put(2, "Two");
System.out.println(treeMap); // key 순으로 정렬 : {1=One, 2=Two, 3=Three}Map Interface
- Key - Value 의 쌍을 가지는 구조. 1개의 key에 1개의 Value mapping
- Key 값의 중복을 허용하지 않는다.
HashMap
Map을 구현, hash table의 백업을 받음- 1개의 null key 와 여러 개의 null value 허용 (나머지 케이스들을 모두 저장하는 곳)
- key / value 의 순서 저장 X
- put(), get() 에 대한 시간 복잡도 O(1)
→ 순서 상관없이 빠른 접근이 필요할 때 사용
LinkedHashMap
HashMap상속 받음. Double Linked List 유지- 1개의 null key 와 여러 개의 null value 허용
- 기본적 Operation에 대한 시간 복잡도 O(1)
- 순서가 예상 가능하다(넣은 순서)
→ 넣은 순서 유지가 필요할 때 사용
TreeMap
NavigableMap구현, red-black tree 의 백업 받음- key가 정렬됨. (오름차순 / 커스텀)
- null key 허용 X (throws
NullPointerException) - 기본적 Operation에 대한 시간 복잡도 O(log n)
→ key를 정렬해야할 때 사용
3. Iterator
Definition
- 어떤 collection 이든 공통적으로 구현하는 것들
- 장점
- Uniform access : 모든 collection에 대해 똑같은 방식으로 접근할 수 있도록 함
- Encapsulation : 어떤 collection인지 감춰 실수로 바꾸는 것을 막을 수 있음
Types of Iterators
hasNext(): 다음 요소가 존재하면 true 반환 (전체 요소 순회 시 사용)next(): 다음 요소를 반환remove(): 마지막으로 반환된 요소를 삭제
List<String> list = new ArrayList<>(Arrays.asList("A", "B", "C"));
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
System.out.println(element);
}4. Using Collections for Data Manipulation
Sorting
Collections.sort()- 요소들을 natural ordering 에 기반해 정렬 (알파벳 순, 대문자 > 소문자)
List<String> list = Arrays.asList("Banana", "Apple", "Cherry"); Collections.sort(list); // Apple, Banana, Cherry 순으로 정렬
List.sort()- list 인터페이스에 있는 기본적 메소드
list.sort(Comparator.naturalOrder());
Arrays.sort()- array의 요소들을 오름차순으로 정렬
int[] numbers = {4, 2, 7, 3}; Arrays.sort(numbers); // 2, 3, 4, 7 순으로 정렬
Custom Sorting
Comparator인터페이스- comparator(T o1, T o2) 메소드를 제공하는 함수형 인터페이스
Collections.sort(list, Comparator.reverseOrder());- 함수 자체에서 입력값 두 개를 비교하기 위해 사용 → 입력값 2개
Comparable인터페이스- 객체의 값과 다른 객체 입력값 1개를 비교하기 위해 사용 → 입력값 1개
public class Person implements Comparable<Person> { private String name; private int age; // getters, setters, constructor @Override public int comPareTo(person other) { return Integer.compare(this.age), other.age); } }
Searching
-
Collection.binarySearch()- 이진 탐색 알고리즘을 사용해 탐색
int index = Collections.binarySearch(list, "Apple");
-
Map.containsKey()- map 이 특정한 key 값을 가지고 있다면 true 반환
-
List.contains()- list 가 특정한 요소를 가지고 있다면 true 반환
-
탐색의 시간 복잡도는 어떤 자료 구조를 사용하는지에 따라 달라진다.

컴공 대학생의 공부기록